
html_url stringlengths 48 51 | title stringlengths 5 268 | comments stringlengths 63 51.8k | body stringlengths 0 36.2k ⌀ | comment_length int64 16 1.52k | text stringlengths 164 54.1k | embeddings list |
|---|---|---|---|---|---|---|
https://github.com/huggingface/datasets/issues/222 | Colab Notebook breaks when downloading the squad dataset | When you install `nlp` for the first time on a Colab runtime, it updates the `pyarrow` library that was already on colab. This update shows this message on colab:
```
WARNING: The following packages were previously imported in this runtime:
[pyarrow]
You must restart the runtime in order to use newly installed ve... | When I run the notebook in Colab
https://colab.research.google.com/github/huggingface/nlp/blob/master/notebooks/Overview.ipynb
breaks when running this cell:
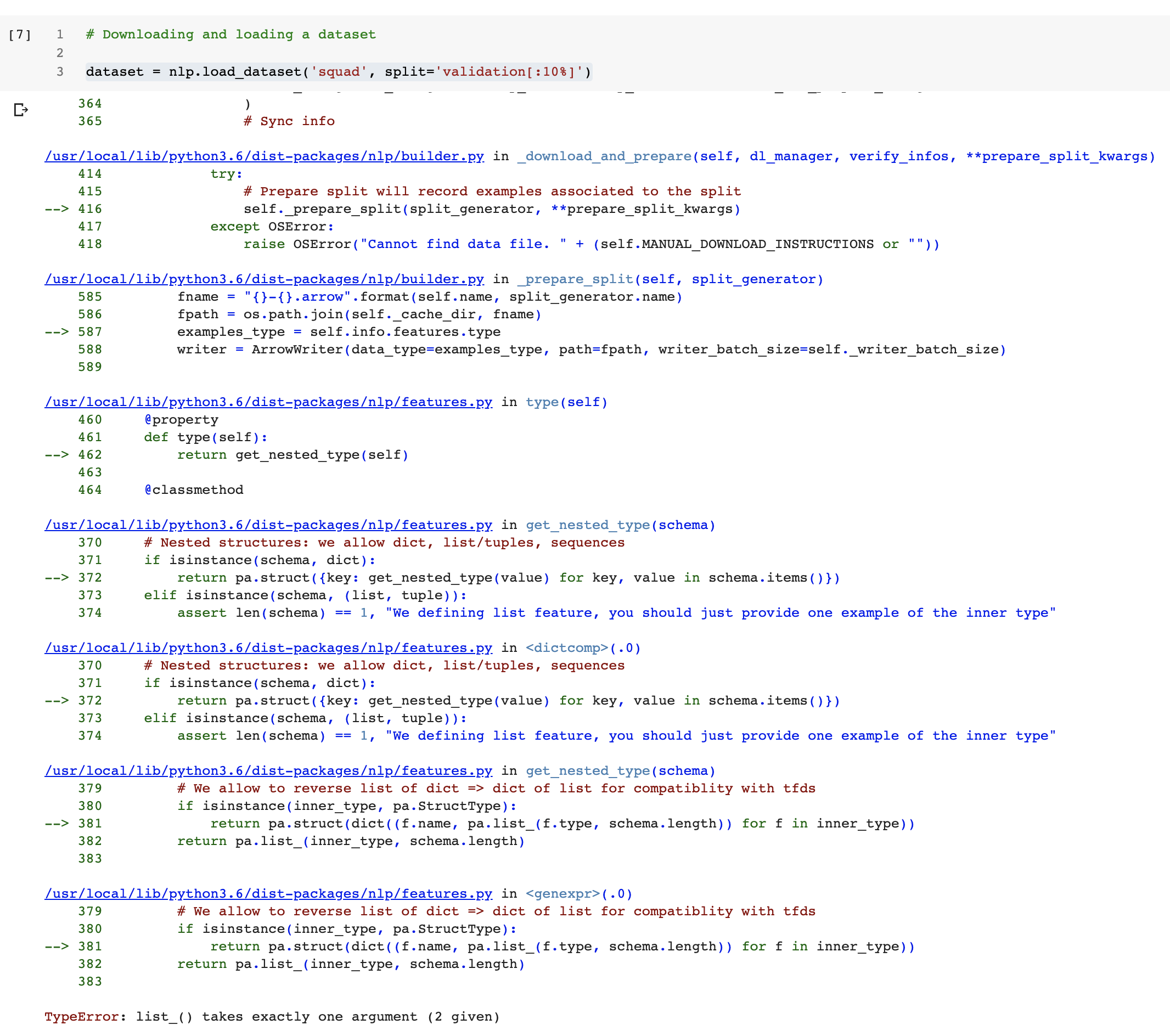
| 78 | Colab Notebook breaks when downloading the squad dataset
When I run the notebook in Colab
https://colab.research.google.com/github/huggingface/nlp/blob/master/notebooks/Overview.ipynb
breaks when running this cell:
 | When I run the notebook in Colab
https://colab.research.google.com/github/huggingface/nlp/blob/master/notebooks/Overview.ipynb
breaks when running this cell:

| 16 | Colab Notebook breaks when downloading the squad dataset
When I run the notebook in Colab
https://colab.research.google.com/github/huggingface/nlp/blob/master/notebooks/Overview.ipynb
breaks when running this cell:

| 60 | Colab Notebook breaks when downloading the squad dataset
When I run the notebook in Colab
https://colab.research.google.com/github/huggingface/nlp/blob/master/notebooks/Overview.ipynb
breaks when running this cell:
.
The [T5 paper](https://arxiv.org/pdf/1910.10683.pdf) highlights multiple ways of mixing the tasks together during finetuning:
- **Examples-proportional mixing** - sam... | 291 | Multi-task dataset mixing
It seems like many of the best performing models on the GLUE benchmark make some use of multitask learning (simultaneous training on multiple tasks).
The [T5 paper](https://arxiv.org/pdf/1910.10683.pdf) highlights multiple ways of mixing the tasks together during finetuning:
- **Examples... | [
-0.0606289096,
-0.4335703552,
-0.0566291288,
-0.0154860923,
-0.1655909568,
0.0452479236,
0.1855864078,
0.1840498894,
0.2041600645,
-0.1490787417,
-0.2486170083,
0.2844126821,
-0.1800079048,
0.4715520442,
0.3802835047,
-0.4318715334,
0.0726253986,
-0.1483573616,
-0.3279533982,
0... |
https://github.com/huggingface/datasets/issues/217 | Multi-task dataset mixing | I agree that we should leave the flattening of the dataset to the user for now. Especially because although the T5 framing seems obvious, there are slight variations on how the T5 authors do it in comparison to other approaches such as gpt-3 and decaNLP.
In terms of sampling, Examples-proportional mixing does seem t... | It seems like many of the best performing models on the GLUE benchmark make some use of multitask learning (simultaneous training on multiple tasks).
The [T5 paper](https://arxiv.org/pdf/1910.10683.pdf) highlights multiple ways of mixing the tasks together during finetuning:
- **Examples-proportional mixing** - sam... | 126 | Multi-task dataset mixing
It seems like many of the best performing models on the GLUE benchmark make some use of multitask learning (simultaneous training on multiple tasks).
The [T5 paper](https://arxiv.org/pdf/1910.10683.pdf) highlights multiple ways of mixing the tasks together during finetuning:
- **Examples... | [
-0.0724449679,
-0.4672179818,
-0.0401601717,
-0.0550320148,
-0.3045601249,
0.0747442916,
0.174433887,
0.0672956333,
0.2653245032,
-0.1193469539,
-0.2597550452,
0.3054887652,
-0.1694985777,
0.3780531883,
0.3509475291,
-0.4499821663,
-0.0215498675,
-0.146344319,
-0.2921185791,
0.... |
https://github.com/huggingface/datasets/issues/217 | Multi-task dataset mixing | I agree with going with temperature-scaled mixing for its flexibility!
For the function that combines the datasets, I also find `dataset.add()` okay while also considering that users may want it to be easy to combine a list of say 10 data sources in one go.
`dataset.sample()` should also be good. By the looks of ... | It seems like many of the best performing models on the GLUE benchmark make some use of multitask learning (simultaneous training on multiple tasks).
The [T5 paper](https://arxiv.org/pdf/1910.10683.pdf) highlights multiple ways of mixing the tasks together during finetuning:
- **Examples-proportional mixing** - sam... | 125 | Multi-task dataset mixing
It seems like many of the best performing models on the GLUE benchmark make some use of multitask learning (simultaneous training on multiple tasks).
The [T5 paper](https://arxiv.org/pdf/1910.10683.pdf) highlights multiple ways of mixing the tasks together during finetuning:
- **Examples... | [
-0.0916314498,
-0.4211592078,
-0.0451325178,
-0.0800990611,
-0.2404672652,
0.0590448119,
0.1587895304,
0.0534609631,
0.3097866774,
-0.1581769735,
-0.2333139926,
0.3175207973,
-0.192758739,
0.3524591327,
0.4201159179,
-0.4721604288,
0.0277890246,
-0.2041646242,
-0.3079894185,
0.... |
https://github.com/huggingface/datasets/issues/217 | Multi-task dataset mixing | This is an interesting discussion indeed and it would be nice to make multi-task easier.
Probably the best would be to have a new type of dataset especially designed for that in order to easily combine and sample from the multiple datasets.
This way we could probably handle the combination of datasets with differ... | It seems like many of the best performing models on the GLUE benchmark make some use of multitask learning (simultaneous training on multiple tasks).
The [T5 paper](https://arxiv.org/pdf/1910.10683.pdf) highlights multiple ways of mixing the tasks together during finetuning:
- **Examples-proportional mixing** - sam... | 59 | Multi-task dataset mixing
It seems like many of the best performing models on the GLUE benchmark make some use of multitask learning (simultaneous training on multiple tasks).
The [T5 paper](https://arxiv.org/pdf/1910.10683.pdf) highlights multiple ways of mixing the tasks together during finetuning:
- **Examples... | [
-0.077604875,
-0.4301361144,
-0.0512810796,
-0.0076483325,
-0.2415289581,
0.1148417145,
0.1743366122,
0.0923100784,
0.2852178216,
-0.1179620624,
-0.243736282,
0.2735092342,
-0.1946440041,
0.4169623256,
0.3982005119,
-0.4560343921,
0.0079969987,
-0.2196667343,
-0.2606220543,
0.3... |
https://github.com/huggingface/datasets/issues/217 | Multi-task dataset mixing | @thomwolf Are you suggesting making a wrapper class which can take existing datasets as arguments and do all the required sampling/combining, to present the same interface as a normal dataset?
That doesn't seem too complicated to implement.
| It seems like many of the best performing models on the GLUE benchmark make some use of multitask learning (simultaneous training on multiple tasks).
The [T5 paper](https://arxiv.org/pdf/1910.10683.pdf) highlights multiple ways of mixing the tasks together during finetuning:
- **Examples-proportional mixing** - sam... | 37 | Multi-task dataset mixing
It seems like many of the best performing models on the GLUE benchmark make some use of multitask learning (simultaneous training on multiple tasks).
The [T5 paper](https://arxiv.org/pdf/1910.10683.pdf) highlights multiple ways of mixing the tasks together during finetuning:
- **Examples... | [
-0.089850992,
-0.3969320655,
-0.0316653773,
-0.0373522975,
-0.2264487594,
0.0873820335,
0.1969548166,
0.0660230815,
0.3327302933,
-0.13962093,
-0.226148352,
0.3318240047,
-0.2025054395,
0.3645177186,
0.4015562832,
-0.5019190907,
-0.0090313293,
-0.1732094437,
-0.3404359818,
0.34... |
https://github.com/huggingface/datasets/issues/217 | Multi-task dataset mixing | I guess we're looking at the end user writing something like:
``` python
ds = nlp.load_dataset('multitask-t5',datasets=["squad","cnn_dm",...], k=1000, t=2.0)
```
Using the t5 method of combining here (or this could be a function passed in as an arg)
Passing kwargs to each 'sub-dataset' might become tricky. | It seems like many of the best performing models on the GLUE benchmark make some use of multitask learning (simultaneous training on multiple tasks).
The [T5 paper](https://arxiv.org/pdf/1910.10683.pdf) highlights multiple ways of mixing the tasks together during finetuning:
- **Examples-proportional mixing** - sam... | 45 | Multi-task dataset mixing
It seems like many of the best performing models on the GLUE benchmark make some use of multitask learning (simultaneous training on multiple tasks).
The [T5 paper](https://arxiv.org/pdf/1910.10683.pdf) highlights multiple ways of mixing the tasks together during finetuning:
- **Examples... | [
-0.0292877015,
-0.3940441906,
-0.0610293709,
-0.0256625023,
-0.2608689964,
0.0825808272,
0.1810527146,
0.04695585,
0.2868430614,
-0.1594539285,
-0.2330444455,
0.3090502918,
-0.2074716687,
0.3853416145,
0.3700455129,
-0.4468322694,
-0.0071449904,
-0.2071920186,
-0.2622185946,
0.... |
https://github.com/huggingface/datasets/issues/217 | Multi-task dataset mixing | From thinking upon @thomwolf 's suggestion, I've started experimenting:
```python
class MultitaskDataset(DatasetBuilder):
def __init__(self, *args, **kwargs):
super(MultitaskDataset, self).__init__(*args, **kwargs)
self._datasets = kwargs.get("datasets")
def _info(self):
return ... | It seems like many of the best performing models on the GLUE benchmark make some use of multitask learning (simultaneous training on multiple tasks).
The [T5 paper](https://arxiv.org/pdf/1910.10683.pdf) highlights multiple ways of mixing the tasks together during finetuning:
- **Examples-proportional mixing** - sam... | 177 | Multi-task dataset mixing
It seems like many of the best performing models on the GLUE benchmark make some use of multitask learning (simultaneous training on multiple tasks).
The [T5 paper](https://arxiv.org/pdf/1910.10683.pdf) highlights multiple ways of mixing the tasks together during finetuning:
- **Examples... | [
-0.041028887,
-0.380012989,
-0.0561358891,
-0.055333823,
-0.22696127,
0.0381449945,
0.1911633015,
0.0285417903,
0.3140306473,
-0.1693239808,
-0.2113296688,
0.322681427,
-0.2117783725,
0.3609279692,
0.4108112752,
-0.4081550241,
0.0496115535,
-0.2385493666,
-0.3018547297,
0.38168... |
https://github.com/huggingface/datasets/issues/217 | Multi-task dataset mixing | I think I would probably go for a `MultiDataset` wrapper around a list of `Dataset`.
I'm not sure we need to give it `k` and `t` parameters at creation, it can maybe be something along the lines of:
```python
squad = nlp.load_dataset("squad")
cnn_dm = nlp.load_dataset("cnn_dailymail","3.0.0")
multitask_dataset... | It seems like many of the best performing models on the GLUE benchmark make some use of multitask learning (simultaneous training on multiple tasks).
The [T5 paper](https://arxiv.org/pdf/1910.10683.pdf) highlights multiple ways of mixing the tasks together during finetuning:
- **Examples-proportional mixing** - sam... | 114 | Multi-task dataset mixing
It seems like many of the best performing models on the GLUE benchmark make some use of multitask learning (simultaneous training on multiple tasks).
The [T5 paper](https://arxiv.org/pdf/1910.10683.pdf) highlights multiple ways of mixing the tasks together during finetuning:
- **Examples... | [
-0.0309595913,
-0.4186732471,
-0.0396580212,
-0.0468708351,
-0.2247026861,
0.0937635452,
0.1678376347,
0.0375865772,
0.2795367539,
-0.1670988202,
-0.2208787799,
0.3342228234,
-0.2148639113,
0.3291553557,
0.4196425378,
-0.4405978918,
0.0240546316,
-0.2191531211,
-0.2579801381,
0... |
https://github.com/huggingface/datasets/issues/217 | Multi-task dataset mixing | The problem with changing `k` and `t` per sampling is that you'd have to somehow remember which examples you'd already returned while re-weighting the remaining examples based on the new `k` and `t`values. It seems possible but complicated (I can't really see a reason why you'd want to change the weighting of datasets ... | It seems like many of the best performing models on the GLUE benchmark make some use of multitask learning (simultaneous training on multiple tasks).
The [T5 paper](https://arxiv.org/pdf/1910.10683.pdf) highlights multiple ways of mixing the tasks together during finetuning:
- **Examples-proportional mixing** - sam... | 109 | Multi-task dataset mixing
It seems like many of the best performing models on the GLUE benchmark make some use of multitask learning (simultaneous training on multiple tasks).
