
url stringlengths 58 61 | repository_url stringclasses 1
value | labels_url stringlengths 72 75 | comments_url stringlengths 67 70 | events_url stringlengths 65 68 | html_url stringlengths 48 51 | id int64 600M 3.09B | node_id stringlengths 18 24 | number int64 2 7.59k | title stringlengths 1 290 | user dict | labels listlengths 0 4 | state stringclasses 1
value | locked bool 1
class | assignee dict | assignees listlengths 0 4 | milestone dict | comments listlengths 0 30 | created_at timestamp[ns, tz=UTC]date 2020-04-14 18:18:51 2025-05-27 13:46:05 | updated_at timestamp[ns, tz=UTC]date 2020-04-29 09:23:05 2025-06-09 22:00:16 | closed_at timestamp[ns, tz=UTC]date 2020-04-29 09:23:05 2025-06-06 16:12:36 | author_association stringclasses 4
values | type float64 | active_lock_reason float64 | sub_issues_summary dict | body stringlengths 0 228k ⌀ | closed_by dict | reactions dict | timeline_url stringlengths 67 70 | performed_via_github_app float64 | state_reason stringclasses 3
values | draft float64 | pull_request null | time_to_close_hours float64 0.01 28.8k | __index_level_0__ int64 18 7.53k |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
https://api.github.com/repos/huggingface/datasets/issues/2953 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2953/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2953/comments | https://api.github.com/repos/huggingface/datasets/issues/2953/events | https://github.com/huggingface/datasets/issues/2953 | 1,002,766,517 | I_kwDODunzps47xQC1 | 2,953 | Trying to get in touch regarding a security issue | {
"avatar_url": "https://avatars.githubusercontent.com/u/55323451?v=4",
"events_url": "https://api.github.com/users/JamieSlome/events{/privacy}",
"followers_url": "https://api.github.com/users/JamieSlome/followers",
"following_url": "https://api.github.com/users/JamieSlome/following{/other_user}",
"gists_url": "https://api.github.com/users/JamieSlome/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/JamieSlome",
"id": 55323451,
"login": "JamieSlome",
"node_id": "MDQ6VXNlcjU1MzIzNDUx",
"organizations_url": "https://api.github.com/users/JamieSlome/orgs",
"received_events_url": "https://api.github.com/users/JamieSlome/received_events",
"repos_url": "https://api.github.com/users/JamieSlome/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/JamieSlome/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/JamieSlome/subscriptions",
"type": "User",
"url": "https://api.github.com/users/JamieSlome",
"user_view_type": "public"
} | [] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [
"Hi @JamieSlome,\r\n\r\nThanks for reaching out. Yes, you are right: I'm opening a PR to add the `SECURITY.md` file and a contact method.\r\n\r\nIn the meantime, please feel free to report the security issue to: feedback@huggingface.co"
] | 2021-09-21T15:58:13Z | 2021-10-21T15:16:43Z | 2021-10-21T15:16:43Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | Hey there!
I'd like to report a security issue but cannot find contact instructions on your repository.
If not a hassle, might you kindly add a `SECURITY.md` file with an email, or another contact method? GitHub [recommends](https://docs.github.com/en/code-security/getting-started/adding-a-security-policy-to-your-repository) this best practice to ensure security issues are responsibly disclosed, and it would serve as a simple instruction for security researchers in the future.
Thank you for your consideration, and I look forward to hearing from you!
(cc @huntr-helper) | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2953/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2953/timeline | null | completed | null | null | 719.308333 | 4,627 |
https://api.github.com/repos/huggingface/datasets/issues/2945 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2945/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2945/comments | https://api.github.com/repos/huggingface/datasets/issues/2945/events | https://github.com/huggingface/datasets/issues/2945 | 1,000,624,883 | I_kwDODunzps47pFLz | 2,945 | Protect master branch | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | null | [] | null | [
"Cool, I think we can do both :)",
"@lhoestq now the 2 are implemented.\r\n\r\nPlease note that for the the second protection, finally I have chosen to protect the master branch only from **merge commits** (see update comment above), so no need to disable/re-enable the protection on each release (direct commits, ... | 2021-09-20T06:47:01Z | 2021-09-20T12:01:27Z | 2021-09-20T12:00:16Z | MEMBER | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | After accidental merge commit (91c55355b634d0dc73350a7ddee1a6776dbbdd69) into `datasets` master branch, all commits present in the feature branch were permanently added to `datasets` master branch history, as e.g.:
- 00cc036fea7c7745cfe722360036ed306796a3f2
- 13ae8c98602bbad8197de3b9b425f4c78f582af1
- ...
I propose to protect our master branch, so that we avoid we can accidentally make this kind of mistakes in the future:
- [x] For Pull Requests using GitHub, allow only squash merging, so that only a single commit per Pull Request is merged into the master branch
- Currently, simple merge commits are already disabled
- I propose to disable rebase merging as well
- ~~Protect the master branch from direct pushes (to avoid accidentally pushing of merge commits)~~
- ~~This protection would reject direct pushes to master branch~~
- ~~If so, for each release (when we need to commit directly to the master branch), we should previously disable the protection and re-enable it again after the release~~
- [x] Protect the master branch only from direct pushing of **merge commits**
- GitHub offers the possibility to protect the master branch only from merge commits (which are the ones that introduce all the commits from the feature branch into the master branch).
- No need to disable/re-enable this protection on each release
This purpose of this Issue is to open a discussion about this problem and to agree in a solution. | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2945/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2945/timeline | null | completed | null | null | 5.220833 | 4,635 |
https://api.github.com/repos/huggingface/datasets/issues/2944 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2944/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2944/comments | https://api.github.com/repos/huggingface/datasets/issues/2944/events | https://github.com/huggingface/datasets/issues/2944 | 1,000,544,370 | I_kwDODunzps47oxhy | 2,944 | Add `remove_columns` to `IterableDataset ` | {
"avatar_url": "https://avatars.githubusercontent.com/u/31893406?v=4",
"events_url": "https://api.github.com/users/cccntu/events{/privacy}",
"followers_url": "https://api.github.com/users/cccntu/followers",
"following_url": "https://api.github.com/users/cccntu/following{/other_user}",
"gists_url": "https://api.github.com/users/cccntu/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/cccntu",
"id": 31893406,
"login": "cccntu",
"node_id": "MDQ6VXNlcjMxODkzNDA2",
"organizations_url": "https://api.github.com/users/cccntu/orgs",
"received_events_url": "https://api.github.com/users/cccntu/received_events",
"repos_url": "https://api.github.com/users/cccntu/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/cccntu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/cccntu/subscriptions",
"type": "User",
"url": "https://api.github.com/users/cccntu",
"user_view_type": "public"
} | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
},
{
"color": "7057ff",
"default": true... | closed | false | null | [] | null | [
"Hi ! Good idea :)\r\nIf you are interested in contributing, feel free to give it a try and open a Pull Request. Also let me know if I can help you with this or if you have questions"
] | 2021-09-20T04:01:00Z | 2021-10-08T15:31:53Z | 2021-10-08T15:31:53Z | CONTRIBUTOR | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | **Is your feature request related to a problem? Please describe.**
A clear and concise description of what the problem is.
```python
from datasets import load_dataset
dataset = load_dataset("c4", 'realnewslike', streaming =True, split='train')
dataset = dataset.remove_columns('url')
```
```
AttributeError: 'IterableDataset' object has no attribute 'remove_columns'
```
**Describe the solution you'd like**
It would be nice to have `.remove_columns()` to match the `Datasets` api.
**Describe alternatives you've considered**
This can be done with a single call to `.map()`,
I can try to help add this. 🤗 | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2944/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2944/timeline | null | completed | null | null | 443.514722 | 4,636 |
https://api.github.com/repos/huggingface/datasets/issues/2943 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2943/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2943/comments | https://api.github.com/repos/huggingface/datasets/issues/2943/events | https://github.com/huggingface/datasets/issues/2943 | 1,000,355,115 | I_kwDODunzps47oDUr | 2,943 | Backwards compatibility broken for cached datasets that use `.filter()` | {
"avatar_url": "https://avatars.githubusercontent.com/u/26864830?v=4",
"events_url": "https://api.github.com/users/anton-l/events{/privacy}",
"followers_url": "https://api.github.com/users/anton-l/followers",
"following_url": "https://api.github.com/users/anton-l/following{/other_user}",
"gists_url": "https://api.github.com/users/anton-l/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/anton-l",
"id": 26864830,
"login": "anton-l",
"node_id": "MDQ6VXNlcjI2ODY0ODMw",
"organizations_url": "https://api.github.com/users/anton-l/orgs",
"received_events_url": "https://api.github.com/users/anton-l/received_events",
"repos_url": "https://api.github.com/users/anton-l/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/anton-l/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/anton-l/subscriptions",
"type": "User",
"url": "https://api.github.com/users/anton-l",
"user_view_type": "public"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists... | null | [
"Hi ! I guess the caching mechanism should have considered the new `filter` to be different from the old one, and don't use cached results from the old `filter`.\r\nTo avoid other users from having this issue we could make the caching differentiate the two, what do you think ?",
"If it's easy enough to implement,... | 2021-09-19T16:16:37Z | 2021-09-20T16:25:43Z | 2021-09-20T16:25:42Z | MEMBER | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ## Describe the bug
After upgrading to datasets `1.12.0`, some cached `.filter()` steps from `1.11.0` started failing with
`ValueError: Keys mismatch: between {'indices': Value(dtype='uint64', id=None)} and {'file': Value(dtype='string', id=None), 'text': Value(dtype='string', id=None), 'speaker_id': Value(dtype='int64', id=None), 'chapter_id': Value(dtype='int64', id=None), 'id': Value(dtype='string', id=None)}`
Related feature: https://github.com/huggingface/datasets/pull/2836
:question: This is probably a `wontfix` bug, since it can be solved by simply cleaning the related cache dirs, but the workaround could be useful for someone googling the error :)
## Workaround
Remove the cache for the given dataset, e.g. `rm -rf ~/.cache/huggingface/datasets/librispeech_asr`.
## Steps to reproduce the bug
1. Delete `~/.cache/huggingface/datasets/librispeech_asr` if it exists.
2. `pip install datasets==1.11.0` and run the following snippet:
```python
from datasets import load_dataset
ids = ["1272-141231-0000"]
ds = load_dataset("patrickvonplaten/librispeech_asr_dummy", "clean", split="validation")
ds = ds.filter(lambda x: x["id"] in ids)
```
3. `pip install datasets==1.12.1` and re-run the code again
## Expected results
Same result as with the previous `datasets` version.
## Actual results
```bash
Reusing dataset librispeech_asr (./.cache/huggingface/datasets/librispeech_asr/clean/2.1.0/468ec03677f46a8714ac6b5b64dba02d246a228d92cbbad7f3dc190fa039eab1)
Loading cached processed dataset at ./.cache/huggingface/datasets/librispeech_asr/clean/2.1.0/468ec03677f46a8714ac6b5b64dba02d246a228d92cbbad7f3dc190fa039eab1/cache-cd1c29844fdbc87a.arrow
Traceback (most recent call last):
File "./repos/transformers/src/transformers/models/wav2vec2/try_dataset.py", line 5, in <module>
ds = ds.filter(lambda x: x["id"] in ids)
File "./envs/transformers/lib/python3.8/site-packages/datasets/arrow_dataset.py", line 185, in wrapper
out: Union["Dataset", "DatasetDict"] = func(self, *args, **kwargs)
File "./envs/transformers/lib/python3.8/site-packages/datasets/fingerprint.py", line 398, in wrapper
out = func(self, *args, **kwargs)
File "./envs/transformers/lib/python3.8/site-packages/datasets/arrow_dataset.py", line 2169, in filter
indices = self.map(
File "./envs/transformers/lib/python3.8/site-packages/datasets/arrow_dataset.py", line 1686, in map
return self._map_single(
File "./envs/transformers/lib/python3.8/site-packages/datasets/arrow_dataset.py", line 185, in wrapper
out: Union["Dataset", "DatasetDict"] = func(self, *args, **kwargs)
File "./envs/transformers/lib/python3.8/site-packages/datasets/fingerprint.py", line 398, in wrapper
out = func(self, *args, **kwargs)
File "./envs/transformers/lib/python3.8/site-packages/datasets/arrow_dataset.py", line 1896, in _map_single
return Dataset.from_file(cache_file_name, info=info, split=self.split)
File "./envs/transformers/lib/python3.8/site-packages/datasets/arrow_dataset.py", line 343, in from_file
return cls(
File "./envs/transformers/lib/python3.8/site-packages/datasets/arrow_dataset.py", line 282, in __init__
self.info.features = self.info.features.reorder_fields_as(inferred_features)
File "./envs/transformers/lib/python3.8/site-packages/datasets/features.py", line 1151, in reorder_fields_as
return Features(recursive_reorder(self, other))
File "./envs/transformers/lib/python3.8/site-packages/datasets/features.py", line 1140, in recursive_reorder
raise ValueError(f"Keys mismatch: between {source} and {target}" + stack_position)
ValueError: Keys mismatch: between {'indices': Value(dtype='uint64', id=None)} and {'file': Value(dtype='string', id=None), 'text': Value(dtype='string', id=None), 'speaker_id': Value(dtype='int64', id=None), 'chapter_id': Value(dtype='int64', id=None), 'id': Value(dtype='string', id=None)}
Process finished with exit code 1
```
## Environment info
- `datasets` version: 1.12.1
- Platform: Linux-5.11.0-34-generic-x86_64-with-glibc2.17
- Python version: 3.8.10
- PyArrow version: 5.0.0
| {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | {
"+1": 2,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2943/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2943/timeline | null | completed | null | null | 24.151389 | 4,637 |
https://api.github.com/repos/huggingface/datasets/issues/2937 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2937/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2937/comments | https://api.github.com/repos/huggingface/datasets/issues/2937/events | https://github.com/huggingface/datasets/issues/2937 | 999,548,277 | I_kwDODunzps47k-V1 | 2,937 | load_dataset using default cache on Windows causes PermissionError: [WinError 5] Access is denied | {
"avatar_url": "https://avatars.githubusercontent.com/u/40532020?v=4",
"events_url": "https://api.github.com/users/daqieq/events{/privacy}",
"followers_url": "https://api.github.com/users/daqieq/followers",
"following_url": "https://api.github.com/users/daqieq/following{/other_user}",
"gists_url": "https://api.github.com/users/daqieq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/daqieq",
"id": 40532020,
"login": "daqieq",
"node_id": "MDQ6VXNlcjQwNTMyMDIw",
"organizations_url": "https://api.github.com/users/daqieq/orgs",
"received_events_url": "https://api.github.com/users/daqieq/received_events",
"repos_url": "https://api.github.com/users/daqieq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/daqieq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/daqieq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/daqieq",
"user_view_type": "public"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"Hi @daqieq, thanks for reporting.\r\n\r\nUnfortunately, I was not able to reproduce this bug:\r\n```ipython\r\nIn [1]: from datasets import load_dataset\r\n ...: ds = load_dataset('wiki_bio')\r\nDownloading: 7.58kB [00:00, 26.3kB/s]\r\nDownloading: 2.71kB [00:00, ?B/s]\r\nUsing custom data configuration default\... | 2021-09-17T16:52:10Z | 2022-08-24T13:09:08Z | 2022-08-24T13:09:08Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ## Describe the bug
Standard process to download and load the wiki_bio dataset causes PermissionError in Windows 10 and 11.
