
Add top-of-page benchmark figure
Browse files
README.md
CHANGED
|
@@ -96,6 +96,8 @@ It supports Chinese-English image-text retrieval, zero-shot image classification
|
|
| 96 |
|
| 97 |
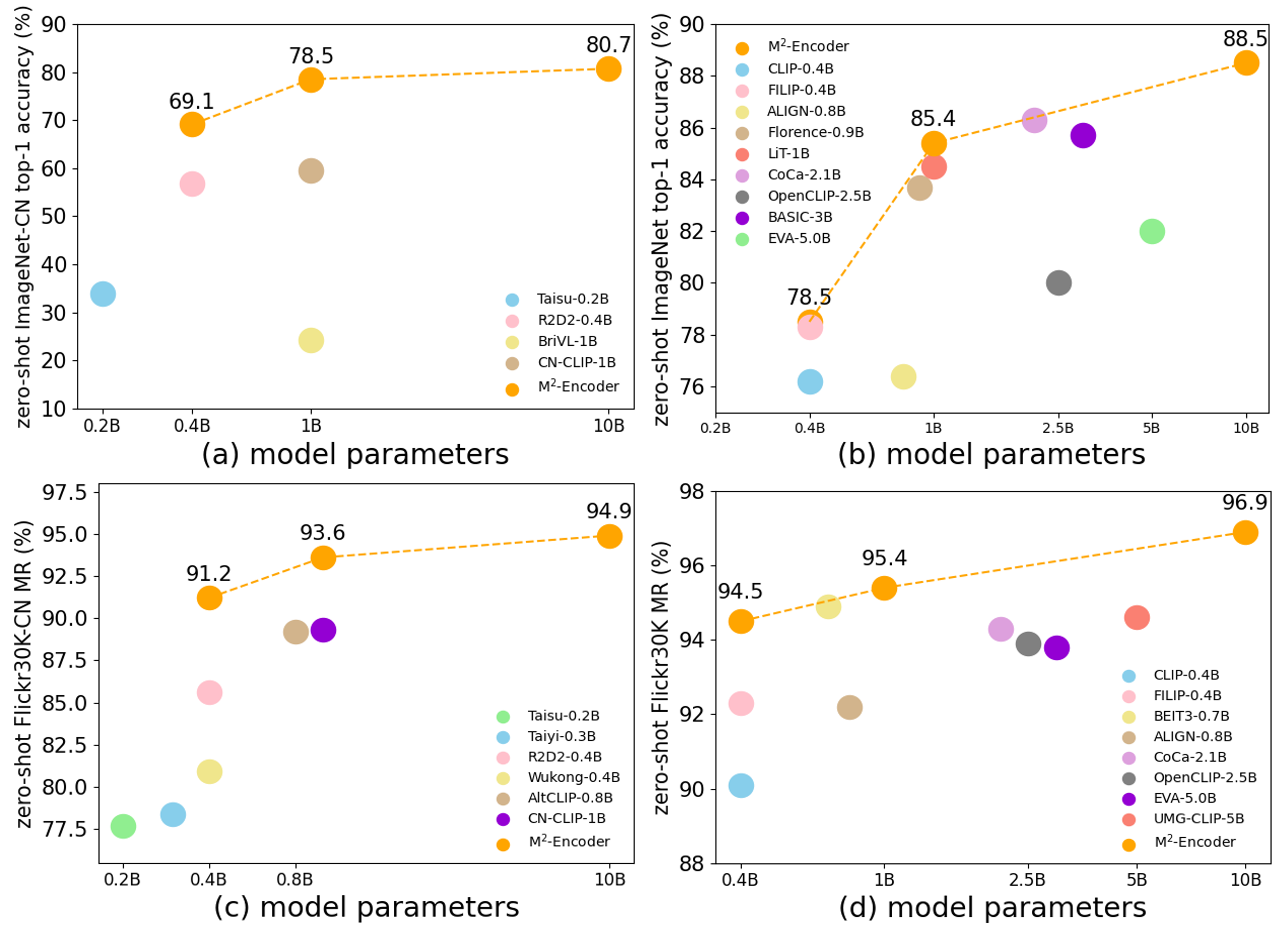
This is the larger M2-Encoder variant with a wider backbone and 1024-dimensional embeddings, intended for better retrieval and zero-shot classification quality.
|
| 98 |
|
|
|
|
|
|
|
| 99 |
## Links
|
| 100 |
|
| 101 |
- Paper: https://arxiv.org/abs/2401.15896
|
|
|
|
| 96 |
|
| 97 |
This is the larger M2-Encoder variant with a wider backbone and 1024-dimensional embeddings, intended for better retrieval and zero-shot classification quality.
|
| 98 |
|
| 99 |
+
|
| 100 |
+
|
| 101 |
## Links
|
| 102 |
|
| 103 |
- Paper: https://arxiv.org/abs/2401.15896
|