The [T5 paper](https://arxiv.org/pdf/1910.10683.pdf) highlights multiple ways of mixing the tasks together during finetuning:
- **Examples... | [
-0.0834358335,
-0.3772906363,
-0.054012198,
-0.0832781196,
-0.2122468054,
0.0169448685,
0.1334996074,
0.0681639388,
0.3124586642,
-0.0252598487,
-0.2377851307,
0.3599813879,
-0.1587046534,
0.349779278,
0.3823591173,
-0.4798977971,
-0.0307444856,
-0.1330459565,
-0.3688009083,
0.... |
https://github.com/huggingface/datasets/issues/217 | Multi-task dataset mixing | A very janky (but working) implementation of `multitask_dataset.sample()` could be something like this:
```python
import nlp
import torch
class MultiDataset():
def __init__(self, *args, temperature=2.0, k=1000, maximum=None, scale=1):
self.datasets = args
self._dataloaders = {}
fo... | It seems like many of the best performing models on the GLUE benchmark make some use of multitask learning (simultaneous training on multiple tasks).
The [T5 paper](https://arxiv.org/pdf/1910.10683.pdf) highlights multiple ways of mixing the tasks together during finetuning:
- **Examples-proportional mixing** - sam... | 231 | Multi-task dataset mixing
It seems like many of the best performing models on the GLUE benchmark make some use of multitask learning (simultaneous training on multiple tasks).
The [T5 paper](https://arxiv.org/pdf/1910.10683.pdf) highlights multiple ways of mixing the tasks together during finetuning:
- **Examples... | [
-0.0834201127,
-0.388119638,
-0.0588923432,
-0.0579487234,
-0.2545420527,
0.0694044679,
0.194930926,
0.0514101945,
0.3405599892,
-0.148264572,
-0.2024352849,
0.371730864,
-0.2394477427,
0.3475410044,
0.387298286,
-0.4599962234,
0.0241374988,
-0.267570138,
-0.269878149,
0.372872... |
https://github.com/huggingface/datasets/issues/217 | Multi-task dataset mixing | Good spot! Here are my thoughts:
- Aside: Adding `MultitaskModel` to transformers might be a thing to raise - even though having task-specific heads has become unfashionable in recent times in favour of text-to-text type models.
- Adding the task name as an extra field also seems useful for these kind of models whi... | It seems like many of the best performing models on the GLUE benchmark make some use of multitask learning (simultaneous training on multiple tasks).
The [T5 paper](https://arxiv.org/pdf/1910.10683.pdf) highlights multiple ways of mixing the tasks together during finetuning:
- **Examples-proportional mixing** - sam... | 264 | Multi-task dataset mixing
It seems like many of the best performing models on the GLUE benchmark make some use of multitask learning (simultaneous training on multiple tasks).
The [T5 paper](https://arxiv.org/pdf/1910.10683.pdf) highlights multiple ways of mixing the tasks together during finetuning:
- **Examples... | [
-0.005269621,
-0.4564428031,
-0.0409008935,
-0.0331542976,
-0.2421440184,
0.0899885446,
0.226267904,
0.0337932482,
0.3455824852,
-0.1832487285,
-0.1746235043,
0.2782375813,
-0.2171299756,
0.3147795498,
0.3954235911,
-0.4474585652,
0.0529760867,
-0.2687867582,
-0.2423506379,
0.3... |
https://github.com/huggingface/datasets/issues/217 | Multi-task dataset mixing | Another thought: Multitasking over benchmarks (represented as Meta-datasets in nlp) is probably a common use case. Would be nice to pass an entire benchmark to our `MultiDataset` wrapper rather than having to pass individual components. | It seems like many of the best performing models on the GLUE benchmark make some use of multitask learning (simultaneous training on multiple tasks).
The [T5 paper](https://arxiv.org/pdf/1910.10683.pdf) highlights multiple ways of mixing the tasks together during finetuning:
- **Examples-proportional mixing** - sam... | 35 | Multi-task dataset mixing
It seems like many of the best performing models on the GLUE benchmark make some use of multitask learning (simultaneous training on multiple tasks).
The [T5 paper](https://arxiv.org/pdf/1910.10683.pdf) highlights multiple ways of mixing the tasks together during finetuning:
- **Examples... | [
-0.065611802,
-0.3723550439,
-0.0681931153,
-0.0492683314,
-0.2852722704,
0.1337663978,
0.2164803892,
0.1206524372,
0.3021679521,
-0.1421177983,
-0.1687693745,
0.3203652203,
-0.1637992114,
0.3486942947,
0.4185855687,
-0.4121802747,
0.0316882879,
-0.2107654512,
-0.2145605385,
0.... |
https://github.com/huggingface/datasets/issues/217 | Multi-task dataset mixing | Here's a fully working implementation based on the `__iter__` function of @zphang.
- I've generated the task choice list in the constructor as it allows us to index into the MultiDataset just like a normal dataset. I'm changing `task_choice_list` into a list of `(dataset_idx, example_idx)` so each entry references a... | It seems like many of the best performing models on the GLUE benchmark make some use of multitask learning (simultaneous training on multiple tasks).
The [T5 paper](https://arxiv.org/pdf/1910.10683.pdf) highlights multiple ways of mixing the tasks together during finetuning:
- **Examples-proportional mixing** - sam... | 469 | Multi-task dataset mixing
It seems like many of the best performing models on the GLUE benchmark make some use of multitask learning (simultaneous training on multiple tasks).
The [T5 paper](https://arxiv.org/pdf/1910.10683.pdf) highlights multiple ways of mixing the tasks together during finetuning:
- **Examples... | [
-0.0021333466,
-0.3933576941,
-0.0449089333,
0.0113292076,
-0.2239075601,
0.021761192,
0.1978978366,
0.0275363363,
0.4143024087,
-0.1978272051,
-0.2370708436,
0.3982106447,
-0.1945328414,
0.3028284609,
0.3515965939,
-0.4019325376,
-0.0221231375,
-0.241983071,
-0.2949596345,
0.3... |
https://github.com/huggingface/datasets/issues/217 | Multi-task dataset mixing | Hey! Happy to jump into the discussion here. I'm still getting familiar with bits of this code, but the reasons I sampled over data loaders rather than datasets is 1) ensuring that each sampled batch corresponds to only 1 task (in case of different inputs formats/downstream models) and 2) potentially having different b... | It seems like many of the best performing models on the GLUE benchmark make some use of multitask learning (simultaneous training on multiple tasks).
The [T5 paper](https://arxiv.org/pdf/1910.10683.pdf) highlights multiple ways of mixing the tasks together during finetuning:
- **Examples-proportional mixing** - sam... | 73 | Multi-task dataset mixing
It seems like many of the best performing models on the GLUE benchmark make some use of multitask learning (simultaneous training on multiple tasks).
The [T5 paper](https://arxiv.org/pdf/1910.10683.pdf) highlights multiple ways of mixing the tasks together during finetuning:
- **Examples... | [
-0.0896056741,
-0.3705180287,
-0.0441242047,
-0.0641978905,
-0.2286927998,
0.028950993,
0.2676899433,
0.0233600903,
0.3950953186,
-0.1093345061,
-0.1705918759,
0.3203356862,
-0.2015976012,
0.3754861355,
0.3984469473,
-0.4378176928,
-0.0025769623,
-0.255551964,
-0.3273432553,
0.... |
https://github.com/huggingface/datasets/issues/217 | Multi-task dataset mixing | The short answer is - I'm not! Everything is currently on a per-example basis. It would be fairly simple to add a `batch_size` argument which would ensure that every `batch_size` examples come from the same task. That should suit most use-cases (unless you wanted to ensure batches all came from the same task and apply ... | It seems like many of the best performing models on the GLUE benchmark make some use of multitask learning (simultaneous training on multiple tasks).
The [T5 paper](https://arxiv.org/pdf/1910.10683.pdf) highlights multiple ways of mixing the tasks together during finetuning:
- **Examples-proportional mixing** - sam... | 72 | Multi-task dataset mixing
It seems like many of the best performing models on the GLUE benchmark make some use of multitask learning (simultaneous training on multiple tasks).
The [T5 paper](https://arxiv.org/pdf/1910.10683.pdf) highlights multiple ways of mixing the tasks together during finetuning:
- **Examples... | [
-0.0956544578,
-0.4303837717,
-0.0462938733,
-0.0674508959,
-0.257894516,
0.009947381,
0.2022488266,
0.0762409121,
0.2903969288,
-0.1109249964,
-0.1859128624,
0.2946227491,
-0.2300932556,
0.3789541423,
0.4100241065,
-0.4520003498,
0.024441367,
-0.1772065312,
-0.2945500016,
0.36... |
https://github.com/huggingface/datasets/issues/217 | Multi-task dataset mixing | @zphang is having different batch sizes per task actually helpful? Would be interesting to know as it's not something I've come across as a technique used by any MTL papers. | It seems like many of the best performing models on the GLUE benchmark make some use of multitask learning (simultaneous training on multiple tasks).
The [T5 paper](https://arxiv.org/pdf/1910.10683.pdf) highlights multiple ways of mixing the tasks together during finetuning:
- **Examples-proportional mixing** - sam... | 30 | Multi-task dataset mixing
It seems like many of the best performing models on the GLUE benchmark make some use of multitask learning (simultaneous training on multiple tasks).
The [T5 paper](https://arxiv.org/pdf/1910.10683.pdf) highlights multiple ways of mixing the tasks together during finetuning:
- **Examples... | [
-0.0969290808,
-0.4622381032,
-0.0760455132,
0.0172498375,
-0.3047632575,
0.052864179,
0.2263211906,
0.0648956895,
0.2768974304,
-0.1179003939,
-0.1725134254,
0.2042180002,
-0.2584694624,
0.4444764853,
0.4080319405,
-0.4105130434,
0.0141270859,
-0.2733163238,
-0.2500167489,
0.3... |
https://github.com/huggingface/datasets/issues/217 | Multi-task dataset mixing | > @zphang is having different batch sizes per task actually helpful? Would be interesting to know as it's not something I've come across as a technique used by any MTL papers.
I think having different batch sizes per task is particularly helpful in some scenarios where each task has different amount of data. For exa... | It seems like many of the best performing models on the GLUE benchmark make some use of multitask learning (simultaneous training on multiple tasks).
The [T5 paper](https://arxiv.org/pdf/1910.10683.pdf) highlights multiple ways of mixing the tasks together during finetuning:
- **Examples-proportional mixing** - sam... | 108 | Multi-task dataset mixing
It seems like many of the best performing models on the GLUE benchmark make some use of multitask learning (simultaneous training on multiple tasks).
The [T5 paper](https://arxiv.org/pdf/1910.10683.pdf) highlights multiple ways of mixing the tasks together during finetuning:
- **Examples... | [
-0.152865991,
-0.4851085842,
-0.0882897303,
0.0438890643,
-0.3023049235,
0.0259209964,
0.2686053216,
0.0912453085,
0.2722302675,
-0.0741189197,
-0.1674393117,
0.1211871728,
-0.2572727501,
0.4499776959,
0.3634528518,
-0.4062093496,
0.0306341797,
-0.2730118036,
-0.228789553,
0.40... |
https://github.com/huggingface/datasets/issues/217 | Multi-task dataset mixing | I think that instead of proportional to size sampling you should specify weights or probabilities for drawing a batch from each dataset. We should also ensure that the smaller datasets are repeated so that the encoder layer doesn't overtrain on the largest dataset. | It seems like many of the best performing models on the GLUE benchmark make some use of multitask learning (simultaneous training on multiple tasks).
The [T5 paper](https://arxiv.org/pdf/1910.10683.pdf) highlights multiple ways of mixing the tasks together during finetuning:
- **Examples-proportional mixing** - sam... | 43 | Multi-task dataset mixing
It seems like many of the best performing models on the GLUE benchmark make some use of multitask learning (simultaneous training on multiple tasks).
The [T5 paper](https://arxiv.org/pdf/1910.10683.pdf) highlights multiple ways of mixing the tasks together during finetuning:
- **Examples... | [
-0.1033664495,
-0.4331936836,
-0.027864201,
-0.0140370037,
-0.2707730532,
0.0822165385,
0.154976666,
0.0747743025,
0.3294962943,
-0.0903300643,
-0.1661009043,
0.2605518997,
-0.1972152591,
0.4019605219,
0.3530556262,
-0.4648925364,
-0.053618703,
-0.2005532533,
-0.3664030135,
0.3... |
https://github.com/huggingface/datasets/issues/217 | Multi-task dataset mixing | Are there any references for people doing different batch sizes per task in the literature? I've only seen constant batch sizes with differing numbers of batches for each task which seems sufficient to prevent the impact of large datasets (Read 3.5.3 of the [T5 paper](https://arxiv.org/pdf/1910.10683.pdf) for example).... | It seems like many of the best performing models on the GLUE benchmark make some use of multitask learning (simultaneous training on multiple tasks).
The [T5 paper](https://arxiv.org/pdf/1910.10683.pdf) highlights multiple ways of mixing the tasks together during finetuning:
- **Examples-proportional mixing** - sam... | 47 | Multi-task dataset mixing
It seems like many of the best performing models on the GLUE benchmark make some use of multitask learning (simultaneous training on multiple tasks).
The [T5 paper](https://arxiv.org/pdf/1910.10683.pdf) highlights multiple ways of mixing the tasks together during finetuning:
- **Examples... | [
-0.0643153191,
-0.4659210145,
-0.0846640766,
-0.0310636386,
-0.2937632203,
0.0142679103,
0.2748716772,
-0.0015310899,
0.3273963928,
-0.0881962776,
-0.1483934075,
0.1096209884,
-0.1666351557,
0.4398264885,
0.3444591463,
-0.3664783835,
0.0387692675,
-0.2969401181,
-0.2708537579,
... |
https://github.com/huggingface/datasets/issues/217 | Multi-task dataset mixing | Hi,
regarding building T5 dataset , I think we can use datasets https://github.com/huggingface/datasets and then need something similar to tf.data.experimental.sample_from_datasets, do you know if similar functionality exist in pytorch? Which can sample multiple datasets with the given rates. thanks. | It seems like many of the best performing models on the GLUE benchmark make some use of multitask learning (simultaneous training on multiple tasks).
The [T5 paper](https://arxiv.org/pdf/1910.10683.pdf) highlights multiple ways of mixing the tasks together during finetuning:
- **Examples-proportional mixing** - sam... | 39 | Multi-task dataset mixing
It seems like many of the best performing models on the GLUE benchmark make some use of multitask learning (simultaneous training on multiple tasks).
The [T5 paper](https://arxiv.org/pdf/1910.10683.pdf) highlights multiple ways of mixing the tasks together during finetuning:
- **Examples... | [
-0.033306662,
-0.5136848688,
-0.0277796593,
0.0666486621,
-0.2503275573,
0.0426299646,
0.1753961593,
0.0604556203,
0.2067267001,
-0.128696233,
-0.2596320212,
0.1723336279,
-0.1614575386,
0.5526627898,
0.368904382,
-0.4282802343,
-0.0336442068,
-0.2255316079,
-0.3311313093,
0.35... |
https://github.com/huggingface/datasets/issues/216 | ❓ How to get ROUGE-2 with the ROUGE metric ? | For the rouge2 metric you can do
```python
rouge = nlp.load_metric('rouge')
with open("pred.txt") as p, open("ref.txt") as g:
for lp, lg in zip(p, g):
rouge.add(lp, lg)
score = rouge.compute(rouge_types=["rouge2"])
```
Note that I just did a PR to have both `.add` and `.add_batch` for metrics, t... | I'm trying to use ROUGE metric, but I don't know how to get the ROUGE-2 metric.
---
I compute scores with :
```python
import nlp
rouge = nlp.load_metric('rouge')
with open("pred.txt") as p, open("ref.txt") as g:
for lp, lg in zip(p, g):
rouge.add([lp], [lg])
score = rouge.compute()
```
... | 56 | ❓ How to get ROUGE-2 with the ROUGE metric ?
I'm trying to use ROUGE metric, but I don't know how to get the ROUGE-2 metric.
---
I compute scores with :
```python
import nlp
rouge = nlp.load_metric('rouge')
with open("pred.txt") as p, open("ref.txt") as g:
for lp, lg in zip(p, g):
rouge.ad... | [
0.0825815648,
-0.4401050508,
-0.0926092267,
0.3807033598,
-0.0594925582,
-0.1371209621,
-0.3506769836,
0.0906175002,
0.023501981,
0.2352947742,
-0.2559312582,
0.1684111208,
-0.0215513706,
0.002206913,
0.0974013284,
-0.3178663552,
0.0374228247,
-0.0347551107,
0.1625476778,
-0.20... |
https://github.com/huggingface/datasets/issues/216 | ❓ How to get ROUGE-2 with the ROUGE metric ? | Well I just tested with the official script and both rouge1 and rougeL return exactly the same thing for the input you gave, so this is actually fine ^^
I hope it helped :) | I'm trying to use ROUGE metric, but I don't know how to get the ROUGE-2 metric.