## Steps to reproduce the bug
```python
from datasets import load_dataset
ds = load_dataset('wiki_bio')
```
## Expected results
It is expected that the dataset downloads without any errors.
## Actual results
PermissionError see trace below:
```
Using custom data configuration default
Downloading and preparing dataset wiki_bio/default (download: 318.53 MiB, generated: 736.94 MiB, post-processed: Unknown size, total: 1.03 GiB) to C:\Users\username\.cache\huggingface\datasets\wiki_bio\default\1.1.0\5293ce565954ba965dada626f1e79684e98172d950371d266bf3caaf87e911c9...
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "C:\Users\username\.conda\envs\hf\lib\site-packages\datasets\load.py", line 1112, in load_dataset
builder_instance.download_and_prepare(
File "C:\Users\username\.conda\envs\hf\lib\site-packages\datasets\builder.py", line 644, in download_and_prepare
self._save_info()
File "C:\Users\username\.conda\envs\hf\lib\contextlib.py", line 120, in __exit__
next(self.gen)
File "C:\Users\username\.conda\envs\hf\lib\site-packages\datasets\builder.py", line 598, in incomplete_dir
os.rename(tmp_dir, dirname)
PermissionError: [WinError 5] Access is denied: 'C:\\Users\\username\\.cache\\huggingface\\datasets\\wiki_bio\\default\\1.1.0\\5293ce565954ba965dada626f1e79684e98172d950371d266bf3caaf87e911c9.incomplete' -> 'C:\\Users\\username\\.cache\\huggingface\\datasets\\wiki_bio\\default\\1.1.0\\5293ce565954ba965dada626f1e79684e98172d950371d266bf3caaf87e911c9'
```
By commenting out the os.rename() [L604](https://github.com/huggingface/datasets/blob/master/src/datasets/builder.py#L604) and the shutil.rmtree() [L607](https://github.com/huggingface/datasets/blob/master/src/datasets/builder.py#L607) lines, in my virtual environment, I was able to get the load process to complete, rename the directory manually and then rerun the `load_dataset('wiki_bio')` to get what I needed.
It seems that os.rename() in the `incomplete_dir` content manager is the culprit. Here's another project [Conan](https://github.com/conan-io/conan/issues/6560) with similar issue with os.rename() if it helps debug this issue.
## Environment info
- `datasets` version: 1.12.1
- Platform: Windows-10-10.0.22449-SP0
- Python version: 3.8.12
- PyArrow version: 5.0.0
| {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2937/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2937/timeline | null | completed | null | null | 8,180.282778 | 4,643 |
https://api.github.com/repos/huggingface/datasets/issues/2934 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2934/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2934/comments | https://api.github.com/repos/huggingface/datasets/issues/2934/events | https://github.com/huggingface/datasets/issues/2934 | 999,477,413 | I_kwDODunzps47ktCl | 2,934 | to_tf_dataset keeps a reference to the open data somewhere, causing issues on windows | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"I did some investigation and, as it seems, the bug stems from [this line](https://github.com/huggingface/datasets/blob/8004d7c3e1d74b29c3e5b0d1660331cd26758363/src/datasets/arrow_dataset.py#L325). The lifecycle of the dataset from the linked line is bound to one of the returned `tf.data.Dataset`. So my (hacky) sol... | 2021-09-17T15:26:53Z | 2021-10-13T09:03:23Z | 2021-10-13T09:03:23Z | MEMBER | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | To reproduce:
```python
import datasets as ds
import weakref
import gc
d = ds.load_dataset("mnist", split="train")
ref = weakref.ref(d._data.table)
tfd = d.to_tf_dataset("image", batch_size=1, shuffle=False, label_cols="label")
del tfd, d
gc.collect()
assert ref() is None, "Error: there is at least one reference left"
```
This causes issues because the table holds a reference to an open arrow file that should be closed. So on windows it's not possible to delete or move the arrow file afterwards.
Moreover the CI test of the `to_tf_dataset` method isn't able to clean up the temporary arrow files because of this.
cc @Rocketknight1 | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2934/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2934/timeline | null | completed | null | null | 617.608333 | 4,646 |
https://api.github.com/repos/huggingface/datasets/issues/2932 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2932/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2932/comments | https://api.github.com/repos/huggingface/datasets/issues/2932/events | https://github.com/huggingface/datasets/issues/2932 | 999,317,750 | I_kwDODunzps47kGD2 | 2,932 | Conda build fails | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists... | null | [
"Why 1.9 ?\r\n\r\nhttps://anaconda.org/HuggingFace/datasets currently says 1.11",
"Alright I added 1.12.0 and 1.12.1 and fixed the conda build #2952 "
] | 2021-09-17T12:49:22Z | 2021-09-21T15:31:10Z | 2021-09-21T15:31:10Z | MEMBER | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ## Describe the bug
Current `datasets` version in conda is 1.9 instead of 1.12.
The build of the conda package fails.
| {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2932/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2932/timeline | null | completed | null | null | 98.696667 | 4,648 |
https://api.github.com/repos/huggingface/datasets/issues/2930 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2930/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2930/comments | https://api.github.com/repos/huggingface/datasets/issues/2930/events | https://github.com/huggingface/datasets/issues/2930 | 998,154,311 | I_kwDODunzps47fqBH | 2,930 | Mutable columns argument breaks set_format | {
"avatar_url": "https://avatars.githubusercontent.com/u/12866554?v=4",
"events_url": "https://api.github.com/users/Rocketknight1/events{/privacy}",
"followers_url": "https://api.github.com/users/Rocketknight1/followers",
"following_url": "https://api.github.com/users/Rocketknight1/following{/other_user}",
"gists_url": "https://api.github.com/users/Rocketknight1/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Rocketknight1",
"id": 12866554,
"login": "Rocketknight1",
"node_id": "MDQ6VXNlcjEyODY2NTU0",
"organizations_url": "https://api.github.com/users/Rocketknight1/orgs",
"received_events_url": "https://api.github.com/users/Rocketknight1/received_events",
"repos_url": "https://api.github.com/users/Rocketknight1/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Rocketknight1/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Rocketknight1/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Rocketknight1",
"user_view_type": "public"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/12866554?v=4",
"events_url": "https://api.github.com/users/Rocketknight1/events{/privacy}",
"followers_url": "https://api.github.com/users/Rocketknight1/followers",
"following_url": "https://api.github.com/users/Rocketknight1/following{/other_user}",
"gists_url": "https://api.github.com/users/Rocketknight1/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Rocketknight1",
"id": 12866554,
"login": "Rocketknight1",
"node_id": "MDQ6VXNlcjEyODY2NTU0",
"organizations_url": "https://api.github.com/users/Rocketknight1/orgs",
"received_events_url": "https://api.github.com/users/Rocketknight1/received_events",
"repos_url": "https://api.github.com/users/Rocketknight1/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Rocketknight1/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Rocketknight1/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Rocketknight1",
"user_view_type": "public"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/12866554?v=4",
"events_url": "https://api.github.com/users/Rocketknight1/events{/privacy}",
"followers_url": "https://api.github.com/users/Rocketknight1/followers",
"following_url": "https://api.github.com/users/Rocketknight1/following{/other_... | null | [
"Pushed a fix to my branch #2731 "
] | 2021-09-16T12:27:22Z | 2021-09-16T13:50:53Z | 2021-09-16T13:50:53Z | MEMBER | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ## Describe the bug
If you pass a mutable list to the `columns` argument of `set_format` and then change the list afterwards, the returned columns also change.
## Steps to reproduce the bug
```python
from datasets import load_dataset
dataset = load_dataset("glue", "cola")
column_list = ["idx", "label"]
dataset.set_format("python", columns=column_list)
column_list[1] = "foo" # Change the list after we call `set_format`
dataset['train'][:4].keys()
```
## Expected results
```python
dict_keys(['idx', 'label'])
```
## Actual results
```python
dict_keys(['idx'])
``` | {
"avatar_url": "https://avatars.githubusercontent.com/u/12866554?v=4",
"events_url": "https://api.github.com/users/Rocketknight1/events{/privacy}",
"followers_url": "https://api.github.com/users/Rocketknight1/followers",
"following_url": "https://api.github.com/users/Rocketknight1/following{/other_user}",
"gists_url": "https://api.github.com/users/Rocketknight1/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Rocketknight1",
"id": 12866554,
"login": "Rocketknight1",
"node_id": "MDQ6VXNlcjEyODY2NTU0",
"organizations_url": "https://api.github.com/users/Rocketknight1/orgs",
"received_events_url": "https://api.github.com/users/Rocketknight1/received_events",
"repos_url": "https://api.github.com/users/Rocketknight1/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Rocketknight1/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Rocketknight1/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Rocketknight1",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2930/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2930/timeline | null | completed | null | null | 1.391944 | 4,650 |
https://api.github.com/repos/huggingface/datasets/issues/2927 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2927/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2927/comments | https://api.github.com/repos/huggingface/datasets/issues/2927/events | https://github.com/huggingface/datasets/issues/2927 | 997,654,680 | I_kwDODunzps47dwCY | 2,927 | Datasets 1.12 dataset.filter TypeError: get_indices_from_mask_function() got an unexpected keyword argument | {
"avatar_url": "https://avatars.githubusercontent.com/u/2000204?v=4",
"events_url": "https://api.github.com/users/timothyjlaurent/events{/privacy}",
"followers_url": "https://api.github.com/users/timothyjlaurent/followers",
"following_url": "https://api.github.com/users/timothyjlaurent/following{/other_user}",
"gists_url": "https://api.github.com/users/timothyjlaurent/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/timothyjlaurent",
"id": 2000204,
"login": "timothyjlaurent",
"node_id": "MDQ6VXNlcjIwMDAyMDQ=",
"organizations_url": "https://api.github.com/users/timothyjlaurent/orgs",
"received_events_url": "https://api.github.com/users/timothyjlaurent/received_events",
"repos_url": "https://api.github.com/users/timothyjlaurent/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/timothyjlaurent/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/timothyjlaurent/subscriptions",
"type": "User",
"url": "https://api.github.com/users/timothyjlaurent",
"user_view_type": "public"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists... | null | [
"Thanks for reporting, I'm looking into it :)",
"Fixed by #2950."
] | 2021-09-16T01:14:02Z | 2021-09-20T16:23:22Z | 2021-09-20T16:23:21Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ## Describe the bug
Upgrading to 1.12 caused `dataset.filter` call to fail with
> get_indices_from_mask_function() got an unexpected keyword argument valid_rel_labels
## Steps to reproduce the bug
```pythondef
filter_good_rows(
ex: Dict,
valid_rel_labels: Set[str],
valid_ner_labels: Set[str],
tokenizer: PreTrainedTokenizerFast,
) -> bool:
"""Get the good rows"""
encoding = get_encoding_for_text(text=ex["text"], tokenizer=tokenizer)
ex["encoding"] = encoding
for relation in ex["relations"]:
if not is_valid_relation(relation, valid_rel_labels):
return False
for span in ex["spans"]:
if not is_valid_span(span, valid_ner_labels, encoding):
return False
return True
def get_dataset():
loader_path = str(Path(__file__).parent / "prodigy_dataset_builder.py")
ds = load_dataset(
loader_path,
name="prodigy-dataset",
data_files=sorted(file_paths),
cache_dir=cache_dir,
)["train"]
valid_ner_labels = set(vocab.ner_category)
valid_relations = set(vocab.relation_types.keys())
ds = ds.filter(
filter_good_rows,
fn_kwargs=dict(
valid_rel_labels=valid_relations,
valid_ner_labels=valid_ner_labels,
tokenizer=vocab.tokenizer,
),
keep_in_memory=True,
num_proc=num_proc,
)
```
`ds` is a `DatasetDict` produced by a jsonl dataset.
This runs fine on 1.11 but fails on 1.12
**Stack Trace**
## Expected results
I expect 1.12 datasets filter to filter the dataset without raising as it does on 1.11
## Actual results
```
tf_ner_rel_lib/dataset.py:695: in load_prodigy_arrow_datasets_from_jsonl
ds = ds.filter(
../../../../.pyenv/versions/tf_ner_rel_lib/lib/python3.8/site-packages/datasets/arrow_dataset.py:185: in wrapper
out: Union["Dataset", "DatasetDict"] = func(self, *args, **kwargs)
../../../../.pyenv/versions/tf_ner_rel_lib/lib/python3.8/site-packages/datasets/fingerprint.py:398: in wrapper
out = func(self, *args, **kwargs)
../../../../.pyenv/versions/tf_ner_rel_lib/lib/python3.8/site-packages/datasets/arrow_dataset.py:2169: in filter
indices = self.map(
../../../../.pyenv/versions/tf_ner_rel_lib/lib/python3.8/site-packages/datasets/arrow_dataset.py:1686: in map
return self._map_single(
../../../../.pyenv/versions/tf_ner_rel_lib/lib/python3.8/site-packages/datasets/arrow_dataset.py:185: in wrapper
out: Union["Dataset", "DatasetDict"] = func(self, *args, **kwargs)
../../../../.pyenv/versions/tf_ner_rel_lib/lib/python3.8/site-packages/datasets/fingerprint.py:398: in wrapper
out = func(self, *args, **kwargs)
../../../../.pyenv/versions/tf_ner_rel_lib/lib/python3.8/site-packages/datasets/arrow_dataset.py:2048: in _map_single
batch = apply_function_on_filtered_inputs(
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
inputs = {'_input_hash': [2108817714, 1477695082, -1021597032, 2130671338, -1260483858, -1203431639, ...], '_task_hash': [18070...ons', 'relations', 'relations', ...], 'answer': ['accept', 'accept', 'accept', 'accept', 'accept', 'accept', ...], ...}
indices = [0, 1, 2, 3, 4, 5, ...], check_same_num_examples = False, offset = 0
def apply_function_on_filtered_inputs(inputs, indices, check_same_num_examples=False, offset=0):
"""Utility to apply the function on a selection of columns."""
nonlocal update_data
fn_args = [inputs] if input_columns is None else [inputs[col] for col in input_columns]
if offset == 0:
effective_indices = indices
else:
effective_indices = [i + offset for i in indices] if isinstance(indices, list) else indices + offset
processed_inputs = (
> function(*fn_args, effective_indices, **fn_kwargs) if with_indices else function(*fn_args, **fn_kwargs)
)
E TypeError: get_indices_from_mask_function() got an unexpected keyword argument 'valid_rel_labels'
../../../../.pyenv/versions/tf_ner_rel_lib/lib/python3.8/site-packages/datasets/arrow_dataset.py:1939: TypeError
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.12.1
- Platform: Mac
- Python version: 3.8.9
- PyArrow version: pyarrow==5.0.0
| {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2927/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2927/timeline | null | completed | null | null | 111.155278 | 4,653 |
https://api.github.com/repos/huggingface/datasets/issues/2924 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2924/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2924/comments | https://api.github.com/repos/huggingface/datasets/issues/2924/events | https://github.com/huggingface/datasets/issues/2924 | 997,378,113 | I_kwDODunzps47cshB | 2,924 | "File name too long" error for file locks | {
"avatar_url": "https://avatars.githubusercontent.com/u/184949?v=4",
"events_url": "https://api.github.com/users/gar1t/events{/privacy}",
"followers_url": "https://api.github.com/users/gar1t/followers",
"following_url": "https://api.github.com/users/gar1t/following{/other_user}",
"gists_url": "https://api.github.com/users/gar1t/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/gar1t",
"id": 184949,
"login": "gar1t",
"node_id": "MDQ6VXNlcjE4NDk0OQ==",
"organizations_url": "https://api.github.com/users/gar1t/orgs",
"received_events_url": "https://api.github.com/users/gar1t/received_events",
"repos_url": "https://api.github.com/users/gar1t/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/gar1t/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/gar1t/subscriptions",
"type": "User",
"url": "https://api.github.com/users/gar1t",
"user_view_type": "public"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
... | null | [
"Hi, the filename here is less than 255\r\n```python\r\n>>> len(\"_home_garrett_.cache_huggingface_datasets_csv_test-7c856aea083a7043_0.0.0_9144e0a4e8435090117cea53e6c7537173ef2304525df4a077c435d8ee7828ff.incomplete.lock\")\r\n154\r\n```\r\nso not sure why it's considered too long for your filesystem.\r\n(also note... | 2021-09-15T18:16:50Z | 2023-12-08T13:39:51Z | 2021-10-29T09:42:24Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ## Describe the bug
Getting the following error when calling `load_dataset("gar1t/test")`:
```
OSError: [Errno 36] File name too long: '<user>/.cache/huggingface/datasets/_home_garrett_.cache_huggingface_datasets_csv_test-7c856aea083a7043_0.0.0_9144e0a4e8435090117cea53e6c7537173ef2304525df4a077c435d8ee7828ff.incomplete.lock'
```
## Steps to reproduce the bug
Where the user cache dir (e.g. `~/.cache`) is on a file system that limits filenames to 255 chars (e.g. ext4):
```python
from datasets import load_dataset
load_dataset("gar1t/test")
```
## Expected results
Expect the function to return without an error.
## Actual results
```
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "<python_venv>/lib/python3.9/site-packages/datasets/load.py", line 1112, in load_dataset
builder_instance.download_and_prepare(
File "<python_venv>/lib/python3.9/site-packages/datasets/builder.py", line 644, in download_and_prepare
self._save_info()
File "<python_venv>/lib/python3.9/site-packages/datasets/builder.py", line 765, in _save_info
with FileLock(lock_path):
File "<python_venv>/lib/python3.9/site-packages/datasets/utils/filelock.py", line 323, in __enter__
self.acquire()
File "<python_venv>/lib/python3.9/site-packages/datasets/utils/filelock.py", line 272, in acquire
self._acquire()
File "<python_venv>/lib/python3.9/site-packages/datasets/utils/filelock.py", line 403, in _acquire
fd = os.open(self._lock_file, open_mode)
OSError: [Errno 36] File name too long: '<user>/.cache/huggingface/datasets/_home_garrett_.cache_huggingface_datasets_csv_test-7c856aea083a7043_0.0.0_9144e0a4e8435090117cea53e6c7537173ef2304525df4a077c435d8ee7828ff.incomplete.lock'
```
## Environment info
- `datasets` version: 1.12.1
- Platform: Linux-5.11.0-27-generic-x86_64-with-glibc2.31
- Python version: 3.9.7
- PyArrow version: 5.0.0
| {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 1,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2924/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2924/timeline | null | completed | null | null | 1,047.426111 | 4,656 |
https://api.github.com/repos/huggingface/datasets/issues/2923 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2923/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2923/comments | https://api.github.com/repos/huggingface/datasets/issues/2923/events | https://github.com/huggingface/datasets/issues/2923 | 997,351,590 | I_kwDODunzps47cmCm | 2,923 | Loading an autonlp dataset raises in normal mode but not in streaming mode | {
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://api.github.com/users/severo/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/severo",
"id": 1676121,
"login": "severo",
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"organizations_url": "https://api.github.com/users/severo/orgs",
"received_events_url": "https://api.github.com/users/severo/received_events",
"repos_url": "https://api.github.com/users/severo/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/severo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/severo/subscriptions",
"type": "User",
"url": "https://api.github.com/users/severo",
"user_view_type": "public"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
},
{
"color": "E5583E",
"default": false,
"descrip... | closed | false | null | [] | null | [
"Closing since autonlp dataset are now supported"
] | 2021-09-15T17:44:38Z | 2022-04-12T10:09:40Z | 2022-04-12T10:09:39Z | COLLABORATOR | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ## Describe the bug
The same dataset (from autonlp) raises an error in normal mode, but does not raise in streaming mode
## Steps to reproduce the bug
```python
from datasets import load_dataset
load_dataset("severo/autonlp-data-sentiment_detection-3c8bcd36", split="train", streaming=False)
## raises an error
load_dataset("severo/autonlp-data-sentiment_detection-3c8bcd36", split="train", streaming=True)
## does not raise an error
```
## Expected results
Both calls should raise the same error
## Actual results
Call with streaming=False:
```
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 5825.42it/s]
Using custom data configuration autonlp-data-sentiment_detection-3c8bcd36-fe30267462d1d42b
Downloading and preparing dataset json/autonlp-data-sentiment_detection-3c8bcd36 to /home/slesage/.cache/huggingface/datasets/json/autonlp-data-sentiment_detection-3c8bcd36-fe30267462d1d42b/0.0.0/d75ead8d5cfcbe67495df0f89bd262f0023257fbbbd94a730313295f3d756d50...
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 5/5 [00:00<00:00, 15923.71it/s]
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 5/5 [00:00<00:00, 3346.88it/s]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.8/site-packages/datasets/load.py", line 1112, in load_dataset
builder_instance.download_and_prepare(
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.8/site-packages/datasets/builder.py", line 636, in download_and_prepare
self._download_and_prepare(
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.8/site-packages/datasets/builder.py", line 726, in _download_and_prepare
self._prepare_split(split_generator, **prepare_split_kwargs)
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.8/site-packages/datasets/builder.py", line 1187, in _prepare_split
writer.write_table(table)
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.8/site-packages/datasets/arrow_writer.py", line 418, in write_table
pa_table = pa.Table.from_arrays([pa_table[name] for name in self._schema.names], schema=self._schema)
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.8/site-packages/datasets/arrow_writer.py", line 418, in <listcomp>
pa_table = pa.Table.from_arrays([pa_table[name] for name in self._schema.names], schema=self._schema)
File "pyarrow/table.pxi", line 1249, in pyarrow.lib.Table.__getitem__
File "pyarrow/table.pxi", line 1825, in pyarrow.lib.Table.column
File "pyarrow/table.pxi", line 1800, in pyarrow.lib.Table._ensure_integer_index
KeyError: 'Field "splits" does not exist in table schema'
```
Call with `streaming=False`:
```
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 6000.43it/s]
Using custom data configuration autonlp-data-sentiment_detection-3c8bcd36-fe30267462d1d42b
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 5/5 [00:00<00:00, 46916.15it/s]
100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 5/5 [00:00<00:00, 148734.18it/s]
```
## Environment info
- `datasets` version: 1.12.1.dev0
- Platform: Linux-5.11.0-1017-aws-x86_64-with-glibc2.29
- Python version: 3.8.11
- PyArrow version: 4.0.1
| {
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://api.github.com/users/severo/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/severo",
"id": 1676121,
"login": "severo",
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"organizations_url": "https://api.github.com/users/severo/orgs",
"received_events_url": "https://api.github.com/users/severo/received_events",
"repos_url": "https://api.github.com/users/severo/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/severo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/severo/subscriptions",
"type": "User",
"url": "https://api.github.com/users/severo",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2923/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2923/timeline | null | completed | null | null | 5,008.416944 | 4,657 |