---
I compute scores with :
```python
import nlp
rouge = nlp.load_metric('rouge')
with open("pred.txt") as p, open("ref.txt") as g:
for lp, lg in zip(p, g):
rouge.add([lp], [lg])
score = rouge.compute()
```
... | 34 | ❓ How to get ROUGE-2 with the ROUGE metric ?
I'm trying to use ROUGE metric, but I don't know how to get the ROUGE-2 metric.
---
I compute scores with :
```python
import nlp
rouge = nlp.load_metric('rouge')
with open("pred.txt") as p, open("ref.txt") as g:
for lp, lg in zip(p, g):
rouge.ad... | [
0.1239901185,
-0.4979508817,
-0.0889847279,
0.3463136554,
-0.0841547847,
-0.220608592,
-0.3729411066,
0.0803579912,
0.0360451341,
0.22104913,
-0.218477577,
0.2334059626,
-0.0111090466,
-0.0014880461,
0.0768621638,
-0.284362942,
-0.0115884822,
-0.032634642,
0.085334383,
-0.24821... |
https://github.com/huggingface/datasets/issues/215 | NonMatchingSplitsSizesError when loading blog_authorship_corpus | I just ran it on colab and got this
```
[{'expected': SplitInfo(name='train', num_bytes=610252351, num_examples=532812,
dataset_name='blog_authorship_corpus'), 'recorded': SplitInfo(name='train',
num_bytes=611607465, num_examples=533285, dataset_name='blog_authorship_corpus')},
{'expected': SplitInfo(name='validat... | Getting this error when i run `nlp.load_dataset('blog_authorship_corpus')`.
```
raise NonMatchingSplitsSizesError(str(bad_splits))
nlp.utils.info_utils.NonMatchingSplitsSizesError: [{'expected': SplitInfo(name='train',
num_bytes=610252351, num_examples=532812, dataset_name='blog_authorship_corpus'),
'recorded... | 53 | NonMatchingSplitsSizesError when loading blog_authorship_corpus
Getting this error when i run `nlp.load_dataset('blog_authorship_corpus')`.
```
raise NonMatchingSplitsSizesError(str(bad_splits))
nlp.utils.info_utils.NonMatchingSplitsSizesError: [{'expected': SplitInfo(name='train',
num_bytes=610252351, num_ex... | [
-0.1318602413,
0.1403091848,
0.0594094284,
0.4210389256,
-0.1027606875,
0.0639110357,
-0.099390462,
0.240331769,
-0.1699518412,
0.1674247235,
-0.0025762771,
0.26936239,
0.1059270129,
-0.0292152967,
-0.0612887293,
0.1161757037,
-0.0757436976,
0.2383859158,
0.0664303377,
0.009824... |
https://github.com/huggingface/datasets/issues/215 | NonMatchingSplitsSizesError when loading blog_authorship_corpus | The files provided by the authors are corrupted and the script seems to ignore the xml files that can't be decoded (it does `try:... except UnicodeDecodeError`). Maybe depending of the environment some files can be opened and some others don't but not sure why | Getting this error when i run `nlp.load_dataset('blog_authorship_corpus')`.
```
raise NonMatchingSplitsSizesError(str(bad_splits))
nlp.utils.info_utils.NonMatchingSplitsSizesError: [{'expected': SplitInfo(name='train',
num_bytes=610252351, num_examples=532812, dataset_name='blog_authorship_corpus'),
'recorded... | 44 | NonMatchingSplitsSizesError when loading blog_authorship_corpus
Getting this error when i run `nlp.load_dataset('blog_authorship_corpus')`.
```
raise NonMatchingSplitsSizesError(str(bad_splits))
nlp.utils.info_utils.NonMatchingSplitsSizesError: [{'expected': SplitInfo(name='train',
num_bytes=610252351, num_ex... | [
-0.2156543136,
0.123475492,
0.0276874341,
0.4813606739,
-0.0115498547,
0.0988332853,
-0.131970197,
0.3685872257,
-0.0516961552,
0.1851564646,
0.0752991959,
0.1368834972,
0.0854276568,
-0.1344740838,
-0.0322381221,
0.0252991822,
-0.0925176367,
0.192950651,
0.0385471322,
-0.09255... |
https://github.com/huggingface/datasets/issues/215 | NonMatchingSplitsSizesError when loading blog_authorship_corpus | Feel free to do `ignore_verifications=True` for now... The verifications only include a check on the checksums of the downloaded files, and a check on the number of examples in each splits. | Getting this error when i run `nlp.load_dataset('blog_authorship_corpus')`.
```
raise NonMatchingSplitsSizesError(str(bad_splits))
nlp.utils.info_utils.NonMatchingSplitsSizesError: [{'expected': SplitInfo(name='train',
num_bytes=610252351, num_examples=532812, dataset_name='blog_authorship_corpus'),
'recorded... | 31 | NonMatchingSplitsSizesError when loading blog_authorship_corpus
Getting this error when i run `nlp.load_dataset('blog_authorship_corpus')`.
```
raise NonMatchingSplitsSizesError(str(bad_splits))
nlp.utils.info_utils.NonMatchingSplitsSizesError: [{'expected': SplitInfo(name='train',
num_bytes=610252351, num_ex... | [
-0.1591764987,
0.0613836013,
0.061370112,
0.3985074162,
-0.0911188424,
0.0681396499,
-0.1541564018,
0.3743871152,
-0.0539890826,
0.1291230023,
0.0949104577,
0.1696773171,
0.0508911684,
-0.070236817,
-0.0299418475,
-0.0313885398,
-0.0462678708,
0.2041032016,
0.043887347,
0.00102... |
https://github.com/huggingface/datasets/issues/215 | NonMatchingSplitsSizesError when loading blog_authorship_corpus | I'm getting this same issue when loading the `imdb` corpus via `dataset = load_dataset("imdb")`. When I try `ignore_verifications=True`, no examples are read into the `train` portion of the dataset. | Getting this error when i run `nlp.load_dataset('blog_authorship_corpus')`.
```
raise NonMatchingSplitsSizesError(str(bad_splits))
nlp.utils.info_utils.NonMatchingSplitsSizesError: [{'expected': SplitInfo(name='train',
num_bytes=610252351, num_examples=532812, dataset_name='blog_authorship_corpus'),
'recorded... | 29 | NonMatchingSplitsSizesError when loading blog_authorship_corpus
Getting this error when i run `nlp.load_dataset('blog_authorship_corpus')`.
```
raise NonMatchingSplitsSizesError(str(bad_splits))
nlp.utils.info_utils.NonMatchingSplitsSizesError: [{'expected': SplitInfo(name='train',
num_bytes=610252351, num_ex... | [
-0.1060909852,
0.1719285548,
0.0861469731,
0.3715280592,
-0.0706182122,
0.1975202262,
-0.0885156095,
0.3589628935,
-0.0705938339,
0.1323676556,
0.0109640332,
0.1926115304,
0.0197327435,
-0.1354332715,
-0.0613518618,
0.0010896521,
-0.0496847555,
0.1512274444,
0.080742538,
-0.000... |
https://github.com/huggingface/datasets/issues/215 | NonMatchingSplitsSizesError when loading blog_authorship_corpus | > I'm getting this same issue when loading the `imdb` corpus via `dataset = load_dataset("imdb")`. When I try `ignore_verifications=True`, no examples are read into the `train` portion of the dataset.
When the checksums don't match, it may mean that the file you downloaded is corrupted. In this case you can try to l... | Getting this error when i run `nlp.load_dataset('blog_authorship_corpus')`.
```
raise NonMatchingSplitsSizesError(str(bad_splits))
nlp.utils.info_utils.NonMatchingSplitsSizesError: [{'expected': SplitInfo(name='train',
num_bytes=610252351, num_examples=532812, dataset_name='blog_authorship_corpus'),
'recorded... | 100 | NonMatchingSplitsSizesError when loading blog_authorship_corpus
Getting this error when i run `nlp.load_dataset('blog_authorship_corpus')`.
```
raise NonMatchingSplitsSizesError(str(bad_splits))
nlp.utils.info_utils.NonMatchingSplitsSizesError: [{'expected': SplitInfo(name='train',
num_bytes=610252351, num_ex... | [
-0.1760097146,
0.1923223436,
0.0658073202,
0.4156299233,
0.0120831151,
0.1936919391,
-0.0606823191,
0.387897402,
-0.0591736846,
0.1324818879,
-0.0745150447,
0.1716660112,
0.0093407724,
-0.1365592778,
-0.0743671507,
0.0001400442,
-0.0610307604,
0.148367852,
0.0798779577,
0.03592... |
https://github.com/huggingface/datasets/issues/215 | NonMatchingSplitsSizesError when loading blog_authorship_corpus | I wasn't aware of the "force_redownload" option and manually removed the '/home/me/.cache/huggingface/datasets/' dir, this worked for me (dataset 'cnn_dailymail') | Getting this error when i run `nlp.load_dataset('blog_authorship_corpus')`.
```
raise NonMatchingSplitsSizesError(str(bad_splits))
nlp.utils.info_utils.NonMatchingSplitsSizesError: [{'expected': SplitInfo(name='train',
num_bytes=610252351, num_examples=532812, dataset_name='blog_authorship_corpus'),
'recorded... | 19 | NonMatchingSplitsSizesError when loading blog_authorship_corpus
Getting this error when i run `nlp.load_dataset('blog_authorship_corpus')`.
```
raise NonMatchingSplitsSizesError(str(bad_splits))
nlp.utils.info_utils.NonMatchingSplitsSizesError: [{'expected': SplitInfo(name='train',
num_bytes=610252351, num_ex... | [
-0.059520945,
0.1531679332,
0.0704789534,
0.3878913224,
-0.0151471877,
0.14190799,
-0.0923855081,
0.3200818598,
-0.0493567996,
0.008110567,
-0.0866535008,
0.1576870233,
0.0365481079,
0.0461472496,
-0.0197163671,
0.0897915661,
-0.0456513688,
0.2041371614,
0.0454466902,
0.0290789... |
https://github.com/huggingface/datasets/issues/215 | NonMatchingSplitsSizesError when loading blog_authorship_corpus | Yes I think this might not be documented well enough. Let’s add it to the doc @lhoestq @SBrandeis.
And everything on how to control the cache behavior better (removing, overriding, changing the path, etc) | Getting this error when i run `nlp.load_dataset('blog_authorship_corpus')`.
```
raise NonMatchingSplitsSizesError(str(bad_splits))
nlp.utils.info_utils.NonMatchingSplitsSizesError: [{'expected': SplitInfo(name='train',
num_bytes=610252351, num_examples=532812, dataset_name='blog_authorship_corpus'),
'recorded... | 34 | NonMatchingSplitsSizesError when loading blog_authorship_corpus
Getting this error when i run `nlp.load_dataset('blog_authorship_corpus')`.
```
raise NonMatchingSplitsSizesError(str(bad_splits))
nlp.utils.info_utils.NonMatchingSplitsSizesError: [{'expected': SplitInfo(name='train',
num_bytes=610252351, num_ex... | [
-0.047863476,
0.2781361043,
0.0776574016,
0.3915251195,
-0.1035542414,
0.0364040285,
-0.0826829523,
0.245960623,
-0.0835334063,
0.0461858809,
0.0891774446,
0.174503088,
0.0406077988,
-0.1594098508,
0.0179091115,
0.0528001115,
-0.0644668117,
0.1248314232,
0.1059797704,
0.0428974... |
https://github.com/huggingface/datasets/issues/215 | NonMatchingSplitsSizesError when loading blog_authorship_corpus | Already fixed:
```python
In [1]: from datasets import load_dataset
In [2]: ds = load_dataset("blog_authorship_corpus")
In [3]: ds
Out[3]:
DatasetDict({
train: Dataset({
features: ['text', 'date', 'gender', 'age', 'horoscope', 'job'],
num_rows: 689793
})
validation: Dataset({
... | Getting this error when i run `nlp.load_dataset('blog_authorship_corpus')`.
```
raise NonMatchingSplitsSizesError(str(bad_splits))
nlp.utils.info_utils.NonMatchingSplitsSizesError: [{'expected': SplitInfo(name='train',
num_bytes=610252351, num_examples=532812, dataset_name='blog_authorship_corpus'),
'recorded... | 44 | NonMatchingSplitsSizesError when loading blog_authorship_corpus
Getting this error when i run `nlp.load_dataset('blog_authorship_corpus')`.
```
raise NonMatchingSplitsSizesError(str(bad_splits))
nlp.utils.info_utils.NonMatchingSplitsSizesError: [{'expected': SplitInfo(name='train',
num_bytes=610252351, num_ex... | [
-0.071107097,
0.0366598926,
0.0406562947,
0.3773265779,
-0.0409735255,
0.1363151968,
-0.1240492538,
0.3613283038,
-0.0730668381,
0.1396705955,
0.0171016492,
0.1724952757,
0.0348223411,
-0.0652475804,
-0.0861277133,
0.0030061272,
-0.0310249534,
0.2065266222,
0.0756494775,
0.0239... |
https://github.com/huggingface/datasets/issues/211 | [Arrow writer, Trivia_qa] Could not convert TagMe with type str: converting to null type | Here the full error trace:
```
ArrowInvalid Traceback (most recent call last)
<ipython-input-1-7aaf3f011358> in <module>
1 import nlp
2 ds = nlp.load_dataset("trivia_qa", "rc", split="validation[:1%]") # this might take 2.3 min to download but it's cached afterwards...
... | Running the following code
```
import nlp
ds = nlp.load_dataset("trivia_qa", "rc", split="validation[:1%]") # this might take 2.3 min to download but it's cached afterwards...
ds.map(lambda x: x, load_from_cache_file=False)
```
triggers a `ArrowInvalid: Could not convert TagMe with type str: converting to n... | 155 | [Arrow writer, Trivia_qa] Could not convert TagMe with type str: converting to null type
Running the following code
```
import nlp
ds = nlp.load_dataset("trivia_qa", "rc", split="validation[:1%]") # this might take 2.3 min to download but it's cached afterwards...
ds.map(lambda x: x, load_from_cache_file=Fals... | [
0.047823716,
-0.014993907,
0.0999605879,
0.4827661216,
0.2526235878,
0.1182706654,
0.1242589504,
0.4629979134,
0.2045937479,
-0.1143020019,
0.19549191,
0.5628962517,
-0.1122898012,
-0.2145103067,
-0.0685442314,
-0.186553061,
0.1165155023,
0.242281273,
-0.0039507849,
-0.01945245... |
https://github.com/huggingface/datasets/issues/211 | [Arrow writer, Trivia_qa] Could not convert TagMe with type str: converting to null type | Actually thinking a bit more about it, it's probably a data sample that is not correct in `trivia_qa`. But I'm a bit surprised though that we managed to write it in .arrow format and now cannot write it anymore after an "identity" mapping. | Running the following code
```
import nlp
ds = nlp.load_dataset("trivia_qa", "rc", split="validation[:1%]") # this might take 2.3 min to download but it's cached afterwards...
ds.map(lambda x: x, load_from_cache_file=False)
```
triggers a `ArrowInvalid: Could not convert TagMe with type str: converting to n... | 43 | [Arrow writer, Trivia_qa] Could not convert TagMe with type str: converting to null type
Running the following code
```
import nlp
ds = nlp.load_dataset("trivia_qa", "rc", split="validation[:1%]") # this might take 2.3 min to download but it's cached afterwards...
ds.map(lambda x: x, load_from_cache_file=Fals... | [
0.1208235696,
0.08130005,
0.0889231637,
0.4082980454,
0.2814413905,
0.0546013862,
0.1137645021,
0.336548537,
0.1860096157,
-0.1869499981,
0.2484582067,
0.563483417,
0.0009857001,
-0.0783178657,
-0.0235587638,
-0.1181143522,
0.0730633289,
0.2508921623,
0.0506301932,
-0.124453350... |
https://github.com/huggingface/datasets/issues/211 | [Arrow writer, Trivia_qa] Could not convert TagMe with type str: converting to null type | Actually, I know what the problem is...I'm quite sure it's a bug. Here we take some test inputs: https://github.com/huggingface/nlp/blob/0e0ef12c14d2175e0b0bd7d8aa814b09e2cd7e1f/src/nlp/arrow_dataset.py#L472
It might be that in the test inputs, a `Sequence` type value is an emtpy list. So in my case I have `ds[0]["e... | Running the following code
```
import nlp
ds = nlp.load_dataset("trivia_qa", "rc", split="validation[:1%]") # this might take 2.3 min to download but it's cached afterwards...
ds.map(lambda x: x, load_from_cache_file=False)
```
triggers a `ArrowInvalid: Could not convert TagMe with type str: converting to n... | 79 | [Arrow writer, Trivia_qa] Could not convert TagMe with type str: converting to null type
Running the following code
```
import nlp
ds = nlp.load_dataset("trivia_qa", "rc", split="validation[:1%]") # this might take 2.3 min to download but it's cached afterwards...
ds.map(lambda x: x, load_from_cache_file=Fals... | [
0.0935575664,
-0.0521807335,
0.0917301625,
0.4922743738,
0.2525189519,
0.149210602,
0.1087134778,
0.4077001512,
0.1446878314,
-0.0935794562,
0.3454067111,
0.5846511126,
-0.1262975335,
-0.0814804733,
-0.0390669778,
-0.1896719784,
0.1572441608,
0.2686879635,
0.0862921402,
-0.0600... |
https://github.com/huggingface/datasets/issues/211 | [Arrow writer, Trivia_qa] Could not convert TagMe with type str: converting to null type | Good point, I think the schema should be infered at the writing stage where we have a `writer_batch_size` number of examples (typically 10k) so it's even less likely to run into this scenario. | Running the following code
```
import nlp
ds = nlp.load_dataset("trivia_qa", "rc", split="validation[:1%]") # this might take 2.3 min to download but it's cached afterwards...
ds.map(lambda x: x, load_from_cache_file=False)
```
triggers a `ArrowInvalid: Could not convert TagMe with type str: converting to n... | 33 | [Arrow writer, Trivia_qa] Could not convert TagMe with type str: converting to null type
Running the following code
```
import nlp
ds = nlp.load_dataset("trivia_qa", "rc", split="validation[:1%]") # this might take 2.3 min to download but it's cached afterwards...
ds.map(lambda x: x, load_from_cache_file=Fals... | [
-0.0682159662,
0.0609310828,
0.1053825095,
0.4737010896,
0.2520804405,
0.1043801382,
0.0982683748,
0.3812301755,
0.2232890278,
-0.0625071526,
0.327052325,
0.4799827635,
-0.0850770399,
-0.0221854337,
-0.0457398258,
-0.1310690492,
0.1612941921,
0.3236935139,
0.0635414273,
-0.1218... |
https://github.com/huggingface/datasets/issues/207 | Remove test set from NLP viewer | Appears that [two thirds of those polled on Twitter](https://twitter.com/srush_nlp/status/1265734497632477185) are in favor of _some_ mechanism for averting eyeballs from the test data. | While the new [NLP viewer](https://huggingface.co/nlp/viewer/) is a great tool, I think it would be best to outright remove the option of looking at the test sets. At the very least, a warning should be displayed to users before showing the test set. Newcomers to the field might not be aware of best practices, and smal... | 22 | Remove test set from NLP viewer
While the new [NLP viewer](https://huggingface.co/nlp/viewer/) is a great tool, I think it would be best to outright remove the option of looking at the test sets. At the very least, a warning should be displayed to users before showing the test set. Newcomers to the field might not be... | [
-0.1373631358,
0.1704824567,
-0.1900716126,
-0.2922054231,
-0.1791139394,
0.0449159294,
0.2525573671,
0.5567145348,
0.0552688353,
0.0512449406,
0.0143777346,
0.1753868163,
-0.3614472449,
0.0851458982,
0.0760480538,
0.1644964516,
-0.3026102781,
0.507019043,
-0.1310980916,
0.1275... |
https://github.com/huggingface/datasets/issues/206 | [Question] Combine 2 datasets which have the same columns | We are thinking about ways to combine datasets for T5 in #217, feel free to share your thoughts about this. | Hi,
I am using ``nlp`` to load personal datasets. I created summarization datasets in multi-languages based on wikinews. I have one dataset for english and one for german (french is getting to be ready as well). I want to keep these datasets independent because they need different pre-processing (add different task-... | 20 | [Question] Combine 2 datasets which have the same columns
Hi,
I am using ``nlp`` to load personal datasets. I created summarization datasets in multi-languages based on wikinews. I have one dataset for english and one for german (french is getting to be ready as well). I want to keep these datasets independent bec... | [
-0.2445140928,
0.0638989955,
0.0241110064,
0.3628228903,
0.1096221805,
0.438752532,
0.2699877918,
0.3603746295,
0.0449787527,
-0.1164475381,
-0.381480962,
0.1237430423,
0.0036282507,
0.2719851434,
0.2713171542,
-0.5642142892,
0.0580447204,
0.2187532783,
-0.5200102329,
0.1850373... |
https://github.com/huggingface/datasets/issues/197 | Scientific Papers only downloading Pubmed | Hi so there are indeed two configurations in the datasets as you can see [here](https://github.com/huggingface/nlp/blob/master/datasets/scientific_papers/scientific_papers.py#L81-L82).
You can load either one with:
```python
dataset = nlp.load_dataset('scientific_papers', 'pubmed')
dataset = nlp.load_dataset('sci... | Hi!
I have been playing around with this module, and I am a bit confused about the `scientific_papers` dataset. I thought that it would download two separate datasets, arxiv and pubmed. But when I run the following:
```
dataset = nlp.load_dataset('scientific_papers', data_dir='.', cache_dir='.')
Downloading: 10... | 98 | Scientific Papers only downloading Pubmed
Hi!
I have been playing around with this module, and I am a bit confused about the `scientific_papers` dataset. I thought that it would download two separate datasets, arxiv and pubmed. But when I run the following:
```
dataset = nlp.load_dataset('scientific_papers', d... | [
0.3410279155,
-0.0507830419,
0.0498375073,
0.2057842463,
-0.0124937389,
-0.0915831104,
0.1314337701,
0.247814104,
0.0751410052,
-0.2193238586,
-0.1656387001,
0.1005807742,
0.0638276264,
-0.2900844812,
0.2401751429,
0.0783972517,
0.0976620093,
0.1165957823,
0.1482487619,
-0.1969... |
https://github.com/huggingface/datasets/issues/197 | Scientific Papers only downloading Pubmed | Now if you don't specify which part you want, it raises an error:
```
ValueError: Config name is missing.
Please pick one among the available configs: ['pubmed', 'arxiv']
Example of usage:
`load_dataset('scientific_papers', 'pubmed')`
``` | Hi!
I have been playing around with this module, and I am a bit confused about the `scientific_papers` dataset. I thought that it would download two separate datasets, arxiv and pubmed. But when I run the following:
```
dataset = nlp.load_dataset('scientific_papers', data_dir='.', cache_dir='.')
Downloading: 10... | 34 | Scientific Papers only downloading Pubmed
Hi!
I have been playing around with this module, and I am a bit confused about the `scientific_papers` dataset. I thought that it would download two separate datasets, arxiv and pubmed. But when I run the following:
```
dataset = nlp.load_dataset('scientific_papers', d... | [
0.3337526023,
0.1518256515,
0.040382307,
0.1220906228,
-0.0115816938,
0.0701770857,
0.1087679267,
0.3869028687,
-0.1169543862,
-0.2211574465,
-0.1246671453,
0.3359684348,
0.0420466773,
-0.3219137192,
0.3353410363,
0.0597896762,
0.1705282778,
0.1198784262,
0.2469610423,
-0.32216... |
https://github.com/huggingface/datasets/issues/193 | [Tensorflow] Use something else than `from_tensor_slices()` | `from_generator` is not working on TPU, I met the following error :
```
File "/usr/local/lib/python3.6/contextlib.py", line 88, in __exit__
next(self.gen)
File "/home/usr/.venv/bart/lib/python3.6/site-packages/tensorflow_core/python/eager/context.py", line 1900, in execution_mode
executor_new.wait()
... | In the example notebook, the TF Dataset is built using `from_tensor_slices()` :
```python
columns = ['input_ids', 'token_type_ids', 'attention_mask', 'start_positions', 'end_positions']
train_tf_dataset.set_format(type='tensorflow', columns=columns)
features = {x: train_tf_dataset[x] for x in columns[:3]}
label... | 87 | [Tensorflow] Use something else than `from_tensor_slices()`
In the example notebook, the TF Dataset is built using `from_tensor_slices()` :
```python
columns = ['input_ids', 'token_type_ids', 'attention_mask', 'start_positions', 'end_positions']
train_tf_dataset.set_format(type='tensorflow', columns=columns)
fe... | [
-0.1073189527,
-0.0873602703,
0.0580076538,
0.1967510134,
0.211430043,
0.0975351855,
0.2802224457,
0.376408875,
-0.1501923501,
0.0037053109,
-0.068490155,
0.5348148942,
-0.1144310236,
0.0036038673,
0.3254977763,
-0.1784623116,
-0.034475401,
0.2562459707,
-0.066424273,
-0.069975... |
https://github.com/huggingface/datasets/issues/193 | [Tensorflow] Use something else than `from_tensor_slices()` | Could you send me the code you used to run create the dataset using `.from_generator` ? What version of tensorflow are you using ? | In the example notebook, the TF Dataset is built using `from_tensor_slices()` :
```python
columns = ['input_ids', 'token_type_ids', 'attention_mask', 'start_positions', 'end_positions']
train_tf_dataset.set_format(type='tensorflow', columns=columns)
features = {x: train_tf_dataset[x] for x in columns[:3]}
label... | 24 | [Tensorflow] Use something else than `from_tensor_slices()`
In the example notebook, the TF Dataset is built using `from_tensor_slices()` :
```python
columns = ['input_ids', 'token_type_ids', 'attention_mask', 'start_positions', 'end_positions']
train_tf_dataset.set_format(type='tensorflow', columns=columns)
fe... | [
-0.1686094552,
-0.0939882025,
0.0118441666,
0.1699762493,
0.2723707259,
0.0823568776,
0.2256459594,
0.3897307813,
-0.0503770448,
0.0051491251,
-0.0811935812,
0.6080825925,
-0.1429213136,
-0.0144129349,
0.2508258522,
-0.2165249139,
-0.1014940143,
0.2596186697,
-0.1496250778,
-0.... |
https://github.com/huggingface/datasets/issues/193 | [Tensorflow] Use something else than `from_tensor_slices()` | I'm using TF2.2
Here is my code :
```
import nlp
from transformers import BartTokenizer
tokenizer = BartTokenizer.from_pretrained('bart-large')
def encode(sample):
article_inputs = tokenizer.encode_plus(sample["article"], max_length=tokenizer.model_max_length, pad_to_max_length=True)
summary_input... | In the example notebook, the TF Dataset is built using `from_tensor_slices()` :
```python
columns = ['input_ids', 'token_type_ids', 'attention_mask', 'start_positions', 'end_positions']
train_tf_dataset.set_format(type='tensorflow', columns=columns)
features = {x: train_tf_dataset[x] for x in columns[:3]}
label... | 82 | [Tensorflow] Use something else than `from_tensor_slices()`
In the example notebook, the TF Dataset is built using `from_tensor_slices()` :
```python
columns = ['input_ids', 'token_type_ids', 'attention_mask', 'start_positions', 'end_positions']
train_tf_dataset.set_format(type='tensorflow', columns=columns)
fe... | [
-0.1217657626,
-0.0259318836,
0.047091566,
0.189819932,
0.1980040669,
0.1544272006,
0.2483755648,
0.456797421,
-0.0371507332,
-0.056614697,
-0.1416851282,
0.6093761325,
-0.18237634,
-0.0313649476,
0.2451844215,
-0.1602424234,
-0.051533293,
0.2101800144,
-0.0837807283,
-0.051119... |
https://github.com/huggingface/datasets/issues/193 | [Tensorflow] Use something else than `from_tensor_slices()` | Apparently we'll have to wait for the next tensorflow release to use `.from_generator` and TPU. See https://github.com/tensorflow/tensorflow/issues/34346#issuecomment-598262489 | In the example notebook, the TF Dataset is built using `from_tensor_slices()` :
```python
columns = ['input_ids', 'token_type_ids', 'attention_mask', 'start_positions', 'end_positions']
train_tf_dataset.set_format(type='tensorflow', columns=columns)
features = {x: train_tf_dataset[x] for x in columns[:3]}
label... | 17 | [Tensorflow] Use something else than `from_tensor_slices()`
In the example notebook, the TF Dataset is built using `from_tensor_slices()` :
```python
columns = ['input_ids', 'token_type_ids', 'attention_mask', 'start_positions', 'end_positions']
train_tf_dataset.set_format(type='tensorflow', columns=columns)
fe... | [
-0.1305494606,
-0.0308595859,
0.036304716,
0.1227417439,
0.2281212956,
0.0917752162,
0.2730555832,
0.4065893292,
-0.1111179888,
0.0027905405,
-0.0888080373,
0.5513768196,
-0.1521193534,
0.0472111925,
0.3196074963,
-0.2627650797,
-0.066504471,
0.2488583326,
-0.129807055,
-0.0143... |
https://github.com/huggingface/datasets/issues/192 | [Question] Create Apache Arrow dataset from raw text file | We store every dataset in the Arrow format. This is convenient as it supports nested types and memory mapping. If you are curious feel free to check the [pyarrow documentation](https://arrow.apache.org/docs/python/)
You can use this library to load your covid papers by creating a dataset script. You can find inspira... | Hi guys, I have gathered and preprocessed about 2GB of COVID papers from CORD dataset @ Kggle. I have seen you have a text dataset as "Crime and punishment" in Apache arrow format. Do you have any script to do it from a raw txt file (preprocessed as for BERT like) or any guide?
Is the worth of send it to you and add i... | 68 | [Question] Create Apache Arrow dataset from raw text file
Hi guys, I have gathered and preprocessed about 2GB of COVID papers from CORD dataset @ Kggle. I have seen you have a text dataset as "Crime and punishment" in Apache arrow format. Do you have any script to do it from a raw txt file (preprocessed as for BERT l... | [
-0.1738836914,
-0.0641048551,
-0.0457875691,
0.0695889592,
-0.3965014219,
0.1363759041,
0.067610465,
0.4003837109,
-0.0682437122,
-0.3222416639,
0.1313434988,
0.1833891571,
-0.0825047716,
0.0789602473,
0.3914310634,
-0.0407905914,
-0.0588861443,
0.2828744948,
-0.0328619219,
-0.... |
https://github.com/huggingface/datasets/issues/192 | [Question] Create Apache Arrow dataset from raw text file | Hello @mrm8488 and @lhoestq
Is there a way to convert a dataset to Apache arrow format (locally/personal use) & use it before sending it to hugging face?
Thanks :) | Hi guys, I have gathered and preprocessed about 2GB of COVID papers from CORD dataset @ Kggle. I have seen you have a text dataset as "Crime and punishment" in Apache arrow format. Do you have any script to do it from a raw txt file (preprocessed as for BERT like) or any guide?
Is the worth of send it to you and add i... | 29 | [Question] Create Apache Arrow dataset from raw text file
Hi guys, I have gathered and preprocessed about 2GB of COVID papers from CORD dataset @ Kggle. I have seen you have a text dataset as "Crime and punishment" in Apache arrow format. Do you have any script to do it from a raw txt file (preprocessed as for BERT l... | [
-0.1041028425,
-0.0871479362,
-0.0996507853,
0.154402867,
-0.375623703,
0.1595184803,
0.1173254177,
0.4278324544,
-0.0435958914,
-0.2937569916,
0.0730511919,
0.1151047349,
-0.0833792314,
0.1475035548,
0.2515309453,
-0.1538532078,
-0.088017337,
0.2165442705,
-0.2933831811,
0.015... |
https://github.com/huggingface/datasets/issues/192 | [Question] Create Apache Arrow dataset from raw text file | > Is there a way to convert a dataset to Apache arrow format (locally/personal use) & use it before sending it to hugging face?
Sure, to get a dataset in arrow format you can either:
- [load from local files (txt, json, csv)](https://huggingface.co/nlp/loading_datasets.html?highlight=csv#from-local-files)
- OR [lo... | Hi guys, I have gathered and preprocessed about 2GB of COVID papers from CORD dataset @ Kggle. I have seen you have a text dataset as "Crime and punishment" in Apache arrow format. Do you have any script to do it from a raw txt file (preprocessed as for BERT like) or any guide?
Is the worth of send it to you and add i... | 58 | [Question] Create Apache Arrow dataset from raw text file
Hi guys, I have gathered and preprocessed about 2GB of COVID papers from CORD dataset @ Kggle. I have seen you have a text dataset as "Crime and punishment" in Apache arrow format. Do you have any script to do it from a raw txt file (preprocessed as for BERT l... | [
-0.1162345931,
-0.1841172129,
-0.0716124624,
0.1751197875,
-0.3280257583,
0.13923648,
0.1179597378,
0.3817427158,
0.0022518754,
-0.2727223933,
0.0569149218,
0.0983997211,
-0.0772380307,
0.2192149311,
0.3109797239,
-0.0580278412,
-0.1029317826,
0.1872922778,
-0.2899802327,
0.034... |
https://github.com/huggingface/datasets/issues/192 | [Question] Create Apache Arrow dataset from raw text file | > > Is there a way to convert a dataset to Apache arrow format (locally/personal use) & use it before sending it to hugging face?