https://api.github.com/repos/huggingface/datasets/issues/2921 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2921/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2921/comments | https://api.github.com/repos/huggingface/datasets/issues/2921/events | https://github.com/huggingface/datasets/issues/2921 | 997,325,424 | I_kwDODunzps47cfpw | 2,921 | Using a list of multi-dim numpy arrays raises an error "can only convert 1-dimensional array values" | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
} | [] | closed | false | null | [] | null | [] | 2021-09-15T17:12:11Z | 2021-09-15T17:21:45Z | 2021-09-15T17:21:45Z | MEMBER | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | This error has been introduced in https://github.com/huggingface/datasets/pull/2361
To reproduce:
```python
import numpy as np
from datasets import Dataset
d = Dataset.from_dict({"a": [np.zeros((2, 2))]})
```
raises
```python
Traceback (most recent call last):
File "playground/ttest.py", line 5, in <module>
d = Dataset.from_dict({"a": [np.zeros((2, 2))]}).with_format("torch")
File "/Users/quentinlhoest/Desktop/hf/nlp/src/datasets/arrow_dataset.py", line 458, in from_dict
pa_table = InMemoryTable.from_pydict(mapping=mapping)
File "/Users/quentinlhoest/Desktop/hf/nlp/src/datasets/table.py", line 365, in from_pydict
return cls(pa.Table.from_pydict(*args, **kwargs))
File "pyarrow/table.pxi", line 1639, in pyarrow.lib.Table.from_pydict
File "pyarrow/array.pxi", line 332, in pyarrow.lib.asarray
File "pyarrow/array.pxi", line 223, in pyarrow.lib.array
File "pyarrow/array.pxi", line 110, in pyarrow.lib._handle_arrow_array_protocol
File "/Users/quentinlhoest/Desktop/hf/nlp/src/datasets/arrow_writer.py", line 107, in __arrow_array__
out = pa.array(self.data, type=type)
File "pyarrow/array.pxi", line 306, in pyarrow.lib.array
File "pyarrow/array.pxi", line 39, in pyarrow.lib._sequence_to_array
File "pyarrow/error.pxi", line 143, in pyarrow.lib.pyarrow_internal_check_status
File "pyarrow/error.pxi", line 99, in pyarrow.lib.check_status
pyarrow.lib.ArrowInvalid: Can only convert 1-dimensional array values | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2921/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2921/timeline | null | completed | null | null | 0.159444 | 4,659 |
https://api.github.com/repos/huggingface/datasets/issues/2919 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2919/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2919/comments | https://api.github.com/repos/huggingface/datasets/issues/2919/events | https://github.com/huggingface/datasets/issues/2919 | 997,127,487 | I_kwDODunzps47bvU_ | 2,919 | Unwanted progress bars when accessing examples | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
} | [] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists... | null | [
"doing a patch release now :)"
] | 2021-09-15T14:05:10Z | 2021-09-15T17:21:49Z | 2021-09-15T17:18:23Z | MEMBER | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | When accessing examples from a dataset formatted for pytorch, some progress bars appear when accessing examples:
```python
In [1]: import datasets as ds
In [2]: d = ds.Dataset.from_dict({"a": [0, 1, 2]}).with_format("torch")
In [3]: d[0]
100%|████████████████████████████████| 1/1 [00:00<00:00, 3172.70it/s]
Out[3]: {'a': tensor(0)}
```
This is because the pytorch formatter calls `map_nested` that uses progress bars
cc @sgugger | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
} | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2919/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2919/timeline | null | completed | null | null | 3.220278 | 4,661 |
https://api.github.com/repos/huggingface/datasets/issues/2918 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2918/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2918/comments | https://api.github.com/repos/huggingface/datasets/issues/2918/events | https://github.com/huggingface/datasets/issues/2918 | 997,063,347 | I_kwDODunzps47bfqz | 2,918 | `Can not decode content-encoding: gzip` when loading `scitldr` dataset with streaming | {
"avatar_url": "https://avatars.githubusercontent.com/u/33657802?v=4",
"events_url": "https://api.github.com/users/SBrandeis/events{/privacy}",
"followers_url": "https://api.github.com/users/SBrandeis/followers",
"following_url": "https://api.github.com/users/SBrandeis/following{/other_user}",
"gists_url": "https://api.github.com/users/SBrandeis/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/SBrandeis",
"id": 33657802,
"login": "SBrandeis",
"node_id": "MDQ6VXNlcjMzNjU3ODAy",
"organizations_url": "https://api.github.com/users/SBrandeis/orgs",
"received_events_url": "https://api.github.com/users/SBrandeis/received_events",
"repos_url": "https://api.github.com/users/SBrandeis/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/SBrandeis/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/SBrandeis/subscriptions",
"type": "User",
"url": "https://api.github.com/users/SBrandeis",
"user_view_type": "public"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
},
{
"color": "fef2c0",
"default": false,
"descrip... | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [
"Hi @SBrandeis, thanks for reporting! ^^\r\n\r\nI think this is an issue with `fsspec`: https://github.com/intake/filesystem_spec/issues/389\r\n\r\nI will ask them if they are planning to fix it...",
"Code to reproduce the bug: `ClientPayloadError: 400, message='Can not decode content-encoding: gzip'`\r\n```pytho... | 2021-09-15T13:06:07Z | 2021-12-01T08:15:00Z | 2021-12-01T08:15:00Z | CONTRIBUTOR | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ## Describe the bug
Trying to load the `"FullText"` config of the `"scitldr"` dataset with `streaming=True` raises an error from `aiohttp`:
```python
ClientPayloadError: 400, message='Can not decode content-encoding: gzip'
```
cc @lhoestq
## Steps to reproduce the bug
```python
from datasets import load_dataset
iter_dset = iter(
load_dataset("scitldr", name="FullText", split="test", streaming=True)
)
next(iter_dset)
```
## Expected results
Returns the first sample of the dataset
## Actual results
Calling `__next__` crashes with the following Traceback:
```python
----> 1 next(dset_iter)
~\miniconda3\envs\datasets\lib\site-packages\datasets\iterable_dataset.py in __iter__(self)
339
340 def __iter__(self):
--> 341 for key, example in self._iter():
342 if self.features:
343 # we encode the example for ClassLabel feature types for example
~\miniconda3\envs\datasets\lib\site-packages\datasets\iterable_dataset.py in _iter(self)
336 else:
337 ex_iterable = self._ex_iterable
--> 338 yield from ex_iterable
339
340 def __iter__(self):
~\miniconda3\envs\datasets\lib\site-packages\datasets\iterable_dataset.py in __iter__(self)
76
77 def __iter__(self):
---> 78 for key, example in self.generate_examples_fn(**self.kwargs):
79 yield key, example
80
~\.cache\huggingface\modules\datasets_modules\datasets\scitldr\72d6e2195786c57e1d343066fb2cc4f93ea39c5e381e53e6ae7c44bbfd1f05ef\scitldr.py in _generate_examples(self, filepath, split)
162
163 with open(filepath, encoding="utf-8") as f:
--> 164 for id_, row in enumerate(f):
165 data = json.loads(row)
166 if self.config.name == "AIC":
~\miniconda3\envs\datasets\lib\site-packages\fsspec\implementations\http.py in read(self, length)
496 else:
497 length = min(self.size - self.loc, length)
--> 498 return super().read(length)
499
500 async def async_fetch_all(self):
~\miniconda3\envs\datasets\lib\site-packages\fsspec\spec.py in read(self, length)
1481 # don't even bother calling fetch
1482 return b""
-> 1483 out = self.cache._fetch(self.loc, self.loc + length)
1484 self.loc += len(out)
1485 return out
~\miniconda3\envs\datasets\lib\site-packages\fsspec\caching.py in _fetch(self, start, end)
378 elif start < self.start:
379 if self.end - end > self.blocksize:
--> 380 self.cache = self.fetcher(start, bend)
381 self.start = start
382 else:
~\miniconda3\envs\datasets\lib\site-packages\fsspec\asyn.py in wrapper(*args, **kwargs)
86 def wrapper(*args, **kwargs):
87 self = obj or args[0]
---> 88 return sync(self.loop, func, *args, **kwargs)
89
90 return wrapper
~\miniconda3\envs\datasets\lib\site-packages\fsspec\asyn.py in sync(loop, func, timeout, *args, **kwargs)
67 raise FSTimeoutError
68 if isinstance(result[0], BaseException):
---> 69 raise result[0]
70 return result[0]
71
~\miniconda3\envs\datasets\lib\site-packages\fsspec\asyn.py in _runner(event, coro, result, timeout)
23 coro = asyncio.wait_for(coro, timeout=timeout)
24 try:
---> 25 result[0] = await coro
26 except Exception as ex:
27 result[0] = ex
~\miniconda3\envs\datasets\lib\site-packages\fsspec\implementations\http.py in async_fetch_range(self, start, end)
538 if r.status == 206:
539 # partial content, as expected
--> 540 out = await r.read()
541 elif "Content-Length" in r.headers:
542 cl = int(r.headers["Content-Length"])
~\miniconda3\envs\datasets\lib\site-packages\aiohttp\client_reqrep.py in read(self)
1030 if self._body is None:
1031 try:
-> 1032 self._body = await self.content.read()
1033 for trace in self._traces:
1034 await trace.send_response_chunk_received(
~\miniconda3\envs\datasets\lib\site-packages\aiohttp\streams.py in read(self, n)
342 async def read(self, n: int = -1) -> bytes:
343 if self._exception is not None:
--> 344 raise self._exception
345
346 # migration problem; with DataQueue you have to catch
ClientPayloadError: 400, message='Can not decode content-encoding: gzip'
```
## Environment info
- `datasets` version: 1.12.0
- Platform: Windows-10-10.0.19041-SP0
- Python version: 3.8.5
- PyArrow version: 2.0.0
- aiohttp version: 3.7.4.post0
| {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2918/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2918/timeline | null | completed | null | null | 1,843.148056 | 4,662 |
https://api.github.com/repos/huggingface/datasets/issues/2917 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2917/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2917/comments | https://api.github.com/repos/huggingface/datasets/issues/2917/events | https://github.com/huggingface/datasets/issues/2917 | 997,041,658 | I_kwDODunzps47baX6 | 2,917 | windows download abnormal | {
"avatar_url": "https://avatars.githubusercontent.com/u/52347799?v=4",
"events_url": "https://api.github.com/users/wei1826676931/events{/privacy}",
"followers_url": "https://api.github.com/users/wei1826676931/followers",
"following_url": "https://api.github.com/users/wei1826676931/following{/other_user}",
"gists_url": "https://api.github.com/users/wei1826676931/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/wei1826676931",
"id": 52347799,
"login": "wei1826676931",
"node_id": "MDQ6VXNlcjUyMzQ3Nzk5",
"organizations_url": "https://api.github.com/users/wei1826676931/orgs",
"received_events_url": "https://api.github.com/users/wei1826676931/received_events",
"repos_url": "https://api.github.com/users/wei1826676931/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/wei1826676931/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/wei1826676931/subscriptions",
"type": "User",
"url": "https://api.github.com/users/wei1826676931",
"user_view_type": "public"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"Hi ! Is there some kind of proxy that is configured in your browser that gives you access to internet ? If it's the case it could explain why it doesn't work in the code, since the proxy wouldn't be used",
"It is indeed an agency problem, thank you very, very much",
"Let me know if you have other questions :)\... | 2021-09-15T12:45:35Z | 2021-09-16T17:17:48Z | 2021-09-16T17:17:48Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ## Describe the bug
The script clearly exists (accessible from the browser), but the script download fails on windows. Then I tried it again and it can be downloaded normally on linux. why??
## Steps to reproduce the bug
```python3.7 + windows
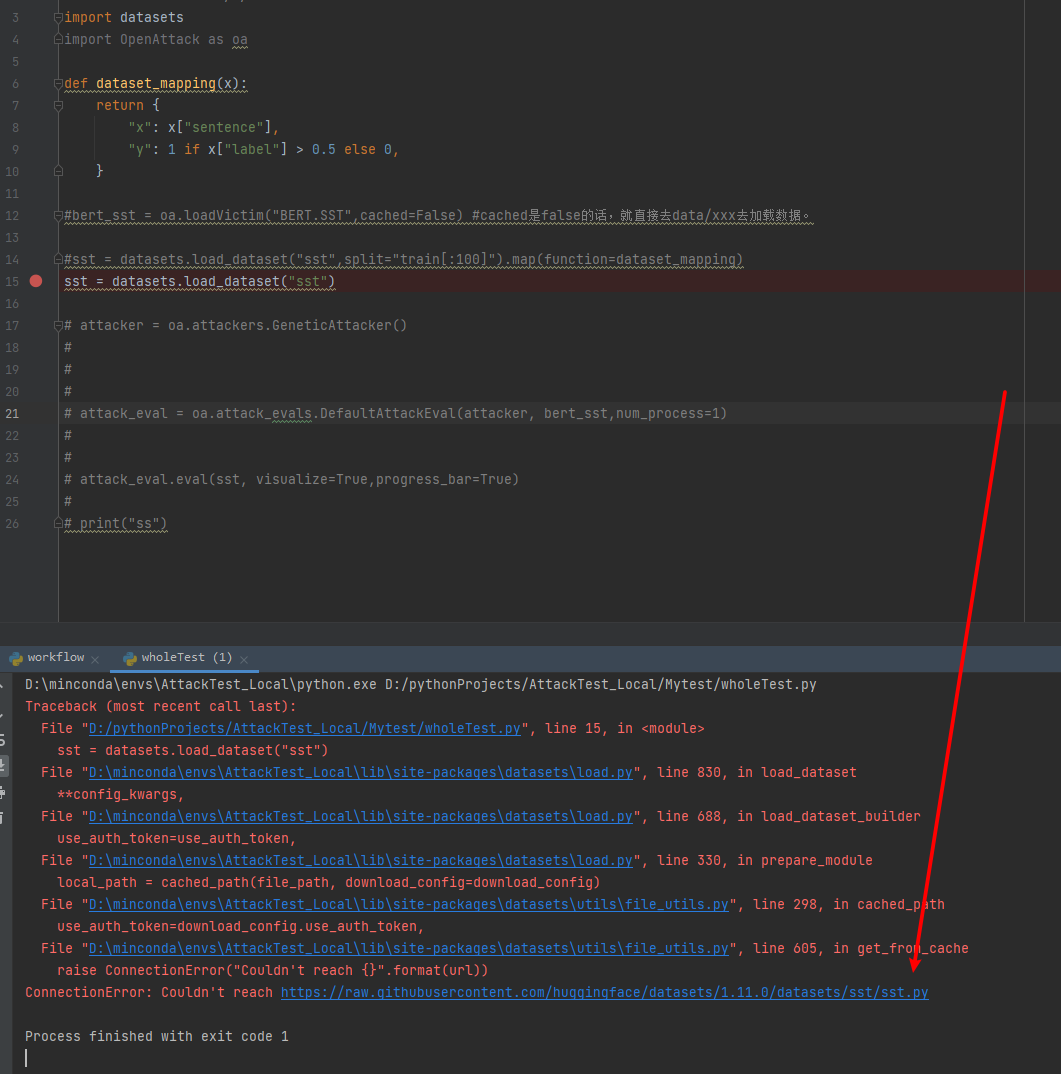
# Sample code to reproduce the bug
```
## Expected results
It can be downloaded normally.