>
> Sure, to get a dataset in arrow format you can either:
>
> * [load from local files (txt, json, csv)](https://huggingface.co/nlp/loading_datasets.html?highlight=csv#from-local-... | Hi guys, I have gathered and preprocessed about 2GB of COVID papers from CORD dataset @ Kggle. I have seen you have a text dataset as "Crime and punishment" in Apache arrow format. Do you have any script to do it from a raw txt file (preprocessed as for BERT like) or any guide?
Is the worth of send it to you and add i... | 96 | [Question] Create Apache Arrow dataset from raw text file
Hi guys, I have gathered and preprocessed about 2GB of COVID papers from CORD dataset @ Kggle. I have seen you have a text dataset as "Crime and punishment" in Apache arrow format. Do you have any script to do it from a raw txt file (preprocessed as for BERT l... | [
-0.1038165167,
-0.2466496825,
-0.0638294667,
0.1784732193,
-0.2581138015,
0.1428022981,
0.1377847493,
0.3953747451,
0.005326408,
-0.2353558093,
0.0549273118,
0.0873039663,
-0.0744915605,
0.2466414273,
0.3077546954,
-0.0621265359,
-0.099836491,
0.1523498595,
-0.2911965549,
0.036... |
https://github.com/huggingface/datasets/issues/189 | [Question] BERT-style multiple choice formatting | Hi @sarahwie, can you details this a little more?
I'm not sure I understand what you refer to and what you mean when you say "Previously, this was done by passing a list of InputFeatures to the dataloader instead of a list of InputFeature" | Hello, I am wondering what the equivalent formatting of a dataset should be to allow for multiple-choice answering prediction, BERT-style. Previously, this was done by passing a list of `InputFeatures` to the dataloader instead of a list of `InputFeature`, where `InputFeatures` contained lists of length equal to the nu... | 44 | [Question] BERT-style multiple choice formatting
Hello, I am wondering what the equivalent formatting of a dataset should be to allow for multiple-choice answering prediction, BERT-style. Previously, this was done by passing a list of `InputFeatures` to the dataloader instead of a list of `InputFeature`, where `Input... | [
0.189832896,
-0.4081773162,
-0.0266714022,
-0.0789323747,
0.1755466908,
-0.1144006848,
0.2933264375,
0.2346475124,
-0.113138549,
-0.0067010731,
-0.0750768408,
0.5407447219,
-0.2563861012,
0.2198838443,
0.0012708907,
-0.4498933852,
0.1627258509,
0.132436201,
-0.1213600188,
-0.11... |
https://github.com/huggingface/datasets/issues/189 | [Question] BERT-style multiple choice formatting | I think I've resolved it. For others' reference: to convert from using the [`MultipleChoiceDataset` class](https://github.com/huggingface/transformers/blob/a34a9896ac2a4a33ff9cd805c76eed914c8d8965/examples/multiple-choice/utils_multiple_choice.py#L82)/[`run_multiple_choice.py`](https://github.com/huggingface/transforme... | Hello, I am wondering what the equivalent formatting of a dataset should be to allow for multiple-choice answering prediction, BERT-style. Previously, this was done by passing a list of `InputFeatures` to the dataloader instead of a list of `InputFeature`, where `InputFeatures` contained lists of length equal to the nu... | 168 | [Question] BERT-style multiple choice formatting
Hello, I am wondering what the equivalent formatting of a dataset should be to allow for multiple-choice answering prediction, BERT-style. Previously, this was done by passing a list of `InputFeatures` to the dataloader instead of a list of `InputFeature`, where `Input... | [
0.1992310584,
-0.5757997036,
0.0108198784,
-0.0699365214,
0.285918951,
-0.1536671072,
0.2446015775,
0.2416752875,
-0.0098713599,
0.0180190466,
-0.1549079269,
0.4558007121,
-0.2713593543,
0.0753546059,
0.125587225,
-0.3799525201,
0.1526272148,
0.0689933449,
-0.201622501,
-0.0675... |
https://github.com/huggingface/datasets/issues/188 | When will the remaining math_dataset modules be added as dataset objects | Hi @tylerroost, we don't have a timeline for this at the moment.
If you want to give it a look we would be happy to review a PR on it.
Also, the library is one week old so everything is quite barebones, in particular the doc.
You should expect some bumps on the road.
To get you started, you can check the datasets... | Currently only the algebra_linear_1d is supported. Is there a timeline for making the other modules supported. If no timeline is established, how can I help? | 160 | When will the remaining math_dataset modules be added as dataset objects
Currently only the algebra_linear_1d is supported. Is there a timeline for making the other modules supported. If no timeline is established, how can I help?
Hi @tylerroost, we don't have a timeline for this at the moment.
If you want to give... | [
-0.2745403945,
-0.0747144371,
-0.2828440666,
0.0816330761,
0.1013159007,
0.0851161778,
0.1622703522,
0.1815713942,
0.1549655646,
0.0289991796,
0.0906955451,
0.2542611063,
-0.2430141419,
0.0913355425,
0.2556447685,
-0.3420155346,
0.2013436556,
-0.071950227,
-0.2481055856,
-0.359... |
https://github.com/huggingface/datasets/issues/187 | [Question] How to load wikipedia ? Beam runner ? | I have seen that somebody is hard working on easierly loadable wikipedia. #129
Maybe I should wait a few days for that version ? | When `nlp.load_dataset('wikipedia')`, I got
* `WARNING:nlp.builder:Trying to generate a dataset using Apache Beam, yet no Beam Runner or PipelineOptions() has been provided. Please pass a nlp.DownloadConfig(beam_runner=...) object to the builder.download_and_prepare(download_config=...) method. Default values will be ... | 24 | [Question] How to load wikipedia ? Beam runner ?
When `nlp.load_dataset('wikipedia')`, I got
* `WARNING:nlp.builder:Trying to generate a dataset using Apache Beam, yet no Beam Runner or PipelineOptions() has been provided. Please pass a nlp.DownloadConfig(beam_runner=...) object to the builder.download_and_prepare(d... | [
-0.1516937166,
0.0031177262,
-0.0172200743,
0.3954120874,
-0.0661801994,
0.0557340309,
0.0433484018,
0.3345060945,
0.3488545418,
0.1168281958,
0.3199313283,
0.1732223779,
-0.1478526741,
-0.081899032,
-0.0162130967,
-0.459661454,
-0.0519882478,
0.2463432848,
0.036584489,
-0.0559... |
https://github.com/huggingface/datasets/issues/186 | Weird-ish: Not creating unique caches for different phases | Looks like a duplicate of #120.
This is already fixed on master. We'll do a new release on pypi soon | Sample code:
```python
import nlp
dataset = nlp.load_dataset('boolq')
def func1(x):
return x
def func2(x):
return None
train_output = dataset["train"].map(func1)
valid_output = dataset["validation"].map(func1)
print()
print(len(train_output), len(valid_output))
# Output: 9427 9427
```
Th... | 20 | Weird-ish: Not creating unique caches for different phases
Sample code:
```python
import nlp
dataset = nlp.load_dataset('boolq')
def func1(x):
return x
def func2(x):
return None
train_output = dataset["train"].map(func1)
valid_output = dataset["validation"].map(func1)
print()
print(len(trai... | [
0.3151271939,
-0.1353008747,
-0.0059516393,
0.2090220898,
0.0983513296,
-0.1870367974,
0.2608937323,
0.3269938827,
-0.1120344475,
-0.1279543787,
-0.1073976085,
0.4277701974,
0.0819043219,
-0.2038932741,
0.0939097255,
0.0684094205,
0.1656416059,
0.1147565395,
-0.1145203635,
-0.0... |
https://github.com/huggingface/datasets/issues/183 | [Bug] labels of glue/ax are all -1 | This is the test set given by the Glue benchmark. The labels are not provided, and therefore set to -1. | ```
ax = nlp.load_dataset('glue', 'ax')
for i in range(30): print(ax['test'][i]['label'], end=', ')
```
```
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
``` | 20 | [Bug] labels of glue/ax are all -1
```
ax = nlp.load_dataset('glue', 'ax')
for i in range(30): print(ax['test'][i]['label'], end=', ')
```
```
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
```
This is the test set given by the Glue be... | [
0.2502779663,
-0.3640763462,
-0.0616977029,
0.1393108815,
-0.0684488565,
-0.0784341693,
0.3446007669,
0.2630482912,
0.3701293766,
0.1910716444,
-0.2715183496,
0.684173286,
-0.0655927733,
0.1188958958,
0.1820766479,
-0.1121410206,
-0.1016678512,
0.3471296132,
-0.1504508704,
-0.1... |
https://github.com/huggingface/datasets/issues/181 | Cannot upload my own dataset | It's my misunderstanding. I cannot just upload a csv. I need to write a dataset loading script too. | I look into `nlp-cli` and `user.py` to learn how to upload my own data.
It is supposed to work like this
- Register to get username, password at huggingface.co
- `nlp-cli login` and type username, passworld
- I have a single file to upload at `./ttc/ttc_freq_extra.csv`
- `nlp-cli upload ttc/ttc_freq_extra.csv`
... | 18 | Cannot upload my own dataset
I look into `nlp-cli` and `user.py` to learn how to upload my own data.
It is supposed to work like this
- Register to get username, password at huggingface.co
- `nlp-cli login` and type username, passworld
- I have a single file to upload at `./ttc/ttc_freq_extra.csv`
- `nlp-cli u... | [
0.1318959743,
-0.1267826259,
0.056689743,
-0.0285367481,
0.1169986799,
-0.1541465968,
0.3969918191,
-0.0621061139,
-0.2148289382,
0.2518131137,
-0.0867062137,
0.1588995308,
-0.1718000621,
0.2942123115,
0.3824805915,
0.1044843495,
0.0907260701,
0.3132136762,
0.0396239012,
-0.127... |
https://github.com/huggingface/datasets/issues/181 | Cannot upload my own dataset | I now try with the sample `datasets/csv` folder.
nlp-cli upload csv
The error is still the same
```
2020-05-21 17:20:56.394659: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcudart.so.10.1
About to upload file /content/csv/csv.py to S3 under filen... | I look into `nlp-cli` and `user.py` to learn how to upload my own data.
It is supposed to work like this
- Register to get username, password at huggingface.co
- `nlp-cli login` and type username, passworld
- I have a single file to upload at `./ttc/ttc_freq_extra.csv`
- `nlp-cli upload ttc/ttc_freq_extra.csv`
... | 116 | Cannot upload my own dataset
I look into `nlp-cli` and `user.py` to learn how to upload my own data.
It is supposed to work like this
- Register to get username, password at huggingface.co
- `nlp-cli login` and type username, passworld
- I have a single file to upload at `./ttc/ttc_freq_extra.csv`
- `nlp-cli u... | [
0.0526049994,
-0.0281093195,
0.0553305857,
-0.0020758514,
0.1455782056,
-0.1847580522,
0.3376967013,
-0.0477227941,
-0.1926684082,
0.179722473,
-0.1303298026,
0.2436908484,
-0.211561814,
0.2791495621,
0.3693569005,
0.0698645785,
0.0132649159,
0.2872202992,
0.0126221878,
-0.1083... |
https://github.com/huggingface/datasets/issues/181 | Cannot upload my own dataset | We haven't tested the dataset upload feature yet cc @julien-c
This is on our short/mid-term roadmap though | I look into `nlp-cli` and `user.py` to learn how to upload my own data.
It is supposed to work like this
- Register to get username, password at huggingface.co
- `nlp-cli login` and type username, passworld
- I have a single file to upload at `./ttc/ttc_freq_extra.csv`
- `nlp-cli upload ttc/ttc_freq_extra.csv`
... | 17 | Cannot upload my own dataset
I look into `nlp-cli` and `user.py` to learn how to upload my own data.
It is supposed to work like this
- Register to get username, password at huggingface.co
- `nlp-cli login` and type username, passworld
- I have a single file to upload at `./ttc/ttc_freq_extra.csv`
- `nlp-cli u... | [
0.0101653021,
-0.0146974167,
0.0639978573,
-0.0472513624,
0.1368082166,
-0.1440621763,
0.3703482747,
-0.0352642573,
-0.1715518534,
0.1538786143,
-0.1031071171,
0.2589792609,
-0.230888322,
0.316873312,
0.3755463064,
0.0948918611,
0.0193721093,
0.2717736065,
-0.0201166067,
-0.098... |
https://github.com/huggingface/datasets/issues/181 | Cannot upload my own dataset | Even if I fix the `TypeError: __init__() got an unexpected keyword argument 'cdn'` error, it looks like it still uploads to `https://s3.amazonaws.com/models.huggingface.co/bert/<namespace>/<data... | I look into `nlp-cli` and `user.py` to learn how to upload my own data.
It is supposed to work like this
- Register to get username, password at huggingface.co
- `nlp-cli login` and type username, passworld
- I have a single file to upload at `./ttc/ttc_freq_extra.csv`
- `nlp-cli upload ttc/ttc_freq_extra.csv`
... | 25 | Cannot upload my own dataset
I look into `nlp-cli` and `user.py` to learn how to upload my own data.
It is supposed to work like this
- Register to get username, password at huggingface.co
- `nlp-cli login` and type username, passworld
- I have a single file to upload at `./ttc/ttc_freq_extra.csv`
- `nlp-cli u... | [
0.0766490102,
-0.0518902615,
0.0566433817,
-0.0133810174,
0.1621724963,
-0.1869215369,
0.3156284094,
-0.0278211888,
-0.1946025342,
0.1959181577,
-0.1271059215,
0.2358573526,
-0.2207300216,
0.2926345766,
0.3533961773,
0.0726656839,
0.005575309,
0.2951039374,
0.009005378,
-0.0938... |
https://github.com/huggingface/datasets/issues/181 | Cannot upload my own dataset | @lhoestq The endpoints in https://github.com/huggingface/nlp/blob/master/src/nlp/hf_api.py should be (depending on the type of file):
```
POST /api/datasets/presign
GET /api/datasets/listObjs
DELETE /api/datasets/deleteObj
POST /api/metrics/presign
GET /api/metrics/listObjs
DELETE /api/metrics/delete... | I look into `nlp-cli` and `user.py` to learn how to upload my own data.
It is supposed to work like this
- Register to get username, password at huggingface.co
- `nlp-cli login` and type username, passworld
- I have a single file to upload at `./ttc/ttc_freq_extra.csv`
- `nlp-cli upload ttc/ttc_freq_extra.csv`
... | 72 | Cannot upload my own dataset
I look into `nlp-cli` and `user.py` to learn how to upload my own data.
It is supposed to work like this
- Register to get username, password at huggingface.co
- `nlp-cli login` and type username, passworld
- I have a single file to upload at `./ttc/ttc_freq_extra.csv`
- `nlp-cli u... | [
0.0944482312,
-0.0302149169,
0.047693029,
-0.0215733983,
0.1586551666,
-0.1987860799,
0.309314698,
-0.0286144409,
-0.2004598975,
0.1795505136,
-0.141587615,
0.2648701668,
-0.2190389782,
0.2876113057,
0.3653647304,
0.0843751803,
-0.0124914935,
0.2811932862,
-0.014131953,
-0.0984... |
https://github.com/huggingface/datasets/issues/181 | Cannot upload my own dataset | New commands are
```
nlp-cli upload_dataset <path/to/dataset>
nlp-cli upload_metric <path/to/metric>
nlp-cli s3_datasets {rm, ls}
nlp-cli s3_metrics {rm, ls}
```
Closing this issue. | I look into `nlp-cli` and `user.py` to learn how to upload my own data.
It is supposed to work like this
- Register to get username, password at huggingface.co
- `nlp-cli login` and type username, passworld
- I have a single file to upload at `./ttc/ttc_freq_extra.csv`
- `nlp-cli upload ttc/ttc_freq_extra.csv`
... | 22 | Cannot upload my own dataset
I look into `nlp-cli` and `user.py` to learn how to upload my own data.
It is supposed to work like this
- Register to get username, password at huggingface.co
- `nlp-cli login` and type username, passworld
- I have a single file to upload at `./ttc/ttc_freq_extra.csv`
- `nlp-cli u... | [
0.1084668413,
-0.0440791063,
0.0504010841,
-0.0276057478,
0.1381331831,
-0.1811707616,
0.3266917765,
-0.009185385,
-0.1950226128,
0.1800153852,
-0.1299543828,
0.2376457304,
-0.2306768447,
0.2919654846,
0.3680001795,
0.0748571008,
0.0062182895,
0.2890027165,
0.0118492534,
-0.101... |
https://github.com/huggingface/datasets/issues/179 | [Feature request] separate split name and split instructions | If your dataset is a collection of sub-datasets, you should probably consider having one config per sub-dataset. For example for Glue, we have sst2, mnli etc.
If you want to have multiple train sets (for example one per stage). The easiest solution would be to name them `nlp.Split("train_stage1")`, `nlp.Split("train_s... | Currently, the name of an nlp.NamedSplit is parsed in arrow_reader.py and used as the instruction.
This makes it impossible to have several training sets, which can occur when:
- A dataset corresponds to a collection of sub-datasets
- A dataset was built in stages, adding new examples at each stage
Would it be ... | 54 | [Feature request] separate split name and split instructions
Currently, the name of an nlp.NamedSplit is parsed in arrow_reader.py and used as the instruction.
This makes it impossible to have several training sets, which can occur when:
- A dataset corresponds to a collection of sub-datasets
- A dataset was bui... | [
0.0433891453,
-0.1981111914,
0.0301856752,
0.2106905878,
0.1068344042,
0.084719196,
0.5492759347,
0.1950956732,
-0.0144091258,
0.1525932401,
0.0023249728,
0.4517516196,
-0.2708512843,
0.3255719543,
0.0190777406,
-0.4061379135,
-0.0645274222,
0.0613064282,
0.2330214679,
0.102285... |
https://github.com/huggingface/datasets/issues/179 | [Feature request] separate split name and split instructions | Thanks for the tip! I ended up setting up three different versions of the dataset with their own configs.
for the named splits, I was trying with `nlp.Split("train-stage1")`, which fails. Changing to `nlp.Split("train_stage1")` works :) I looked for examples of what works in the code comments, it may be worth adding... | Currently, the name of an nlp.NamedSplit is parsed in arrow_reader.py and used as the instruction.
This makes it impossible to have several training sets, which can occur when:
- A dataset corresponds to a collection of sub-datasets
- A dataset was built in stages, adding new examples at each stage
Would it be ... | 58 | [Feature request] separate split name and split instructions
Currently, the name of an nlp.NamedSplit is parsed in arrow_reader.py and used as the instruction.
This makes it impossible to have several training sets, which can occur when:
- A dataset corresponds to a collection of sub-datasets
- A dataset was bui... | [
0.1045850664,
-0.0982458293,
0.0275993254,
0.222478345,
0.1107441857,
0.1121136472,
0.5969957113,
0.2325302809,
-0.0358217806,
0.1119875684,
0.0187910423,
0.4395622015,
-0.2157789618,
0.250805974,
-0.0480737127,
-0.3708144426,
-0.031474404,
0.0995834321,
0.300932169,
0.11061366... |
https://github.com/huggingface/datasets/issues/168 | Loading 'wikitext' dataset fails | Hi, make sure you have a recent version of pyarrow.
Are you using it in Google Colab? In this case, this error is probably the same as #128 | Loading the 'wikitext' dataset fails with Attribute error:
Code to reproduce (From example notebook):
import nlp
wikitext_dataset = nlp.load_dataset('wikitext')
Error:
---------------------------------------------------------------------------
AttributeError Traceback (most rece... | 28 | Loading 'wikitext' dataset fails
Loading the 'wikitext' dataset fails with Attribute error:
Code to reproduce (From example notebook):
import nlp
wikitext_dataset = nlp.load_dataset('wikitext')
Error:
---------------------------------------------------------------------------
AttributeError ... | [
-0.1193377301,
0.0886275396,
-0.0089775361,
0.2101972103,
0.3692682683,
0.0260605086,
0.4487811625,
0.4131021202,
0.4330817759,
0.0125664314,
0.1238445863,
0.3954299688,
-0.1505491436,
0.0219625123,
0.120905675,
-0.4289897084,
-0.0337393172,
0.3636733592,
-0.0414667279,
0.06297... |
https://github.com/huggingface/datasets/issues/168 | Loading 'wikitext' dataset fails | Hi,
The squad bug seems to be fixed, but the loading of the 'wikitext' still suffers from this problem (on Colab with pyarrow=0.17.1). | Loading the 'wikitext' dataset fails with Attribute error:
Code to reproduce (From example notebook):
import nlp
wikitext_dataset = nlp.load_dataset('wikitext')
Error:
---------------------------------------------------------------------------
AttributeError Traceback (most rece... | 23 | Loading 'wikitext' dataset fails
Loading the 'wikitext' dataset fails with Attribute error:
Code to reproduce (From example notebook):
import nlp
wikitext_dataset = nlp.load_dataset('wikitext')
Error:
---------------------------------------------------------------------------
AttributeError ... | [
-0.1193377301,
0.0886275396,
-0.0089775361,
0.2101972103,
0.3692682683,
0.0260605086,
0.4487811625,
0.4131021202,
0.4330817759,
0.0125664314,
0.1238445863,
0.3954299688,
-0.1505491436,
0.0219625123,
0.120905675,
-0.4289897084,
-0.0337393172,
0.3636733592,
-0.0414667279,
0.06297... |
https://github.com/huggingface/datasets/issues/168 | Loading 'wikitext' dataset fails | When you install `nlp` for the first time on a Colab runtime, it updates the `pyarrow` library that was already on colab. This update shows this message on colab:
```
WARNING: The following packages were previously imported in this runtime:
[pyarrow]
You must restart the runtime in order to use newly installed ve... | Loading the 'wikitext' dataset fails with Attribute error:
Code to reproduce (From example notebook):
import nlp
wikitext_dataset = nlp.load_dataset('wikitext')
Error:
---------------------------------------------------------------------------
AttributeError Traceback (most rece... | 66 | Loading 'wikitext' dataset fails
Loading the 'wikitext' dataset fails with Attribute error:
Code to reproduce (From example notebook):
import nlp
wikitext_dataset = nlp.load_dataset('wikitext')
Error:
---------------------------------------------------------------------------
AttributeError ... | [
-0.1193377301,
0.0886275396,
-0.0089775361,
0.2101972103,
0.3692682683,
0.0260605086,
0.4487811625,
0.4131021202,
0.4330817759,
0.0125664314,
0.1238445863,
0.3954299688,
-0.1505491436,
0.0219625123,
0.120905675,
-0.4289897084,
-0.0337393172,
0.3636733592,
-0.0414667279,
0.06297... |
https://github.com/huggingface/datasets/issues/166 | Add a method to shuffle a dataset | +1 for the naming convention
About the `shuffle` method, from my understanding it should be done in `Dataloader` (better separation between dataset processing - usage) | Could maybe be a `dataset.shuffle(generator=None, seed=None)` signature method.
Also, we could maybe have a clear indication of which method modify in-place and which methods return/cache a modified dataset. I kinda like torch conversion of having an underscore suffix for all the methods which modify a dataset in-pl... | 25 | Add a method to shuffle a dataset
Could maybe be a `dataset.shuffle(generator=None, seed=None)` signature method.
Also, we could maybe have a clear indication of which method modify in-place and which methods return/cache a modified dataset. I kinda like torch conversion of having an underscore suffix for all the ... | [
0.1534198523,
-0.0373096764,
-0.0626970306,
-0.1290708333,
0.1771616787,
0.0837633684,
0.2535595894,
0.2304864675,
-0.2128241062,
0.3302724659,
-0.070757024,
0.7361390591,
-0.2225145251,
-0.2018122524,
0.0237802397,
-0.0824747533,
0.2442181706,
-0.2117859572,
-0.1650031656,
0.0... |
https://github.com/huggingface/datasets/issues/166 | Add a method to shuffle a dataset | +1 for shuffle in `Dataloader`.
Some `Dataloader` just store idxs of dataset and just shuffle those idxs, which might(?) be faster than do shuffle in dataset, especially when doing shuffle every epoch.
Also +1 for the naming convention. | Could maybe be a `dataset.shuffle(generator=None, seed=None)` signature method.
Also, we could maybe have a clear indication of which method modify in-place and which methods return/cache a modified dataset. I kinda like torch conversion of having an underscore suffix for all the methods which modify a dataset in-pl... | 38 | Add a method to shuffle a dataset
Could maybe be a `dataset.shuffle(generator=None, seed=None)` signature method.
Also, we could maybe have a clear indication of which method modify in-place and which methods return/cache a modified dataset. I kinda like torch conversion of having an underscore suffix for all the ... | [
0.0704690292,
0.0160608198,
-0.081076853,
-0.133093819,
0.1867505461,
-0.018764725,
0.3612542748,
0.2494378686,
-0.1316795647,
0.398124218,
-0.1151702926,
0.745942533,
-0.3297463059,
-0.2149704397,
-0.0445235856,
-0.0798156038,
0.2653796077,
-0.1031483859,
-0.2052427232,
0.0562... |
https://github.com/huggingface/datasets/issues/166 | Add a method to shuffle a dataset | As you might already know the issue of dataset shuffling came up in the nlp code [walkthrough](https://youtu.be/G3pOvrKkFuk?t=3204) by Yannic Kilcher
| Could maybe be a `dataset.shuffle(generator=None, seed=None)` signature method.
Also, we could maybe have a clear indication of which method modify in-place and which methods return/cache a modified dataset. I kinda like torch conversion of having an underscore suffix for all the methods which modify a dataset in-pl... | 20 | Add a method to shuffle a dataset
Could maybe be a `dataset.shuffle(generator=None, seed=None)` signature method.
Also, we could maybe have a clear indication of which method modify in-place and which methods return/cache a modified dataset. I kinda like torch conversion of having an underscore suffix for all the ... | [
0.1168218553,
0.0479952767,
-0.0080725132,
-0.2174370289,
0.1288823485,
0.0286900848,
0.1363592148,
0.3606431782,
-0.264739126,
0.2979815006,
0.0116362842,
0.8511585593,
-0.3536042571,
-0.2320980877,
0.2013928592,
-0.0704995468,
0.1584127098,
-0.1035659015,
-0.241491273,
0.0523... |
https://github.com/huggingface/datasets/issues/163 | [Feature request] Add cos-e v1.0 | Sounds good, @mariamabarham do you want to give a look?
I think we should have two configurations so we can allow either version of the dataset to be loaded with the `1.0` version being the default maybe.
Cc some authors of the great cos-e: @nazneenrajani @bmccann | I noticed the second release of cos-e (v1.11) is included in this repo. I wanted to request inclusion of v1.0, since this is the version on which results are reported on in [the paper](https://www.aclweb.org/anthology/P19-1487/), and v1.11 has noted [annotation](https://github.com/salesforce/cos-e/issues/2) [issues](ht... | 46 | [Feature request] Add cos-e v1.0
I noticed the second release of cos-e (v1.11) is included in this repo. I wanted to request inclusion of v1.0, since this is the version on which results are reported on in [the paper](https://www.aclweb.org/anthology/P19-1487/), and v1.11 has noted [annotation](https://github.com/sal... | [
-0.2522471845,
-0.2662769556,
-0.1281620115,
-0.3826156259,
-0.4156884551,
-0.1008782014,
0.0192686524,
0.2192732543,
-0.0871500075,
0.3809592724,
0.0570260398,
0.3763352334,
-0.0155464839,
0.38528198,
-0.0764768198,
0.1405268162,
0.0847293586,
0.3658879995,
-0.0866104886,
-0.1... |
https://github.com/huggingface/datasets/issues/163 | [Feature request] Add cos-e v1.0 | cos_e v1.0 is related to CQA v1.0 but only CQA v1.11 dataset is available on their website. Indeed their is lots of ids in cos_e v1, which are not in CQA v1.11 or the other way around.
@sarahwie, @thomwolf, @nazneenrajani, @bmccann do you know where I can find CQA v1.0
| I noticed the second release of cos-e (v1.11) is included in this repo. I wanted to request inclusion of v1.0, since this is the version on which results are reported on in [the paper](https://www.aclweb.org/anthology/P19-1487/), and v1.11 has noted [annotation](https://github.com/salesforce/cos-e/issues/2) [issues](ht... | 50 | [Feature request] Add cos-e v1.0
I noticed the second release of cos-e (v1.11) is included in this repo. I wanted to request inclusion of v1.0, since this is the version on which results are reported on in [the paper](https://www.aclweb.org/anthology/P19-1487/), and v1.11 has noted [annotation](https://github.com/sal... | [
-0.023233043,
-0.1867626309,
-0.1784631014,
-0.3313108981,
-0.5435764194,
0.0657166913,
-0.1783174872,
0.1259404272,
-0.3440613151,
0.4689725935,
0.2354181707,
0.1240530759,
0.0749001428,
0.4212985933,
0.0156425051,
0.0894114897,
0.1170305908,
0.4064913988,
0.1564116776,
-0.076... |
https://github.com/huggingface/datasets/issues/163 | [Feature request] Add cos-e v1.0 | @mariamabarham I'm also not sure where to find CQA 1.0. Perhaps it's not possible to include this version of the dataset. I'll close the issue if that's the case. | I noticed the second release of cos-e (v1.11) is included in this repo. I wanted to request inclusion of v1.0, since this is the version on which results are reported on in [the paper](https://www.aclweb.org/anthology/P19-1487/), and v1.11 has noted [annotation](https://github.com/salesforce/cos-e/issues/2) [issues](ht... | 29 | [Feature request] Add cos-e v1.0
I noticed the second release of cos-e (v1.11) is included in this repo. I wanted to request inclusion of v1.0, since this is the version on which results are reported on in [the paper](https://www.aclweb.org/anthology/P19-1487/), and v1.11 has noted [annotation](https://github.com/sal... | [
-0.2492517382,
-0.1036451831,
-0.1391214877,
-0.4210850894,
-0.530798018,
-0.0687483922,
-0.0787495673,
0.0790659934,
-0.2197635919,
0.4390555024,
0.15138264,
0.2936990559,
0.065341197,
0.4375330508,
0.0067789862,
0.2519570291,
0.1544279307,
0.3981415927,
-0.0359026119,
-0.0811... |
https://github.com/huggingface/datasets/issues/163 | [Feature request] Add cos-e v1.0 | You can now do
```python
from nlp import load_dataset
cos_e = load_dataset("cos_e", "v1.0")
```
Thanks @mariamabarham ! | I noticed the second release of cos-e (v1.11) is included in this repo. I wanted to request inclusion of v1.0, since this is the version on which results are reported on in [the paper](https://www.aclweb.org/anthology/P19-1487/), and v1.11 has noted [annotation](https://github.com/salesforce/cos-e/issues/2) [issues](ht... | 17 | [Feature request] Add cos-e v1.0
I noticed the second release of cos-e (v1.11) is included in this repo. I wanted to request inclusion of v1.0, since this is the version on which results are reported on in [the paper](https://www.aclweb.org/anthology/P19-1487/), and v1.11 has noted [annotation](https://github.com/sal... | [
-0.2524740398,
-0.2647849321,
-0.1142226234,
-0.4864543676,
-0.3794747889,
-0.2080277354,
0.0802878141,
0.1892700046,
0.1177972108,
0.3005792797,
-0.1557757109,
0.5226975679,
-0.1476928741,
0.4125776291,
0.1462085694,
0.1017268077,
0.0327463336,
0.3626562953,
-0.1460937411,
-0.... |
https://github.com/huggingface/datasets/issues/163 | [Feature request] Add cos-e v1.0 | @mariamabarham Just wanted to note that default behavior `cos_e = load_dataset("cos_e")` now loads `v1.0`. Not sure if this is intentional (but the flag specification does work as intended). | I noticed the second release of cos-e (v1.11) is included in this repo. I wanted to request inclusion of v1.0, since this is the version on which results are reported on in [the paper](https://www.aclweb.org/anthology/P19-1487/), and v1.11 has noted [annotation](https://github.com/salesforce/cos-e/issues/2) [issues](ht... | 28 | [Feature request] Add cos-e v1.0
I noticed the second release of cos-e (v1.11) is included in this repo. I wanted to request inclusion of v1.0, since this is the version on which results are reported on in [the paper](https://www.aclweb.org/anthology/P19-1487/), and v1.11 has noted [annotation](https://github.com/sal... | [
-0.2263442874,
-0.2859195471,
-0.1184171066,
-0.4919194281,
-0.4530386329,
-0.2508599758,
0.2163067013,
0.2214706242,
-0.0356377587,
0.3164639473,
0.0701321587,
0.4571440518,
0.0324566327,
0.353318274,
-0.1624480784,
0.4214379191,
0.1171860397,
0.2206686139,
-0.030112341,
-0.25... |
https://github.com/huggingface/datasets/issues/163 | [Feature request] Add cos-e v1.0 | > @mariamabarham Just wanted to note that default behavior `cos_e = load_dataset("cos_e")` now loads `v1.0`. Not sure if this is intentional (but the flag specification does work as intended).