## Actual results
it cann't
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version:1.11.0
- Platform:windows
- Python version:3.7
- PyArrow version:
| {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2917/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2917/timeline | null | completed | null | null | 28.536944 | 4,663 |
https://api.github.com/repos/huggingface/datasets/issues/2914 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2914/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2914/comments | https://api.github.com/repos/huggingface/datasets/issues/2914/events | https://github.com/huggingface/datasets/issues/2914 | 996,770,168 | I_kwDODunzps47aYF4 | 2,914 | Having a dependency defining fsspec entrypoint raises an AttributeError when importing datasets | {
"avatar_url": "https://avatars.githubusercontent.com/u/3969168?v=4",
"events_url": "https://api.github.com/users/pierre-godard/events{/privacy}",
"followers_url": "https://api.github.com/users/pierre-godard/followers",
"following_url": "https://api.github.com/users/pierre-godard/following{/other_user}",
"gists_url": "https://api.github.com/users/pierre-godard/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/pierre-godard",
"id": 3969168,
"login": "pierre-godard",
"node_id": "MDQ6VXNlcjM5NjkxNjg=",
"organizations_url": "https://api.github.com/users/pierre-godard/orgs",
"received_events_url": "https://api.github.com/users/pierre-godard/received_events",
"repos_url": "https://api.github.com/users/pierre-godard/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/pierre-godard/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/pierre-godard/subscriptions",
"type": "User",
"url": "https://api.github.com/users/pierre-godard",
"user_view_type": "public"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"Closed by #2915."
] | 2021-09-15T07:54:06Z | 2021-09-15T16:49:17Z | 2021-09-15T16:49:16Z | CONTRIBUTOR | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ## Describe the bug
In one of my project, I defined a custom fsspec filesystem with an entrypoint.
My guess is that by doing so, a variable named `spec` is created in the module `fsspec` (created by entering a for loop as there are entrypoints defined, see the loop in question [here](https://github.com/intake/filesystem_spec/blob/0589358d8a029ed6b60d031018f52be2eb721291/fsspec/__init__.py#L55)).
So that `fsspec.spec`, that was previously referring to the `spec` submodule, is now referring to that `spec` variable.
This make the import of datasets failing as it is using that `fsspec.spec`.
## Steps to reproduce the bug
I could reproduce the bug with a dummy poetry project.
Here is the pyproject.toml:
```toml
[tool.poetry]
name = "debug-datasets"
version = "0.1.0"
description = ""
authors = ["Pierre Godard"]
[tool.poetry.dependencies]
python = "^3.8"
datasets = "^1.11.0"
[tool.poetry.dev-dependencies]
[build-system]
requires = ["poetry-core>=1.0.0"]
build-backend = "poetry.core.masonry.api"
[tool.poetry.plugins."fsspec.specs"]
"file2" = "fsspec.implementations.local.LocalFileSystem"
```
The only other file being a `debug_datasets/__init__.py` empty file.
The overall structure of the project is as follows:
```
.
├── pyproject.toml
└── debug_datasets
└── __init__.py
```
Then, within the project folder run:
```
poetry install
poetry run python
```
And in the python interpreter, try to import `datasets`:
```
import datasets
```
## Expected results
The import should run successfully.
## Actual results
Here is the trace of the error I get:
```
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/godarpi/.cache/pypoetry/virtualenvs/debug-datasets-JuFzTKL--py3.8/lib/python3.8/site-packages/datasets/__init__.py", line 33, in <module>
from .arrow_dataset import Dataset, concatenate_datasets
File "/home/godarpi/.cache/pypoetry/virtualenvs/debug-datasets-JuFzTKL--py3.8/lib/python3.8/site-packages/datasets/arrow_dataset.py", line 48, in <module>
from .filesystems import extract_path_from_uri, is_remote_filesystem
File "/home/godarpi/.cache/pypoetry/virtualenvs/debug-datasets-JuFzTKL--py3.8/lib/python3.8/site-packages/datasets/filesystems/__init__.py", line 30, in <module>
def is_remote_filesystem(fs: fsspec.spec.AbstractFileSystem) -> bool:
AttributeError: 'EntryPoint' object has no attribute 'AbstractFileSystem'
```
## Suggested fix
`datasets/filesystems/__init__.py`, line 30, replace:
```
def is_remote_filesystem(fs: fsspec.spec.AbstractFileSystem) -> bool:
```
by:
```
def is_remote_filesystem(fs: fsspec.AbstractFileSystem) -> bool:
```
I will come up with a PR soon if this effectively solves the issue.
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.11.0
- Platform: WSL2 (Ubuntu 20.04.1 LTS)
- Python version: 3.8.5
- PyArrow version: 5.0.0
- `fsspec` version: 2021.8.1
| {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2914/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2914/timeline | null | completed | null | null | 8.919444 | 4,666 |
https://api.github.com/repos/huggingface/datasets/issues/2913 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2913/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2913/comments | https://api.github.com/repos/huggingface/datasets/issues/2913/events | https://github.com/huggingface/datasets/issues/2913 | 996,436,368 | I_kwDODunzps47ZGmQ | 2,913 | timit_asr dataset only includes one text phrase | {
"avatar_url": "https://avatars.githubusercontent.com/u/39107794?v=4",
"events_url": "https://api.github.com/users/margotwagner/events{/privacy}",
"followers_url": "https://api.github.com/users/margotwagner/followers",
"following_url": "https://api.github.com/users/margotwagner/following{/other_user}",
"gists_url": "https://api.github.com/users/margotwagner/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/margotwagner",
"id": 39107794,
"login": "margotwagner",
"node_id": "MDQ6VXNlcjM5MTA3Nzk0",
"organizations_url": "https://api.github.com/users/margotwagner/orgs",
"received_events_url": "https://api.github.com/users/margotwagner/received_events",
"repos_url": "https://api.github.com/users/margotwagner/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/margotwagner/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/margotwagner/subscriptions",
"type": "User",
"url": "https://api.github.com/users/margotwagner",
"user_view_type": "public"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"Hi @margotwagner, \r\nThis bug was fixed in #1995. Upgrading the datasets should work (min v1.8.0 ideally)",
"Hi @margotwagner,\r\n\r\nYes, as @bhavitvyamalik has commented, this bug was fixed in `datasets` version 1.5.0. You need to update it, as your current version is 1.4.1:\r\n> Environment info\r\n> - `data... | 2021-09-14T21:06:07Z | 2021-09-15T08:05:19Z | 2021-09-15T08:05:18Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ## Describe the bug
The dataset 'timit_asr' only includes one text phrase. It only includes the transcription "Would such an act of refusal be useful?" multiple times rather than different phrases.
## Steps to reproduce the bug
Note: I am following the tutorial https://huggingface.co/blog/fine-tune-wav2vec2-english
1. Install the dataset and other packages
```python
!pip install datasets>=1.5.0
!pip install transformers==4.4.0
!pip install soundfile
!pip install jiwer
```
2. Load the dataset
```python
from datasets import load_dataset, load_metric
timit = load_dataset("timit_asr")
```
3. Remove columns that we don't want
```python
timit = timit.remove_columns(["phonetic_detail", "word_detail", "dialect_region", "id", "sentence_type", "speaker_id"])
```
4. Write a short function to display some random samples of the dataset.
```python
from datasets import ClassLabel
import random
import pandas as pd
from IPython.display import display, HTML
def show_random_elements(dataset, num_examples=10):
assert num_examples <= len(dataset), "Can't pick more elements than there are in the dataset."
picks = []
for _ in range(num_examples):
pick = random.randint(0, len(dataset)-1)
while pick in picks:
pick = random.randint(0, len(dataset)-1)
picks.append(pick)
df = pd.DataFrame(dataset[picks])
display(HTML(df.to_html()))
show_random_elements(timit["train"].remove_columns(["file"]))
```
## Expected results
10 random different transcription phrases.
## Actual results
10 of the same transcription phrase "Would such an act of refusal be useful?"
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.4.1
- Platform: macOS-10.15.7-x86_64-i386-64bit
- Python version: 3.8.5
- PyArrow version: not listed
| {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2913/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2913/timeline | null | completed | null | null | 10.986389 | 4,667 |
https://api.github.com/repos/huggingface/datasets/issues/2902 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2902/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2902/comments | https://api.github.com/repos/huggingface/datasets/issues/2902/events | https://github.com/huggingface/datasets/issues/2902 | 995,254,216 | MDU6SXNzdWU5OTUyNTQyMTY= | 2,902 | Add WIT Dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/32437151?v=4",
"events_url": "https://api.github.com/users/nateraw/events{/privacy}",
"followers_url": "https://api.github.com/users/nateraw/followers",
"following_url": "https://api.github.com/users/nateraw/following{/other_user}",
"gists_url": "https://api.github.com/users/nateraw/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/nateraw",
"id": 32437151,
"login": "nateraw",
"node_id": "MDQ6VXNlcjMyNDM3MTUx",
"organizations_url": "https://api.github.com/users/nateraw/orgs",
"received_events_url": "https://api.github.com/users/nateraw/received_events",
"repos_url": "https://api.github.com/users/nateraw/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/nateraw/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/nateraw/subscriptions",
"type": "User",
"url": "https://api.github.com/users/nateraw",
"user_view_type": "public"
} | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
}
] | closed | false | null | [] | null | [
"@hassiahk is working on it #2810 ",
"WikiMedia is now hosting the pixel values directly which should make it a lot easier!\r\nThe files can be found here:\r\nhttps://techblog.wikimedia.org/2021/09/09/the-wikipedia-image-caption-matching-challenge-and-a-huge-release-of-image-data-for-research/\r\nhttps://analyti... | 2021-09-13T19:38:49Z | 2024-10-02T15:37:48Z | 2022-06-01T17:28:40Z | CONTRIBUTOR | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ## Adding a Dataset
- **Name:** *WIT*
- **Description:** *Wikipedia-based Image Text Dataset*
- **Paper:** *[WIT: Wikipedia-based Image Text Dataset for Multimodal Multilingual Machine Learning
](https://arxiv.org/abs/2103.01913)*
- **Data:** *https://github.com/google-research-datasets/wit*
- **Motivation:** (excerpt from their Github README.md)
> - The largest multimodal dataset (publicly available at the time of this writing) by the number of image-text examples.
> - A massively multilingual dataset (first of its kind) with coverage for over 100+ languages.
> - A collection of diverse set of concepts and real world entities.
> - Brings forth challenging real-world test sets.
Instructions to add a new dataset can be found [here](https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md).
| {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2902/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2902/timeline | null | completed | null | null | 6,261.830833 | 4,678 |
https://api.github.com/repos/huggingface/datasets/issues/2901 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2901/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2901/comments | https://api.github.com/repos/huggingface/datasets/issues/2901/events | https://github.com/huggingface/datasets/issues/2901 | 995,232,844 | MDU6SXNzdWU5OTUyMzI4NDQ= | 2,901 | Incompatibility with pytest | {
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://api.github.com/users/severo/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/severo",
"id": 1676121,
"login": "severo",
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"organizations_url": "https://api.github.com/users/severo/orgs",
"received_events_url": "https://api.github.com/users/severo/received_events",
"repos_url": "https://api.github.com/users/severo/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/severo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/severo/subscriptions",
"type": "User",
"url": "https://api.github.com/users/severo",
"user_view_type": "public"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [
"Sorry, my bad... When implementing `xpathopen`, I just considered the use case in the COUNTER dataset... I'm fixing it!"
] | 2021-09-13T19:12:17Z | 2021-09-14T08:40:47Z | 2021-09-14T08:40:47Z | COLLABORATOR | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ## Describe the bug
pytest complains about xpathopen / path.open("w")
## Steps to reproduce the bug
Create a test file, `test.py`:
```python
import datasets as ds
def load_dataset():
ds.load_dataset("counter", split="train", streaming=True)
```
And launch it with pytest:
```bash
python -m pytest test.py
```
## Expected results
It should give something like:
```
collected 1 item
test.py . [100%]
======= 1 passed in 3.15s =======
```
## Actual results
```
============================================================================================================================= test session starts ==============================================================================================================================
platform linux -- Python 3.8.11, pytest-6.2.5, py-1.10.0, pluggy-1.0.0
rootdir: /home/slesage/hf/datasets-preview-backend, configfile: pyproject.toml
plugins: anyio-3.3.1
collected 1 item
tests/queries/test_rows.py . [100%]Traceback (most recent call last):
File "/home/slesage/.pyenv/versions/3.8.11/lib/python3.8/runpy.py", line 194, in _run_module_as_main
return _run_code(code, main_globals, None,
File "/home/slesage/.pyenv/versions/3.8.11/lib/python3.8/runpy.py", line 87, in _run_code
exec(code, run_globals)
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.8/site-packages/pytest/__main__.py", line 5, in <module>
raise SystemExit(pytest.console_main())
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.8/site-packages/_pytest/config/__init__.py", line 185, in console_main
code = main()
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.8/site-packages/_pytest/config/__init__.py", line 162, in main
ret: Union[ExitCode, int] = config.hook.pytest_cmdline_main(
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.8/site-packages/pluggy/_hooks.py", line 265, in __call__
return self._hookexec(self.name, self.get_hookimpls(), kwargs, firstresult)
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.8/site-packages/pluggy/_manager.py", line 80, in _hookexec
return self._inner_hookexec(hook_name, methods, kwargs, firstresult)
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.8/site-packages/pluggy/_callers.py", line 60, in _multicall
return outcome.get_result()
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.8/site-packages/pluggy/_result.py", line 60, in get_result
raise ex[1].with_traceback(ex[2])
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.8/site-packages/pluggy/_callers.py", line 39, in _multicall
res = hook_impl.function(*args)
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.8/site-packages/_pytest/main.py", line 316, in pytest_cmdline_main
return wrap_session(config, _main)
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.8/site-packages/_pytest/main.py", line 304, in wrap_session
config.hook.pytest_sessionfinish(
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.8/site-packages/pluggy/_hooks.py", line 265, in __call__
return self._hookexec(self.name, self.get_hookimpls(), kwargs, firstresult)
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.8/site-packages/pluggy/_manager.py", line 80, in _hookexec
return self._inner_hookexec(hook_name, methods, kwargs, firstresult)
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.8/site-packages/pluggy/_callers.py", line 55, in _multicall
gen.send(outcome)
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.8/site-packages/_pytest/terminal.py", line 803, in pytest_sessionfinish
outcome.get_result()
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.8/site-packages/pluggy/_result.py", line 60, in get_result
raise ex[1].with_traceback(ex[2])
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.8/site-packages/pluggy/_callers.py", line 39, in _multicall
res = hook_impl.function(*args)
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.8/site-packages/_pytest/cacheprovider.py", line 428, in pytest_sessionfinish
config.cache.set("cache/nodeids", sorted(self.cached_nodeids))
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.8/site-packages/_pytest/cacheprovider.py", line 188, in set
f = path.open("w")
TypeError: xpathopen() takes 1 positional argument but 2 were given
```
## Environment info
- `datasets` version: 1.12.0
- Platform: Linux-5.11.0-1017-aws-x86_64-with-glibc2.29
- Python version: 3.8.11
- PyArrow version: 4.0.1
| {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2901/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2901/timeline | null | completed | null | null | 13.475 | 4,679 |
https://api.github.com/repos/huggingface/datasets/issues/2899 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2899/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2899/comments | https://api.github.com/repos/huggingface/datasets/issues/2899/events | https://github.com/huggingface/datasets/issues/2899 | 994,082,432 | MDU6SXNzdWU5OTQwODI0MzI= | 2,899 | Dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/90449239?v=4",
"events_url": "https://api.github.com/users/rcacho172/events{/privacy}",
"followers_url": "https://api.github.com/users/rcacho172/followers",
"following_url": "https://api.github.com/users/rcacho172/following{/other_user}",
"gists_url": "https://api.github.com/users/rcacho172/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/rcacho172",
"id": 90449239,
"login": "rcacho172",
"node_id": "MDQ6VXNlcjkwNDQ5MjM5",
"organizations_url": "https://api.github.com/users/rcacho172/orgs",
"received_events_url": "https://api.github.com/users/rcacho172/received_events",
"repos_url": "https://api.github.com/users/rcacho172/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/rcacho172/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/rcacho172/subscriptions",
"type": "User",
"url": "https://api.github.com/users/rcacho172",
"user_view_type": "public"
} | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
}
] | closed | false | null | [] | null | [] | 2021-09-12T07:38:53Z | 2021-09-12T16:12:15Z | 2021-09-12T16:12:15Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ## Adding a Dataset
- **Name:** *name of the dataset*
- **Description:** *short description of the dataset (or link to social media or blog post)*
- **Paper:** *link to the dataset paper if available*
- **Data:** *link to the Github repository or current dataset location*
- **Motivation:** *what are some good reasons to have this dataset*
Instructions to add a new dataset can be found [here](https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md). | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2899/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2899/timeline | null | completed | null | null | 8.556111 | 4,681 |
https://api.github.com/repos/huggingface/datasets/issues/2898 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2898/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2898/comments | https://api.github.com/repos/huggingface/datasets/issues/2898/events | https://github.com/huggingface/datasets/issues/2898 | 994,032,814 | MDU6SXNzdWU5OTQwMzI4MTQ= | 2,898 | Hug emoji | {
"avatar_url": "https://avatars.githubusercontent.com/u/90539794?v=4",
"events_url": "https://api.github.com/users/Jackg-08/events{/privacy}",
"followers_url": "https://api.github.com/users/Jackg-08/followers",
"following_url": "https://api.github.com/users/Jackg-08/following{/other_user}",
"gists_url": "https://api.github.com/users/Jackg-08/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Jackg-08",
"id": 90539794,
"login": "Jackg-08",
"node_id": "MDQ6VXNlcjkwNTM5Nzk0",
"organizations_url": "https://api.github.com/users/Jackg-08/orgs",
"received_events_url": "https://api.github.com/users/Jackg-08/received_events",
"repos_url": "https://api.github.com/users/Jackg-08/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Jackg-08/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Jackg-08/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Jackg-08",
"user_view_type": "public"
} | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
}
] | closed | false | null | [] | null | [] | 2021-09-12T03:27:51Z | 2021-09-12T16:13:13Z | 2021-09-12T16:13:13Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ## Adding a Dataset
- **Name:** *name of the dataset*
- **Description:** *short description of the dataset (or link to social media or blog post)*
- **Paper:** *link to the dataset paper if available*
- **Data:** *link to the Github repository or current dataset location*
- **Motivation:** *what are some good reasons to have this dataset*
Instructions to add a new dataset can be found [here](https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md). | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2898/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2898/timeline | null | completed | null | null | 12.756111 | 4,682 |
https://api.github.com/repos/huggingface/datasets/issues/2892 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2892/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2892/comments | https://api.github.com/repos/huggingface/datasets/issues/2892/events | https://github.com/huggingface/datasets/issues/2892 | 993,274,572 | MDU6SXNzdWU5OTMyNzQ1NzI= | 2,892 | Error when encoding a dataset with None objects with a Sequence feature | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"This has been fixed by https://github.com/huggingface/datasets/pull/2900\r\nWe're doing a new release 1.12 today to make the fix available :)"
] | 2021-09-10T14:11:43Z | 2021-09-13T14:18:13Z | 2021-09-13T14:17:42Z | MEMBER | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | There is an error when encoding a dataset with None objects with a Sequence feature
To reproduce:
```python
from datasets import Dataset, Features, Value, Sequence
data = {"a": [[0], None]}
features = Features({"a": Sequence(Value("int32"))})
dataset = Dataset.from_dict(data, features=features)
```
raises
```python
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-24-40add67f8751> in <module>
2 data = {"a": [[0], None]}
3 features = Features({"a": Sequence(Value("int32"))})
----> 4 dataset = Dataset.from_dict(data, features=features)
[...]
~/datasets/features.py in encode_nested_example(schema, obj)
888 if isinstance(obj, str): # don't interpret a string as a list
889 raise ValueError("Got a string but expected a list instead: '{}'".format(obj))
--> 890 return [encode_nested_example(schema.feature, o) for o in obj]
891 # Object with special encoding:
892 # ClassLabel will convert from string to int, TranslationVariableLanguages does some checks
TypeError: 'NoneType' object is not iterable
```
Instead, if should run without error, as if the `features` were not passed | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2892/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2892/timeline | null | completed | null | null | 72.099722 | 4,688 |
https://api.github.com/repos/huggingface/datasets/issues/2890 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2890/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2890/comments | https://api.github.com/repos/huggingface/datasets/issues/2890/events | https://github.com/huggingface/datasets/issues/2890 | 993,074,102 | MDU6SXNzdWU5OTMwNzQxMDI= | 2,890 | 0x290B112ED1280537B24Ee6C268a004994a16e6CE | {
"avatar_url": "https://avatars.githubusercontent.com/u/90449239?v=4",
"events_url": "https://api.github.com/users/rcacho172/events{/privacy}",
"followers_url": "https://api.github.com/users/rcacho172/followers",
"following_url": "https://api.github.com/users/rcacho172/following{/other_user}",
"gists_url": "https://api.github.com/users/rcacho172/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/rcacho172",
"id": 90449239,
"login": "rcacho172",
"node_id": "MDQ6VXNlcjkwNDQ5MjM5",
"organizations_url": "https://api.github.com/users/rcacho172/orgs",
"received_events_url": "https://api.github.com/users/rcacho172/received_events",
"repos_url": "https://api.github.com/users/rcacho172/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/rcacho172/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/rcacho172/subscriptions",
"type": "User",
"url": "https://api.github.com/users/rcacho172",
"user_view_type": "public"
} | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
}
] | closed | false | null | [] | null | [] | 2021-09-10T09:51:17Z | 2021-09-10T11:45:29Z | 2021-09-10T11:45:29Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ## Adding a Dataset
- **Name:** *name of the dataset*
- **Description:** *short description of the dataset (or link to social media or blog post)*
- **Paper:** *link to the dataset paper if available*
- **Data:** *link to the Github repository or current dataset location*
- **Motivation:** *what are some good reasons to have this dataset*
Instructions to add a new dataset can be found [here](https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md). | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2890/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2890/timeline | null | completed | null | null | 1.903333 | 4,690 |
https://api.github.com/repos/huggingface/datasets/issues/2889 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2889/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2889/comments | https://api.github.com/repos/huggingface/datasets/issues/2889/events | https://github.com/huggingface/datasets/issues/2889 | 992,968,382 | MDU6SXNzdWU5OTI5NjgzODI= | 2,889 | Coc | {
"avatar_url": "https://avatars.githubusercontent.com/u/90444264?v=4",
"events_url": "https://api.github.com/users/Bwiggity/events{/privacy}",
"followers_url": "https://api.github.com/users/Bwiggity/followers",
"following_url": "https://api.github.com/users/Bwiggity/following{/other_user}",
"gists_url": "https://api.github.com/users/Bwiggity/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Bwiggity",
"id": 90444264,
"login": "Bwiggity",
"node_id": "MDQ6VXNlcjkwNDQ0MjY0",
"organizations_url": "https://api.github.com/users/Bwiggity/orgs",
"received_events_url": "https://api.github.com/users/Bwiggity/received_events",
"repos_url": "https://api.github.com/users/Bwiggity/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Bwiggity/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Bwiggity/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Bwiggity",
"user_view_type": "public"
} | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
}
] | closed | false | null | [] | null | [] | 2021-09-10T07:32:07Z | 2021-09-10T11:45:54Z | 2021-09-10T11:45:54Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ## Adding a Dataset
- **Name:** *name of the dataset*
- **Description:** *short description of the dataset (or link to social media or blog post)*
- **Paper:** *link to the dataset paper if available*
- **Data:** *link to the Github repository or current dataset location*
- **Motivation:** *what are some good reasons to have this dataset*
Instructions to add a new dataset can be found [here](https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md). | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2889/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2889/timeline | null | completed | null | null | 4.229722 | 4,691 |
https://api.github.com/repos/huggingface/datasets/issues/2888 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2888/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2888/comments | https://api.github.com/repos/huggingface/datasets/issues/2888/events | https://github.com/huggingface/datasets/issues/2888 | 992,676,535 | MDU6SXNzdWU5OTI2NzY1MzU= | 2,888 | v1.11.1 release date | {
"avatar_url": "https://avatars.githubusercontent.com/u/34196005?v=4",
"events_url": "https://api.github.com/users/fcakyon/events{/privacy}",
"followers_url": "https://api.github.com/users/fcakyon/followers",
"following_url": "https://api.github.com/users/fcakyon/following{/other_user}",
"gists_url": "https://api.github.com/users/fcakyon/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/fcakyon",
"id": 34196005,
"login": "fcakyon",
"node_id": "MDQ6VXNlcjM0MTk2MDA1",
"organizations_url": "https://api.github.com/users/fcakyon/orgs",
"received_events_url": "https://api.github.com/users/fcakyon/received_events",
"repos_url": "https://api.github.com/users/fcakyon/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/fcakyon/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/fcakyon/subscriptions",
"type": "User",
"url": "https://api.github.com/users/fcakyon",
"user_view_type": "public"
} | [
{
"color": "d876e3",
"default": true,
"description": "Further information is requested",
"id": 1935892912,
"name": "question",
"node_id": "MDU6TGFiZWwxOTM1ODkyOTEy",
"url": "https://api.github.com/repos/huggingface/datasets/labels/question"
}
] | closed | false | null | [] | null | [
"Hi ! Probably 1.12 on monday :)\r\n",
"@albertvillanova i think this issue is still valid and should not be closed till `>1.11.0` is published :)"
] | 2021-09-09T21:53:15Z | 2021-09-12T20:18:35Z | 2021-09-12T16:15:39Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | Hello, i need to use latest features in one of my packages but there have been no new datasets release since 2 months ago.