In the new version of `nlp`, if you try `cos_e = load_dataset("cos_e")` it throws this error:
```
ValueError: Config name ... | I noticed the second release of cos-e (v1.11) is included in this repo. I wanted to request inclusion of v1.0, since this is the version on which results are reported on in [the paper](https://www.aclweb.org/anthology/P19-1487/), and v1.11 has noted [annotation](https://github.com/salesforce/cos-e/issues/2) [issues](ht... | 83 | [Feature request] Add cos-e v1.0
I noticed the second release of cos-e (v1.11) is included in this repo. I wanted to request inclusion of v1.0, since this is the version on which results are reported on in [the paper](https://www.aclweb.org/anthology/P19-1487/), and v1.11 has noted [annotation](https://github.com/sal... | [
-0.1603741497,
-0.1905594021,
-0.0409299918,
-0.5251527429,
-0.5301491618,
-0.2091351748,
0.0791702941,
0.302711159,
-0.0848676488,
0.2993150949,
0.0913368985,
0.5883417726,
-0.1273891479,
0.3007554114,
0.1448272467,
0.1922948807,
0.0493812673,
0.3573558033,
0.0160915069,
-0.14... |
https://github.com/huggingface/datasets/issues/161 | Discussion on version identifier & MockDataLoaderManager for test data | usually you can replace `download` in your dataset script with `download_and_prepare()` - could you share the code for your dataset here? :-) | Hi, I'm working on adding a dataset and ran into an error due to `download` not being defined on `MockDataLoaderManager`, but being defined in `nlp/utils/download_manager.py`. The readme step running this: `RUN_SLOW=1 pytest tests/test_dataset_common.py::DatasetTest::test_load_real_dataset_localmydatasetname` triggers ... | 22 | Discussion on version identifier & MockDataLoaderManager for test data
Hi, I'm working on adding a dataset and ran into an error due to `download` not being defined on `MockDataLoaderManager`, but being defined in `nlp/utils/download_manager.py`. The readme step running this: `RUN_SLOW=1 pytest tests/test_dataset_com... | [
-0.2984405756,
0.2715887427,
-0.0254016928,
-0.1736127436,
0.111338459,
-0.0324910805,
0.3496931195,
0.3046950102,
0.0963912159,
0.1327763945,
0.1502359211,
0.1813911051,
-0.2963352203,
0.0544607602,
0.1696766168,
0.0301238727,
-0.0018447201,
0.2378805727,
-0.1085272133,
0.2644... |
https://github.com/huggingface/datasets/issues/161 | Discussion on version identifier & MockDataLoaderManager for test data | I have an initial version here: https://github.com/EntilZha/nlp/tree/master/datasets/qanta Thats pretty close to what I'll do as a PR, but still want to do some more sanity checks/tests (just got tests passing).
I figured out how to get all tests passing by adding a download command and some finagling with the data ... | Hi, I'm working on adding a dataset and ran into an error due to `download` not being defined on `MockDataLoaderManager`, but being defined in `nlp/utils/download_manager.py`. The readme step running this: `RUN_SLOW=1 pytest tests/test_dataset_common.py::DatasetTest::test_load_real_dataset_localmydatasetname` triggers ... | 52 | Discussion on version identifier & MockDataLoaderManager for test data
Hi, I'm working on adding a dataset and ran into an error due to `download` not being defined on `MockDataLoaderManager`, but being defined in `nlp/utils/download_manager.py`. The readme step running this: `RUN_SLOW=1 pytest tests/test_dataset_com... | [
-0.1962165236,
0.4000366628,
-0.0314687788,
-0.1644132733,
0.0442839339,
-0.1332929879,
0.2794850469,
0.3761739731,
0.0094888834,
0.0829267427,
0.2064322382,
0.1580682844,
-0.3005684316,
0.0680409446,
0.1369245946,
0.0012007593,
-0.0564629696,
0.1698961407,
-0.0979536697,
0.212... |
https://github.com/huggingface/datasets/issues/161 | Discussion on version identifier & MockDataLoaderManager for test data | I'm quite positive that you can just replace the `dl_manager.download()` statements here: https://github.com/EntilZha/nlp/blob/4d46443b65f1f756921db8275594e6af008a1de7/datasets/qanta/qanta.py#L194 with `dl_manager.download_and_extract()` even though you don't extract anything. I would prefer to avoid adding more functi... | Hi, I'm working on adding a dataset and ran into an error due to `download` not being defined on `MockDataLoaderManager`, but being defined in `nlp/utils/download_manager.py`. The readme step running this: `RUN_SLOW=1 pytest tests/test_dataset_common.py::DatasetTest::test_load_real_dataset_localmydatasetname` triggers ... | 55 | Discussion on version identifier & MockDataLoaderManager for test data
Hi, I'm working on adding a dataset and ran into an error due to `download` not being defined on `MockDataLoaderManager`, but being defined in `nlp/utils/download_manager.py`. The readme step running this: `RUN_SLOW=1 pytest tests/test_dataset_com... | [
-0.1008702219,
0.5024333596,
-0.0397974662,
-0.0897842124,
0.0968035758,
-0.1224071234,
0.2872873545,
0.313552916,
-0.0543851703,
0.1157417446,
0.0461821891,
0.1649336964,
-0.2744551003,
-0.0059637045,
0.1659566313,
-0.0370163806,
-0.0780215338,
0.2551132739,
-0.0911451727,
0.2... |
https://github.com/huggingface/datasets/issues/161 | Discussion on version identifier & MockDataLoaderManager for test data | I might be doing something wrong, but swapping those two gives this error:
```
> with open(path) as f:
E IsADirectoryError: [Errno 21] Is a directory: 'datasets/qanta/dummy/mode=first,char_skip=25/2018.4.18/dummy_data-zip-extracted/dummy_data'
src/nlp/datasets/qanta/3d965403133687b819905ead4b69af7bcee... | Hi, I'm working on adding a dataset and ran into an error due to `download` not being defined on `MockDataLoaderManager`, but being defined in `nlp/utils/download_manager.py`. The readme step running this: `RUN_SLOW=1 pytest tests/test_dataset_common.py::DatasetTest::test_load_real_dataset_localmydatasetname` triggers ... | 88 | Discussion on version identifier & MockDataLoaderManager for test data
Hi, I'm working on adding a dataset and ran into an error due to `download` not being defined on `MockDataLoaderManager`, but being defined in `nlp/utils/download_manager.py`. The readme step running this: `RUN_SLOW=1 pytest tests/test_dataset_com... | [
0.0540467389,
0.0742236301,
0.0096599264,
0.171647042,
0.0184578244,
-0.182767421,
0.4075562358,
0.180736199,
0.0317735821,
0.2498854697,
0.0380607359,
0.0683050156,
-0.0652733222,
-0.2527975738,
0.0166336205,
0.1595783979,
0.1347910762,
0.0446651019,
-0.2199355811,
-0.00551133... |
https://github.com/huggingface/datasets/issues/161 | Discussion on version identifier & MockDataLoaderManager for test data | From what I can tell here: https://github.com/huggingface/nlp/blob/master/tests/utils.py#L115
1. `data_url` is the correct http link
2. `path_to_dummy_data` is a directory, which is causing the issue
That path comes from `download_dummy_data`, which I think assumes that the data comes from the zip file, but isn'... | Hi, I'm working on adding a dataset and ran into an error due to `download` not being defined on `MockDataLoaderManager`, but being defined in `nlp/utils/download_manager.py`. The readme step running this: `RUN_SLOW=1 pytest tests/test_dataset_common.py::DatasetTest::test_load_real_dataset_localmydatasetname` triggers ... | 112 | Discussion on version identifier & MockDataLoaderManager for test data
Hi, I'm working on adding a dataset and ran into an error due to `download` not being defined on `MockDataLoaderManager`, but being defined in `nlp/utils/download_manager.py`. The readme step running this: `RUN_SLOW=1 pytest tests/test_dataset_com... | [
-0.0789029077,
0.2855142951,
0.0002484826,
0.0527545623,
0.0506347045,
-0.2607542276,
0.214381963,
0.2759755552,
-0.0540339574,
0.0801737309,
0.2072282135,
0.2235736251,
-0.22146824,
-0.0345817022,
0.1244284287,
0.0544764623,
-0.1065846011,
0.0847873837,
-0.2250418961,
0.155033... |
https://github.com/huggingface/datasets/issues/161 | Discussion on version identifier & MockDataLoaderManager for test data | I think the dataset script works correctly. Just the dummy data structure seems to be wrong. I will soon add more commands that should make the create of the dummy data easier.
I'd recommend that you won't concentrate too much on the dummy data.
If you manage to load the dataset correctly via:
```python
# use ... | Hi, I'm working on adding a dataset and ran into an error due to `download` not being defined on `MockDataLoaderManager`, but being defined in `nlp/utils/download_manager.py`. The readme step running this: `RUN_SLOW=1 pytest tests/test_dataset_common.py::DatasetTest::test_load_real_dataset_localmydatasetname` triggers ... | 102 | Discussion on version identifier & MockDataLoaderManager for test data
Hi, I'm working on adding a dataset and ran into an error due to `download` not being defined on `MockDataLoaderManager`, but being defined in `nlp/utils/download_manager.py`. The readme step running this: `RUN_SLOW=1 pytest tests/test_dataset_com... | [
-0.1612340808,
0.2551890612,
0.0169224311,
-0.0688919872,
-0.0187329035,
-0.0799420699,
0.4035912156,
0.3387188613,
0.0754055902,
0.0486795045,
0.1928058714,
0.1107181013,
-0.2993967235,
0.1028156057,
0.100592427,
-0.1166136935,
0.0225546211,
0.2291208655,
-0.1793872863,
0.2209... |
https://github.com/huggingface/datasets/issues/161 | Discussion on version identifier & MockDataLoaderManager for test data | The script loading seems to work fine so I'll work on getting a PR open after a few sanity checks on the data.
On version, we currently have it versioned with YYYY.MM.DD scheme so it would be nice to not change that, but will it cause issues? | Hi, I'm working on adding a dataset and ran into an error due to `download` not being defined on `MockDataLoaderManager`, but being defined in `nlp/utils/download_manager.py`. The readme step running this: `RUN_SLOW=1 pytest tests/test_dataset_common.py::DatasetTest::test_load_real_dataset_localmydatasetname` triggers ... | 47 | Discussion on version identifier & MockDataLoaderManager for test data
Hi, I'm working on adding a dataset and ran into an error due to `download` not being defined on `MockDataLoaderManager`, but being defined in `nlp/utils/download_manager.py`. The readme step running this: `RUN_SLOW=1 pytest tests/test_dataset_com... | [
-0.1767385006,
0.2111752927,
-0.0094801923,
-0.1317931265,
0.0734432042,
-0.1427533478,
0.4176617563,
0.2573600113,
0.049972631,
0.119055748,
0.2233331352,
0.0696348399,
-0.2887467742,
0.0840552747,
0.0976940393,
-0.0076816366,
0.0639337152,
0.1413363069,
-0.104442291,
0.207669... |
https://github.com/huggingface/datasets/issues/161 | Discussion on version identifier & MockDataLoaderManager for test data | > The script loading seems to work fine so I'll work on getting a PR open after a few sanity checks on the data.
>
> On version, we currently have it versioned with YYYY.MM.DD scheme so it would be nice to not change that, but will it cause issues?
It would cause issues for sure for the tests....not sure if it wo... | Hi, I'm working on adding a dataset and ran into an error due to `download` not being defined on `MockDataLoaderManager`, but being defined in `nlp/utils/download_manager.py`. The readme step running this: `RUN_SLOW=1 pytest tests/test_dataset_common.py::DatasetTest::test_load_real_dataset_localmydatasetname` triggers ... | 115 | Discussion on version identifier & MockDataLoaderManager for test data
Hi, I'm working on adding a dataset and ran into an error due to `download` not being defined on `MockDataLoaderManager`, but being defined in `nlp/utils/download_manager.py`. The readme step running this: `RUN_SLOW=1 pytest tests/test_dataset_com... | [
-0.0784066468,
0.2176983505,
-0.0079946276,
-0.2187173218,
-0.0167495962,
-0.1501381397,
0.454857409,
0.3005518615,
0.0172306821,
0.0683667511,
0.2465082705,
0.0794770196,
-0.3443650305,
0.0902385339,
0.0619924925,
0.0040572346,
0.1139812768,
0.0871873125,
-0.0638601333,
0.1532... |
https://github.com/huggingface/datasets/issues/161 | Discussion on version identifier & MockDataLoaderManager for test data | Maybe use the YYYY.MM.DD as the config name ? That's what we are doing for wikipedia | Hi, I'm working on adding a dataset and ran into an error due to `download` not being defined on `MockDataLoaderManager`, but being defined in `nlp/utils/download_manager.py`. The readme step running this: `RUN_SLOW=1 pytest tests/test_dataset_common.py::DatasetTest::test_load_real_dataset_localmydatasetname` triggers ... | 16 | Discussion on version identifier & MockDataLoaderManager for test data
Hi, I'm working on adding a dataset and ran into an error due to `download` not being defined on `MockDataLoaderManager`, but being defined in `nlp/utils/download_manager.py`. The readme step running this: `RUN_SLOW=1 pytest tests/test_dataset_com... | [
-0.1411804557,
0.2805643976,
-0.0102291722,
-0.1734385788,
0.099620901,
-0.0562260896,
0.3951388597,
0.3567790687,
0.1325160414,
0.1633102298,
0.2544326484,
0.116898261,
-0.263643831,
-0.032296136,
0.0882676616,
-0.0225810241,
0.0243198778,
0.1539964378,
-0.0692429543,
0.253809... |
https://github.com/huggingface/datasets/issues/161 | Discussion on version identifier & MockDataLoaderManager for test data | > Maybe use the YYYY.MM.DD as the config name ? That's what we are doing for wikipedia
I'm not sure if this will work because the name should be unique and it seems that he has multiple config name in his data with the same version.
As @patrickvonplaten suggested, I think you can add a comment about the version i... | Hi, I'm working on adding a dataset and ran into an error due to `download` not being defined on `MockDataLoaderManager`, but being defined in `nlp/utils/download_manager.py`. The readme step running this: `RUN_SLOW=1 pytest tests/test_dataset_common.py::DatasetTest::test_load_real_dataset_localmydatasetname` triggers ... | 63 | Discussion on version identifier & MockDataLoaderManager for test data
Hi, I'm working on adding a dataset and ran into an error due to `download` not being defined on `MockDataLoaderManager`, but being defined in `nlp/utils/download_manager.py`. The readme step running this: `RUN_SLOW=1 pytest tests/test_dataset_com... | [
-0.0867197365,
0.2737458646,
0.0112488959,
-0.1407609284,
0.062711753,
-0.0481670983,
0.3938749731,
0.3804909885,
0.0893345922,
0.2072927058,
0.2584841549,
0.1472851634,
-0.2399411052,
-0.0154428724,
0.0475120656,
-0.0067648576,
-0.0585150942,
0.2121696621,
-0.0290327948,
0.273... |
https://github.com/huggingface/datasets/issues/161 | Discussion on version identifier & MockDataLoaderManager for test data | Actually maybe our versioning format (inherited from tfds) is too strong for what we use it for?
We could allow any string maybe?
I see it more and more like an identifier for the user that we will back with a serious hashing/versioning system.- so we could let the user quite free on it. | Hi, I'm working on adding a dataset and ran into an error due to `download` not being defined on `MockDataLoaderManager`, but being defined in `nlp/utils/download_manager.py`. The readme step running this: `RUN_SLOW=1 pytest tests/test_dataset_common.py::DatasetTest::test_load_real_dataset_localmydatasetname` triggers ... | 54 | Discussion on version identifier & MockDataLoaderManager for test data
Hi, I'm working on adding a dataset and ran into an error due to `download` not being defined on `MockDataLoaderManager`, but being defined in `nlp/utils/download_manager.py`. The readme step running this: `RUN_SLOW=1 pytest tests/test_dataset_com... | [
-0.1527510732,
0.2105689943,
0.0053559355,
-0.1521226168,
0.169531554,
-0.1229732335,
0.34444803,
0.3772254884,
0.0139795151,
0.2296850085,
0.167779386,
0.0152246105,
-0.3342417181,
0.0313073173,
0.0228185076,
-0.1002441868,
-0.0594150834,
0.1970061809,
-0.0730356574,
0.3432955... |
https://github.com/huggingface/datasets/issues/161 | Discussion on version identifier & MockDataLoaderManager for test data | I'm good with either putting it in description, adding it to the config, or loosening version formatting. I mostly don't have a full conceptual grasp of what each identifier ends up meaning in the datasets code so hard to evaluate the best approach.
For background, the multiple formats is a consequence of:
1. Eac... | Hi, I'm working on adding a dataset and ran into an error due to `download` not being defined on `MockDataLoaderManager`, but being defined in `nlp/utils/download_manager.py`. The readme step running this: `RUN_SLOW=1 pytest tests/test_dataset_common.py::DatasetTest::test_load_real_dataset_localmydatasetname` triggers ... | 152 | Discussion on version identifier & MockDataLoaderManager for test data
Hi, I'm working on adding a dataset and ran into an error due to `download` not being defined on `MockDataLoaderManager`, but being defined in `nlp/utils/download_manager.py`. The readme step running this: `RUN_SLOW=1 pytest tests/test_dataset_com... | [
0.057603512,
0.2424968481,
-0.0005986536,
-0.0168735441,
-0.0262222122,
-0.1091883853,
0.3703445196,
0.2744980156,
0.0017393329,
-0.0733634904,
0.1906663626,
0.1067380831,
-0.2590656579,
0.0527147464,
0.0636912361,
-0.1715937853,
0.0611245148,
0.2052568942,
-0.0903216675,
0.199... |
https://github.com/huggingface/datasets/issues/160 | caching in map causes same result to be returned for train, validation and test | Hi @dpressel,
thanks for posting your issue! Can you maybe add a complete code snippet that we can copy paste to reproduce the error? For example, I'm not sure where the variable `train_set` comes from in your code and it seems like you are loading multiple datasets at once? | hello,
I am working on a program that uses the `nlp` library with the `SST2` dataset.