When do you plan to publush v1.11.1 release? | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 1,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2888/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2888/timeline | null | completed | null | null | 66.373333 | 4,692 |
https://api.github.com/repos/huggingface/datasets/issues/2886 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2886/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2886/comments | https://api.github.com/repos/huggingface/datasets/issues/2886/events | https://github.com/huggingface/datasets/issues/2886 | 992,534,632 | MDU6SXNzdWU5OTI1MzQ2MzI= | 2,886 | Hj | {
"avatar_url": "https://avatars.githubusercontent.com/u/90416328?v=4",
"events_url": "https://api.github.com/users/Noorasri/events{/privacy}",
"followers_url": "https://api.github.com/users/Noorasri/followers",
"following_url": "https://api.github.com/users/Noorasri/following{/other_user}",
"gists_url": "https://api.github.com/users/Noorasri/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Noorasri",
"id": 90416328,
"login": "Noorasri",
"node_id": "MDQ6VXNlcjkwNDE2MzI4",
"organizations_url": "https://api.github.com/users/Noorasri/orgs",
"received_events_url": "https://api.github.com/users/Noorasri/received_events",
"repos_url": "https://api.github.com/users/Noorasri/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Noorasri/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Noorasri/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Noorasri",
"user_view_type": "public"
} | [] | closed | false | null | [] | null | [] | 2021-09-09T18:58:52Z | 2021-09-10T11:46:29Z | 2021-09-10T11:46:29Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | null | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2886/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2886/timeline | null | completed | null | null | 16.793611 | 4,694 |
https://api.github.com/repos/huggingface/datasets/issues/2882 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2882/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2882/comments | https://api.github.com/repos/huggingface/datasets/issues/2882/events | https://github.com/huggingface/datasets/issues/2882 | 991,800,141 | MDU6SXNzdWU5OTE4MDAxNDE= | 2,882 | `load_dataset('docred')` results in a `NonMatchingChecksumError` | {
"avatar_url": "https://avatars.githubusercontent.com/u/51313597?v=4",
"events_url": "https://api.github.com/users/tmpr/events{/privacy}",
"followers_url": "https://api.github.com/users/tmpr/followers",
"following_url": "https://api.github.com/users/tmpr/following{/other_user}",
"gists_url": "https://api.github.com/users/tmpr/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/tmpr",
"id": 51313597,
"login": "tmpr",
"node_id": "MDQ6VXNlcjUxMzEzNTk3",
"organizations_url": "https://api.github.com/users/tmpr/orgs",
"received_events_url": "https://api.github.com/users/tmpr/received_events",
"repos_url": "https://api.github.com/users/tmpr/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/tmpr/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/tmpr/subscriptions",
"type": "User",
"url": "https://api.github.com/users/tmpr",
"user_view_type": "public"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [
"Hi @tmpr, thanks for reporting.\r\n\r\nTwo weeks ago (23th Aug), the host of the source `docred` dataset updated one of the files (`dev.json`): you can see it [here](https://drive.google.com/drive/folders/1c5-0YwnoJx8NS6CV2f-NoTHR__BdkNqw).\r\n\r\nTherefore, the checksum needs to be updated.\r\n\r\nNormally, in th... | 2021-09-09T05:55:02Z | 2021-09-13T11:24:30Z | 2021-09-13T11:24:30Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ## Describe the bug
I get consistent `NonMatchingChecksumError: Checksums didn't match for dataset source files` errors when trying to execute `datasets.load_dataset('docred')`.
## Steps to reproduce the bug
It is quasi only this code:
```python
import datasets
data = datasets.load_dataset('docred')
```
## Expected results
The DocRED dataset should be loaded without any problems.
## Actual results
```
NonMatchingChecksumError Traceback (most recent call last)
<ipython-input-4-b1b83f25a16c> in <module>
----> 1 d = datasets.load_dataset('docred')
~/anaconda3/lib/python3.8/site-packages/datasets/load.py in load_dataset(path, name, data_dir, data_files, split, cache_dir, features, download_config, download_mode, ignore_verifications, keep_in_memory, save_infos, script_version, use_auth_token, task, streaming, **config_kwargs)
845
846 # Download and prepare data
--> 847 builder_instance.download_and_prepare(
848 download_config=download_config,
849 download_mode=download_mode,
~/anaconda3/lib/python3.8/site-packages/datasets/builder.py in download_and_prepare(self, download_config, download_mode, ignore_verifications, try_from_hf_gcs, dl_manager, base_path, use_auth_token, **download_and_prepare_kwargs)
613 logger.warning("HF google storage unreachable. Downloading and preparing it from source")
614 if not downloaded_from_gcs:
--> 615 self._download_and_prepare(
616 dl_manager=dl_manager, verify_infos=verify_infos, **download_and_prepare_kwargs
617 )
~/anaconda3/lib/python3.8/site-packages/datasets/builder.py in _download_and_prepare(self, dl_manager, verify_infos, **prepare_split_kwargs)
673 # Checksums verification
674 if verify_infos:
--> 675 verify_checksums(
676 self.info.download_checksums, dl_manager.get_recorded_sizes_checksums(), "dataset source files"
677 )
~/anaconda3/lib/python3.8/site-packages/datasets/utils/info_utils.py in verify_checksums(expected_checksums, recorded_checksums, verification_name)
38 if len(bad_urls) > 0:
39 error_msg = "Checksums didn't match" + for_verification_name + ":\n"
---> 40 raise NonMatchingChecksumError(error_msg + str(bad_urls))
41 logger.info("All the checksums matched successfully" + for_verification_name)
42
NonMatchingChecksumError: Checksums didn't match for dataset source files:
['https://drive.google.com/uc?export=download&id=1fDmfUUo5G7gfaoqWWvK81u08m71TK2g7']
```
## Environment info
- `datasets` version: 1.11.0
- Platform: Linux-5.11.0-7633-generic-x86_64-with-glibc2.10
- Python version: 3.8.5
- PyArrow version: 5.0.0
This error also happened on my Windows-partition, after freshly installing python 3.9 and `datasets`.
## Remarks
- I have already called `rm -rf /home/<user>/.cache/huggingface`, i.e., I have tried clearing the cache.
- The problem does not exist for other datasets, i.e., it seems to be DocRED-specific. | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2882/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2882/timeline | null | completed | null | null | 101.491111 | 4,698 |
https://api.github.com/repos/huggingface/datasets/issues/2879 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2879/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2879/comments | https://api.github.com/repos/huggingface/datasets/issues/2879/events | https://github.com/huggingface/datasets/issues/2879 | 990,257,404 | MDU6SXNzdWU5OTAyNTc0MDQ= | 2,879 | In v1.4.1, all TIMIT train transcripts are "Would such an act of refusal be useful?" | {
"avatar_url": "https://avatars.githubusercontent.com/u/2279700?v=4",
"events_url": "https://api.github.com/users/rcgale/events{/privacy}",
"followers_url": "https://api.github.com/users/rcgale/followers",
"following_url": "https://api.github.com/users/rcgale/following{/other_user}",
"gists_url": "https://api.github.com/users/rcgale/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/rcgale",
"id": 2279700,
"login": "rcgale",
"node_id": "MDQ6VXNlcjIyNzk3MDA=",
"organizations_url": "https://api.github.com/users/rcgale/orgs",
"received_events_url": "https://api.github.com/users/rcgale/received_events",
"repos_url": "https://api.github.com/users/rcgale/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/rcgale/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/rcgale/subscriptions",
"type": "User",
"url": "https://api.github.com/users/rcgale",
"user_view_type": "public"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"Hi @rcgale, thanks for reporting.\r\n\r\nPlease note that this bug was fixed on `datasets` version 1.5.0: https://github.com/huggingface/datasets/commit/a23c73e526e1c30263834164f16f1fdf76722c8c#diff-f12a7a42d4673bb6c2ca5a40c92c29eb4fe3475908c84fd4ce4fad5dc2514878\r\n\r\nIf you update `datasets` version, that shoul... | 2021-09-07T18:53:45Z | 2021-09-08T16:55:19Z | 2021-09-08T09:12:28Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ## Describe the bug
Using version 1.4.1 of `datasets`, TIMIT transcripts are all the same.
## Steps to reproduce the bug
I was following this tutorial
- https://huggingface.co/blog/fine-tune-wav2vec2-english
But here's a distilled repro:
```python
!pip install datasets==1.4.1
from datasets import load_dataset
timit = load_dataset("timit_asr", cache_dir="./temp")
unique_transcripts = set(timit["train"]["text"])
print(unique_transcripts)
assert len(unique_transcripts) > 1
```
## Expected results
Expected the correct TIMIT data. Or an error saying that this version of `datasets` can't produce it.
## Actual results
Every train transcript was "Would such an act of refusal be useful?" Every test transcript was "The bungalow was pleasantly situated near the shore."
## Environment info
- `datasets` version: 1.4.1
- Platform: Darwin-18.7.0-x86_64-i386-64bit
- Python version: 3.7.9
- PyTorch version (GPU?): 1.9.0 (False)
- Tensorflow version (GPU?): not installed (NA)
- Using GPU in script?: tried both
- Using distributed or parallel set-up in script?: no
-
| {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2879/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2879/timeline | null | completed | null | null | 14.311944 | 4,701 |
https://api.github.com/repos/huggingface/datasets/issues/2877 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2877/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2877/comments | https://api.github.com/repos/huggingface/datasets/issues/2877/events | https://github.com/huggingface/datasets/issues/2877 | 990,027,249 | MDU6SXNzdWU5OTAwMjcyNDk= | 2,877 | Don't keep the dummy data folder or dataset_infos.json when resolving data files | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
} | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | null | [] | null | [
"Hi @lhoestq I am new to huggingface datasets, I would like to work on this issue!\r\n",
"Thanks for the help :) \r\n\r\nAs mentioned in the PR, excluding files named \"dummy_data.zip\" is actually more general than excluding the files inside a \"dummy\" folder. I just did the change in the PR, I think we can mer... | 2021-09-07T14:09:04Z | 2021-09-29T09:05:38Z | 2021-09-29T09:05:38Z | MEMBER | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | When there's no dataset script, all the data files of a folder or a repository on the Hub are loaded as data files.
There are already a few exceptions:
- files starting with "." are ignored
- the dataset card "README.md" is ignored
- any file named "config.json" is ignored (currently it isn't used anywhere, but it could be used in the future to define splits or configs for example, but not 100% sure)
However any data files in a folder named "dummy" should be ignored as well as they should only be used to test the dataset.
Same for "dataset_infos.json" which should only be used to get the `dataset.info` | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2877/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2877/timeline | null | completed | null | null | 522.942778 | 4,703 |
https://api.github.com/repos/huggingface/datasets/issues/2871 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2871/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2871/comments | https://api.github.com/repos/huggingface/datasets/issues/2871/events | https://github.com/huggingface/datasets/issues/2871 | 989,436,088 | MDU6SXNzdWU5ODk0MzYwODg= | 2,871 | datasets.config.PYARROW_VERSION has no attribute 'major' | {
"avatar_url": "https://avatars.githubusercontent.com/u/6764450?v=4",
"events_url": "https://api.github.com/users/bwang482/events{/privacy}",
"followers_url": "https://api.github.com/users/bwang482/followers",
"following_url": "https://api.github.com/users/bwang482/following{/other_user}",
"gists_url": "https://api.github.com/users/bwang482/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/bwang482",
"id": 6764450,
"login": "bwang482",
"node_id": "MDQ6VXNlcjY3NjQ0NTA=",
"organizations_url": "https://api.github.com/users/bwang482/orgs",
"received_events_url": "https://api.github.com/users/bwang482/received_events",
"repos_url": "https://api.github.com/users/bwang482/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/bwang482/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/bwang482/subscriptions",
"type": "User",
"url": "https://api.github.com/users/bwang482",
"user_view_type": "public"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"I have changed line 288 to `if int(datasets.config.PYARROW_VERSION.split(\".\")[0]) < 3:` just to get around it.",
"Hi @bwang482,\r\n\r\nI'm sorry but I'm not able to reproduce your bug.\r\n\r\nPlease note that in our current master branch, we made a commit (d03223d4d64b89e76b48b00602aba5aa2f817f1e) that simulta... | 2021-09-06T21:06:57Z | 2021-09-08T08:51:52Z | 2021-09-08T08:51:52Z | CONTRIBUTOR | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | In the test_dataset_common.py script, line 288-289
```
if datasets.config.PYARROW_VERSION.major < 3:
packaged_datasets = [pd for pd in packaged_datasets if pd["dataset_name"] != "parquet"]
```
which throws the error below. `datasets.config.PYARROW_VERSION` itself return the string '4.0.1'. I have tested this on both datasets.__version_=='1.11.0' and '1.9.0'. I am using Mac OS.
```
import datasets
datasets.config.PYARROW_VERSION.major
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
/var/folders/1f/0wqmlgp90qjd5mpj53fnjq440000gn/T/ipykernel_73361/2547517336.py in <module>
1 import datasets
----> 2 datasets.config.PYARROW_VERSION.major
AttributeError: 'str' object has no attribute 'major'
```
## Environment info
- `datasets` version: 1.11.0
- Platform: Darwin-20.6.0-x86_64-i386-64bit
- Python version: 3.7.11
- PyArrow version: 4.0.1
| {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2871/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2871/timeline | null | completed | null | null | 35.748611 | 4,709 |
https://api.github.com/repos/huggingface/datasets/issues/2869 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2869/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2869/comments | https://api.github.com/repos/huggingface/datasets/issues/2869/events | https://github.com/huggingface/datasets/issues/2869 | 987,676,420 | MDU6SXNzdWU5ODc2NzY0MjA= | 2,869 | TypeError: 'NoneType' object is not callable | {
"avatar_url": "https://avatars.githubusercontent.com/u/40911446?v=4",
"events_url": "https://api.github.com/users/Chenfei-Kang/events{/privacy}",
"followers_url": "https://api.github.com/users/Chenfei-Kang/followers",
"following_url": "https://api.github.com/users/Chenfei-Kang/following{/other_user}",
"gists_url": "https://api.github.com/users/Chenfei-Kang/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Chenfei-Kang",
"id": 40911446,
"login": "Chenfei-Kang",
"node_id": "MDQ6VXNlcjQwOTExNDQ2",
"organizations_url": "https://api.github.com/users/Chenfei-Kang/orgs",
"received_events_url": "https://api.github.com/users/Chenfei-Kang/received_events",
"repos_url": "https://api.github.com/users/Chenfei-Kang/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Chenfei-Kang/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Chenfei-Kang/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Chenfei-Kang",
"user_view_type": "public"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"Hi, @Chenfei-Kang.\r\n\r\nI'm sorry, but I'm not able to reproduce your bug:\r\n```python\r\nfrom datasets import load_dataset\r\n\r\nds = load_dataset(\"glue\", 'cola')\r\nds\r\n```\r\n```\r\nDatasetDict({\r\n train: Dataset({\r\n features: ['sentence', 'label', 'idx'],\r\n num_rows: 8551\r\n ... | 2021-09-03T11:27:39Z | 2025-02-19T09:57:34Z | 2021-09-08T09:24:55Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ## Describe the bug
TypeError: 'NoneType' object is not callable
## Steps to reproduce the bug
```python
from datasets import load_dataset, load_metric
dataset = datasets.load_dataset("glue", 'cola')
```
## Expected results
A clear and concise description of the expected results.