The rough outline of the program is:
```
import nlp as nlp_datasets
...
parser.add_argument('--dataset', help='HuggingFace Datasets id', default=['glue', 'sst2'], nargs='+')
...
dataset = nlp_datasets.load_dataset(*args.... | 49 | caching in map causes same result to be returned for train, validation and test
hello,
I am working on a program that uses the `nlp` library with the `SST2` dataset.
The rough outline of the program is:
```
import nlp as nlp_datasets
...
parser.add_argument('--dataset', help='HuggingFace Datasets id', def... | [
-0.1263227016,
-0.2207092047,
-0.1006320566,
0.2780105472,
0.2454757094,
-0.2052233666,
0.1372109652,
0.5128593445,
0.1882862896,
-0.0623354614,
0.1278196871,
0.3891344368,
0.0037763796,
-0.1606175452,
-0.0107435985,
0.0242124125,
0.0960802212,
0.2350523919,
-0.1455623358,
-0.1... |
https://github.com/huggingface/datasets/issues/160 | caching in map causes same result to be returned for train, validation and test | Hi, the full example was listed in the PR above, but here is the exact link:
https://github.com/dpressel/mead-baseline/blob/3c1aa3ca062cb23f303ca98ac40b6652b37ee971/api-examples/layers-classify-hf-datasets.py
The problem is coming from
```
if cache_file_name is None:
# we create a u... | hello,
I am working on a program that uses the `nlp` library with the `SST2` dataset.
The rough outline of the program is:
```
import nlp as nlp_datasets
...
parser.add_argument('--dataset', help='HuggingFace Datasets id', default=['glue', 'sst2'], nargs='+')
...
dataset = nlp_datasets.load_dataset(*args.... | 99 | caching in map causes same result to be returned for train, validation and test
hello,
I am working on a program that uses the `nlp` library with the `SST2` dataset.
The rough outline of the program is:
```
import nlp as nlp_datasets
...
parser.add_argument('--dataset', help='HuggingFace Datasets id', def... | [
-0.1263227016,
-0.2207092047,
-0.1006320566,
0.2780105472,
0.2454757094,
-0.2052233666,
0.1372109652,
0.5128593445,
0.1882862896,
-0.0623354614,
0.1278196871,
0.3891344368,
0.0037763796,
-0.1606175452,
-0.0107435985,
0.0242124125,
0.0960802212,
0.2350523919,
-0.1455623358,
-0.1... |
https://github.com/huggingface/datasets/issues/160 | caching in map causes same result to be returned for train, validation and test | Ok, I think @lhoestq has already found a solution :-) Maybe you can chime in @lhoestq | hello,
I am working on a program that uses the `nlp` library with the `SST2` dataset.
The rough outline of the program is:
```
import nlp as nlp_datasets
...
parser.add_argument('--dataset', help='HuggingFace Datasets id', default=['glue', 'sst2'], nargs='+')
...
dataset = nlp_datasets.load_dataset(*args.... | 16 | caching in map causes same result to be returned for train, validation and test
hello,
I am working on a program that uses the `nlp` library with the `SST2` dataset.
The rough outline of the program is:
```
import nlp as nlp_datasets
...
parser.add_argument('--dataset', help='HuggingFace Datasets id', def... | [
-0.1263227016,
-0.2207092047,
-0.1006320566,
0.2780105472,
0.2454757094,
-0.2052233666,
0.1372109652,
0.5128593445,
0.1882862896,
-0.0623354614,
0.1278196871,
0.3891344368,
0.0037763796,
-0.1606175452,
-0.0107435985,
0.0242124125,
0.0960802212,
0.2350523919,
-0.1455623358,
-0.1... |
https://github.com/huggingface/datasets/issues/160 | caching in map causes same result to be returned for train, validation and test | > Ok, I think @lhoestq has already found a solution :-) Maybe you can chime in @lhoestq
Oh, awesome! I see the PR, Ill check it out | hello,
I am working on a program that uses the `nlp` library with the `SST2` dataset.
The rough outline of the program is:
```
import nlp as nlp_datasets
...
parser.add_argument('--dataset', help='HuggingFace Datasets id', default=['glue', 'sst2'], nargs='+')
...
dataset = nlp_datasets.load_dataset(*args.... | 27 | caching in map causes same result to be returned for train, validation and test
hello,
I am working on a program that uses the `nlp` library with the `SST2` dataset.
The rough outline of the program is:
```
import nlp as nlp_datasets
...
parser.add_argument('--dataset', help='HuggingFace Datasets id', def... | [
-0.1263227016,
-0.2207092047,
-0.1006320566,
0.2780105472,
0.2454757094,
-0.2052233666,
0.1372109652,
0.5128593445,
0.1882862896,
-0.0623354614,
0.1278196871,
0.3891344368,
0.0037763796,
-0.1606175452,
-0.0107435985,
0.0242124125,
0.0960802212,
0.2350523919,
-0.1455623358,
-0.1... |
https://github.com/huggingface/datasets/issues/160 | caching in map causes same result to be returned for train, validation and test | The PR should prevent the cache from losing track of the of the dataset type (based on the location of its data). Not sure about your second problem though (cache off). | hello,
I am working on a program that uses the `nlp` library with the `SST2` dataset.
The rough outline of the program is:
```
import nlp as nlp_datasets
...
parser.add_argument('--dataset', help='HuggingFace Datasets id', default=['glue', 'sst2'], nargs='+')
...
dataset = nlp_datasets.load_dataset(*args.... | 31 | caching in map causes same result to be returned for train, validation and test
hello,
I am working on a program that uses the `nlp` library with the `SST2` dataset.
The rough outline of the program is:
```
import nlp as nlp_datasets
...
parser.add_argument('--dataset', help='HuggingFace Datasets id', def... | [
-0.1263227016,
-0.2207092047,
-0.1006320566,
0.2780105472,
0.2454757094,
-0.2052233666,
0.1372109652,
0.5128593445,
0.1882862896,
-0.0623354614,
0.1278196871,
0.3891344368,
0.0037763796,
-0.1606175452,
-0.0107435985,
0.0242124125,
0.0960802212,
0.2350523919,
-0.1455623358,
-0.1... |
https://github.com/huggingface/datasets/issues/160 | caching in map causes same result to be returned for train, validation and test | Yes, with caching on, it seems to work without the function renaming hack, I mentioned this also in the PR. Thanks! | hello,
I am working on a program that uses the `nlp` library with the `SST2` dataset.
The rough outline of the program is:
```
import nlp as nlp_datasets
...
parser.add_argument('--dataset', help='HuggingFace Datasets id', default=['glue', 'sst2'], nargs='+')
...
dataset = nlp_datasets.load_dataset(*args.... | 21 | caching in map causes same result to be returned for train, validation and test
hello,
I am working on a program that uses the `nlp` library with the `SST2` dataset.
The rough outline of the program is:
```
import nlp as nlp_datasets
...
parser.add_argument('--dataset', help='HuggingFace Datasets id', def... | [
-0.1263227016,
-0.2207092047,
-0.1006320566,
0.2780105472,
0.2454757094,
-0.2052233666,
0.1372109652,
0.5128593445,
0.1882862896,
-0.0623354614,
0.1278196871,
0.3891344368,
0.0037763796,
-0.1606175452,
-0.0107435985,
0.0242124125,
0.0960802212,
0.2350523919,
-0.1455623358,
-0.1... |
https://github.com/huggingface/datasets/issues/157 | nlp.load_dataset() gives "TypeError: list_() takes exactly one argument (2 given)" | You can just run:
`val = nlp.load_dataset('squad')`
if you want to have just the validation script you can also do:
`val = nlp.load_dataset('squad', split="validation")` | I'm trying to load datasets from nlp but there seems to have error saying
"TypeError: list_() takes exactly one argument (2 given)"
gist can be found here
https://gist.github.com/saahiluppal/c4b878f330b10b9ab9762bc0776c0a6a | 24 | nlp.load_dataset() gives "TypeError: list_() takes exactly one argument (2 given)"
I'm trying to load datasets from nlp but there seems to have error saying
"TypeError: list_() takes exactly one argument (2 given)"
gist can be found here
https://gist.github.com/saahiluppal/c4b878f330b10b9ab9762bc0776c0a6a
You... | [
-0.047977902,
0.0604851469,
-0.0539134555,
0.2444887608,
0.2486795634,
0.1877575517,
0.2922646105,
0.3124673069,
0.1899906248,
-0.0237427447,
0.055783309,
0.4075591564,
-0.1347435266,
-0.0079089087,
0.2922927737,
-0.2682780921,
-0.1929555535,
0.3292344511,
0.1848608851,
-0.0630... |
https://github.com/huggingface/datasets/issues/157 | nlp.load_dataset() gives "TypeError: list_() takes exactly one argument (2 given)" | If you want to load a local dataset, make sure you include a `./` before the folder name. | I'm trying to load datasets from nlp but there seems to have error saying
"TypeError: list_() takes exactly one argument (2 given)"
gist can be found here
https://gist.github.com/saahiluppal/c4b878f330b10b9ab9762bc0776c0a6a | 18 | nlp.load_dataset() gives "TypeError: list_() takes exactly one argument (2 given)"
I'm trying to load datasets from nlp but there seems to have error saying
"TypeError: list_() takes exactly one argument (2 given)"
gist can be found here
https://gist.github.com/saahiluppal/c4b878f330b10b9ab9762bc0776c0a6a
If ... | [
-0.1817344874,
0.1649207771,
-0.0377625823,
0.3960108459,
0.2116740793,
0.080885224,
0.2252639681,
0.2089402527,
0.2736938,
-0.0764815733,
0.0226201415,
0.5386046171,
-0.1813198626,
-0.0346677229,
0.2664694488,
-0.3476086855,
-0.107025519,
0.3149689436,
-0.0650070012,
-0.206471... |
https://github.com/huggingface/datasets/issues/157 | nlp.load_dataset() gives "TypeError: list_() takes exactly one argument (2 given)" | This happens by just doing run all cells on colab ... I assumed the colab example is broken. | I'm trying to load datasets from nlp but there seems to have error saying
"TypeError: list_() takes exactly one argument (2 given)"
gist can be found here
https://gist.github.com/saahiluppal/c4b878f330b10b9ab9762bc0776c0a6a | 18 | nlp.load_dataset() gives "TypeError: list_() takes exactly one argument (2 given)"
I'm trying to load datasets from nlp but there seems to have error saying
"TypeError: list_() takes exactly one argument (2 given)"
gist can be found here
https://gist.github.com/saahiluppal/c4b878f330b10b9ab9762bc0776c0a6a
Thi... | [
0.0188430957,
0.045055069,
0.0057205544,
0.3553817868,
0.0485084392,
0.0158455912,
0.3805161417,
0.0017091668,
0.0825143531,
-0.0696415082,
0.0609747358,
0.6260882616,
-0.1543067098,
0.0177126769,
0.2570033967,
-0.1367096901,
-0.0055070226,
0.4703565538,
-0.0491585433,
-0.10325... |
https://github.com/huggingface/datasets/issues/157 | nlp.load_dataset() gives "TypeError: list_() takes exactly one argument (2 given)" | Oh I see you might have a wrong version of pyarrow install on the colab -> could you try the following. Add these lines to the beginning of your notebook, restart the runtime and run it again:
```
!pip uninstall -y -qq pyarrow
!pip uninstall -y -qq nlp
!pip install -qq git+https://github.com/huggingface/nlp.git
``... | I'm trying to load datasets from nlp but there seems to have error saying
"TypeError: list_() takes exactly one argument (2 given)"
gist can be found here
https://gist.github.com/saahiluppal/c4b878f330b10b9ab9762bc0776c0a6a | 53 | nlp.load_dataset() gives "TypeError: list_() takes exactly one argument (2 given)"
I'm trying to load datasets from nlp but there seems to have error saying
"TypeError: list_() takes exactly one argument (2 given)"
gist can be found here
https://gist.github.com/saahiluppal/c4b878f330b10b9ab9762bc0776c0a6a
Oh ... | [
-0.1487929672,
0.1773580909,
-0.0415254086,
0.3428393006,
0.1430012435,
-0.1136177182,
0.1551364064,
0.1810092777,
-0.1386963576,
-0.0235535037,
-0.1086144298,
0.8248554468,
-0.1088479534,
0.0025471903,
0.2896049321,
-0.2739559412,
-0.0902935937,
0.4029020965,
-0.0765955597,
-0... |
https://github.com/huggingface/datasets/issues/157 | nlp.load_dataset() gives "TypeError: list_() takes exactly one argument (2 given)" | > Oh I see you might have a wrong version of pyarrow install on the colab -> could you try the following. Add these lines to the beginning of your notebook, restart the runtime and run it again:
>
> ```
> !pip uninstall -y -qq pyarrow
> !pip uninstall -y -qq nlp
> !pip install -qq git+https://github.com/huggingfa... | I'm trying to load datasets from nlp but there seems to have error saying
"TypeError: list_() takes exactly one argument (2 given)"
gist can be found here
https://gist.github.com/saahiluppal/c4b878f330b10b9ab9762bc0776c0a6a | 65 | nlp.load_dataset() gives "TypeError: list_() takes exactly one argument (2 given)"
I'm trying to load datasets from nlp but there seems to have error saying
"TypeError: list_() takes exactly one argument (2 given)"
gist can be found here
https://gist.github.com/saahiluppal/c4b878f330b10b9ab9762bc0776c0a6a
> O... | [
-0.1167449877,
0.1842936873,
-0.0243382305,
0.4034666419,
0.1603585929,
-0.0801022276,
0.212623015,
0.1767460704,
-0.1010507643,
-0.0292399451,
-0.0643660724,
0.8222455978,
-0.1264524311,
-0.0137212174,
0.3064840734,
-0.3175933659,
-0.0604347587,
0.4053915739,
-0.0765031651,
-0... |
https://github.com/huggingface/datasets/issues/157 | nlp.load_dataset() gives "TypeError: list_() takes exactly one argument (2 given)" | Can you post a link here of your colab? I'll make a copy of it and see what's wrong | I'm trying to load datasets from nlp but there seems to have error saying
"TypeError: list_() takes exactly one argument (2 given)"
gist can be found here
https://gist.github.com/saahiluppal/c4b878f330b10b9ab9762bc0776c0a6a | 19 | nlp.load_dataset() gives "TypeError: list_() takes exactly one argument (2 given)"
I'm trying to load datasets from nlp but there seems to have error saying
"TypeError: list_() takes exactly one argument (2 given)"
gist can be found here
https://gist.github.com/saahiluppal/c4b878f330b10b9ab9762bc0776c0a6a
Can... | [
-0.0944178328,
0.0577484332,
-0.056376759,
0.4275853038,
0.1639646888,
0.0742793828,
0.272765696,
0.117011942,
0.1709994823,
-0.0799950287,
0.0186917819,
0.6328833103,
-0.242211163,
0.0163333025,
0.2107991874,
-0.2766316831,
-0.0907841697,
0.3511368334,
-0.0092701372,
-0.096804... |
https://github.com/huggingface/datasets/issues/157 | nlp.load_dataset() gives "TypeError: list_() takes exactly one argument (2 given)" | This should be fixed in the current version of the notebook. You can try it again | I'm trying to load datasets from nlp but there seems to have error saying
"TypeError: list_() takes exactly one argument (2 given)"
gist can be found here
https://gist.github.com/saahiluppal/c4b878f330b10b9ab9762bc0776c0a6a | 16 | nlp.load_dataset() gives "TypeError: list_() takes exactly one argument (2 given)"
I'm trying to load datasets from nlp but there seems to have error saying
"TypeError: list_() takes exactly one argument (2 given)"
gist can be found here
https://gist.github.com/saahiluppal/c4b878f330b10b9ab9762bc0776c0a6a
Thi... | [
-0.1471036673,
0.0616019145,
-0.0582842007,
0.4253877699,
0.1894993037,
0.0785846412,
0.2161244601,
0.2134930193,
0.151984334,
-0.1275144964,
-0.0001823361,
0.65108639,
-0.1451355368,
-0.0014385616,
0.335300982,
-0.3381651938,
-0.0270485394,
0.2980505228,
-0.1423707157,
-0.1399... |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.