## Actual results
Specify the actual results or traceback.
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.11.0
- Platform:
- Python version: 3.7
- PyArrow version:
| {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2869/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2869/timeline | null | completed | null | null | 117.954444 | 4,711 |
https://api.github.com/repos/huggingface/datasets/issues/2866 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2866/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2866/comments | https://api.github.com/repos/huggingface/datasets/issues/2866/events | https://github.com/huggingface/datasets/issues/2866 | 986,706,676 | MDU6SXNzdWU5ODY3MDY2NzY= | 2,866 | "counter" dataset raises an error in normal mode, but not in streaming mode | {
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://api.github.com/users/severo/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/severo",
"id": 1676121,
"login": "severo",
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"organizations_url": "https://api.github.com/users/severo/orgs",
"received_events_url": "https://api.github.com/users/severo/received_events",
"repos_url": "https://api.github.com/users/severo/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/severo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/severo/subscriptions",
"type": "User",
"url": "https://api.github.com/users/severo",
"user_view_type": "public"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists... | null | [
"Hi @severo, thanks for reporting.\r\n\r\nJust note that currently not all canonical datasets support streaming mode: this is one case!\r\n\r\nAll datasets that use `pathlib` joins (using `/`) instead of `os.path.join` (as in this dataset) do not support streaming mode yet.",
"OK. Do you think it's possible to de... | 2021-09-02T13:10:53Z | 2021-10-14T09:24:09Z | 2021-10-14T09:24:09Z | COLLABORATOR | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ## Describe the bug
`counter` dataset raises an error on `load_dataset()`, but simply returns an empty iterator in streaming mode.
## Steps to reproduce the bug
```python
>>> import datasets as ds
>>> a = ds.load_dataset('counter', split="train", streaming=False)
Using custom data configuration default
Downloading and preparing dataset counter/default (download: 1.29 MiB, generated: 2.48 MiB, post-processed: Unknown size, total: 3.77 MiB) to /home/slesage/.cache/huggingface/datasets/counter/default/1.0.0/9f84962fa0f35bec5a34fe0bdff8681838d497008c457f7856c48654476ec0e9...
Traceback (most recent call last):
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.8/site-packages/datasets/builder.py", line 726, in _download_and_prepare
self._prepare_split(split_generator, **prepare_split_kwargs)
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.8/site-packages/datasets/builder.py", line 1124, in _prepare_split
for key, record in utils.tqdm(
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.8/site-packages/tqdm/std.py", line 1185, in __iter__
for obj in iterable:
File "/home/slesage/.cache/huggingface/modules/datasets_modules/datasets/counter/9f84962fa0f35bec5a34fe0bdff8681838d497008c457f7856c48654476ec0e9/counter.py", line 161, in _generate_examples
with derived_file.open(encoding="utf-8") as f:
File "/home/slesage/.pyenv/versions/3.8.11/lib/python3.8/pathlib.py", line 1222, in open
return io.open(self, mode, buffering, encoding, errors, newline,
File "/home/slesage/.pyenv/versions/3.8.11/lib/python3.8/pathlib.py", line 1078, in _opener
return self._accessor.open(self, flags, mode)
FileNotFoundError: [Errno 2] No such file or directory: '/home/slesage/.cache/huggingface/datasets/downloads/extracted/b57aa6db5601a738e57b95c1fd8cced54ff28fc540efcdaf0f6c4f1bb5dfe211/COUNTER/0032p.xml'
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.8/site-packages/datasets/load.py", line 1112, in load_dataset
builder_instance.download_and_prepare(
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.8/site-packages/datasets/builder.py", line 636, in download_and_prepare
self._download_and_prepare(
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.8/site-packages/datasets/builder.py", line 728, in _download_and_prepare
raise OSError(
OSError: Cannot find data file.
Original error:
[Errno 2] No such file or directory: '/home/slesage/.cache/huggingface/datasets/downloads/extracted/b57aa6db5601a738e57b95c1fd8cced54ff28fc540efcdaf0f6c4f1bb5dfe211/COUNTER/0032p.xml'
```
```python
>>> import datasets as ds
>>> b = ds.load_dataset('counter', split="train", streaming=True)
Using custom data configuration default
>>> list(b)
[]
```
## Expected results
An exception should be raised in streaming mode
## Actual results
No exception is raised in streaming mode: there is no way to tell if something has broken or if the dataset is simply empty.
## Environment info
- `datasets` version: 1.11.1.dev0
- Platform: Linux-5.11.0-1016-aws-x86_64-with-glibc2.29
- Python version: 3.8.11
- PyArrow version: 4.0.1
| {
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://api.github.com/users/severo/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/severo",
"id": 1676121,
"login": "severo",
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"organizations_url": "https://api.github.com/users/severo/orgs",
"received_events_url": "https://api.github.com/users/severo/received_events",
"repos_url": "https://api.github.com/users/severo/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/severo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/severo/subscriptions",
"type": "User",
"url": "https://api.github.com/users/severo",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2866/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2866/timeline | null | completed | null | null | 1,004.221111 | 4,714 |
https://api.github.com/repos/huggingface/datasets/issues/2860 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2860/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2860/comments | https://api.github.com/repos/huggingface/datasets/issues/2860/events | https://github.com/huggingface/datasets/issues/2860 | 985,013,339 | MDU6SXNzdWU5ODUwMTMzMzk= | 2,860 | Cannot download TOTTO dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/3653789?v=4",
"events_url": "https://api.github.com/users/mrm8488/events{/privacy}",
"followers_url": "https://api.github.com/users/mrm8488/followers",
"following_url": "https://api.github.com/users/mrm8488/following{/other_user}",
"gists_url": "https://api.github.com/users/mrm8488/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mrm8488",
"id": 3653789,
"login": "mrm8488",
"node_id": "MDQ6VXNlcjM2NTM3ODk=",
"organizations_url": "https://api.github.com/users/mrm8488/orgs",
"received_events_url": "https://api.github.com/users/mrm8488/received_events",
"repos_url": "https://api.github.com/users/mrm8488/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mrm8488/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mrm8488/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mrm8488",
"user_view_type": "public"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [
"Hola @mrm8488, thanks for reporting.\r\n\r\nApparently, the data source host changed their URL one week ago: https://github.com/google-research-datasets/ToTTo/commit/cebeb430ec2a97747e704d16a9354f7d9073ff8f\r\n\r\nI'm fixing it."
] | 2021-09-01T11:04:10Z | 2021-09-02T06:47:40Z | 2021-09-02T06:47:40Z | CONTRIBUTOR | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | Error: Couldn't find file at https://storage.googleapis.com/totto/totto_data.zip
`datasets version: 1.11.0`
# How to reproduce:
```py
from datasets import load_dataset
dataset = load_dataset('totto')
```
| {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2860/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2860/timeline | null | completed | null | null | 19.725 | 4,719 |
https://api.github.com/repos/huggingface/datasets/issues/2859 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2859/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2859/comments | https://api.github.com/repos/huggingface/datasets/issues/2859/events | https://github.com/huggingface/datasets/issues/2859 | 984,324,500 | MDU6SXNzdWU5ODQzMjQ1MDA= | 2,859 | Loading allenai/c4 in streaming mode does too many HEAD requests | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
} | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
},
{
"color": "fef2c0",
"default": fals... | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists... | null | [
"https://github.com/huggingface/datasets/blob/6c766f9115d686182d76b1b937cb27e099c45d68/src/datasets/builder.py#L179-L186",
"Thanks a lot!!!"
] | 2021-08-31T21:11:04Z | 2021-10-12T07:35:52Z | 2021-10-11T11:05:51Z | MEMBER | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | This does 60,000+ HEAD requests to get all the ETags of all the data files:
```python
from datasets import load_dataset
load_dataset("allenai/c4", streaming=True)
```
It makes loading the dataset completely impractical.
The ETags are used to compute the config id (it must depend on the data files being used).
Instead of using the ETags, we could simply use the commit hash of the dataset repository on the hub, as well and the glob pattern used to resolve the files (here it's `*` by default, to load all the files of the repository) | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
} | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2859/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2859/timeline | null | completed | null | null | 973.913056 | 4,720 |
https://api.github.com/repos/huggingface/datasets/issues/2846 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2846/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2846/comments | https://api.github.com/repos/huggingface/datasets/issues/2846/events | https://github.com/huggingface/datasets/issues/2846 | 981,587,590 | MDU6SXNzdWU5ODE1ODc1OTA= | 2,846 | Negative timezone | {
"avatar_url": "https://avatars.githubusercontent.com/u/7156771?v=4",
"events_url": "https://api.github.com/users/jadermcs/events{/privacy}",
"followers_url": "https://api.github.com/users/jadermcs/followers",
"following_url": "https://api.github.com/users/jadermcs/following{/other_user}",
"gists_url": "https://api.github.com/users/jadermcs/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/jadermcs",
"id": 7156771,
"login": "jadermcs",
"node_id": "MDQ6VXNlcjcxNTY3NzE=",
"organizations_url": "https://api.github.com/users/jadermcs/orgs",
"received_events_url": "https://api.github.com/users/jadermcs/received_events",
"repos_url": "https://api.github.com/users/jadermcs/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/jadermcs/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jadermcs/subscriptions",
"type": "User",
"url": "https://api.github.com/users/jadermcs",
"user_view_type": "public"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"Fixed by #2847."
] | 2021-08-27T20:50:33Z | 2021-09-10T11:51:07Z | 2021-09-10T11:51:07Z | CONTRIBUTOR | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ## Describe the bug
The load_dataset method do not accept a parquet file with a negative timezone, as it has the following regex:
```
"^(s|ms|us|ns),\s*tz=([a-zA-Z0-9/_+:]*)$"
```
So a valid timestap ```timestamp[us, tz=-03:00]``` returns an error when loading parquet files.
## Steps to reproduce the bug
```python
# Where the timestamp column has a tz of -03:00
datasets = load_dataset('parquet', data_files={'train': train_files, 'validation': validation_files,
'test': test_files}, cache_dir="./cache_teste/")
```
## Expected results
The -03:00 is a valid tz so the regex should accept this without raising an error.
## Actual results
As this regex disaproves a valid tz it raises the following error:
```python
raise ValueError(
f"{datasets_dtype} is not a validly formatted string representation of a pyarrow timestamp."
f"Examples include timestamp[us] or timestamp[us, tz=America/New_York]"
f"See: https://arrow.apache.org/docs/python/generated/pyarrow.timestamp.html#pyarrow.timestamp"
)
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.11.0
- Platform: Ubuntu 20.04
- Python version: 3.8
- PyArrow version: 5.0.0
| {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2846/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2846/timeline | null | completed | null | null | 327.009444 | 4,733 |
https://api.github.com/repos/huggingface/datasets/issues/2842 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2842/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2842/comments | https://api.github.com/repos/huggingface/datasets/issues/2842/events | https://github.com/huggingface/datasets/issues/2842 | 980,725,899 | MDU6SXNzdWU5ODA3MjU4OTk= | 2,842 | always requiring the username in the dataset name when there is one | {
"avatar_url": "https://avatars.githubusercontent.com/u/10676103?v=4",
"events_url": "https://api.github.com/users/stas00/events{/privacy}",
"followers_url": "https://api.github.com/users/stas00/followers",
"following_url": "https://api.github.com/users/stas00/following{/other_user}",
"gists_url": "https://api.github.com/users/stas00/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/stas00",
"id": 10676103,
"login": "stas00",
"node_id": "MDQ6VXNlcjEwNjc2MTAz",
"organizations_url": "https://api.github.com/users/stas00/orgs",
"received_events_url": "https://api.github.com/users/stas00/received_events",
"repos_url": "https://api.github.com/users/stas00/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/stas00/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stas00/subscriptions",
"type": "User",
"url": "https://api.github.com/users/stas00",
"user_view_type": "public"
} | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists... | null | [
"From what I can understand, you want the saved arrow file directory to have username as well instead of just dataset name if it was downloaded with the user prefix?",
"I don't think the user cares of how this is done, but the 2nd command should fail, IMHO, as its dataset name is invalid:\r\n```\r\n# first run\r\... | 2021-08-26T23:31:53Z | 2021-10-22T09:43:35Z | 2021-10-22T09:43:35Z | CONTRIBUTOR | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | Me and now another person have been bitten by the `datasets`'s non-strictness on requiring a dataset creator's username when it's due.
So both of us started with `stas/openwebtext-10k`, somewhere along the lines lost `stas/` and continued using `openwebtext-10k` and it all was good until we published the software and things broke, since there is no `openwebtext-10k`
So this feature request is asking to tighten the checking and not allow dataset loading if it was downloaded with the user prefix, but then attempted to be used w/o it.
The same in code:
```
# first run
python -c "from datasets import load_dataset; load_dataset('stas/openwebtext-10k')"
# now run immediately
python -c "from datasets import load_dataset; load_dataset('openwebtext-10k')"
# the second command should fail, but it doesn't fail now.
```
Please let me know if I explained myself clearly.
Thank you! | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
} | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2842/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2842/timeline | null | completed | null | null | 1,354.195 | 4,737 |
https://api.github.com/repos/huggingface/datasets/issues/2840 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2840/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2840/comments | https://api.github.com/repos/huggingface/datasets/issues/2840/events | https://github.com/huggingface/datasets/issues/2840 | 980,489,074 | MDU6SXNzdWU5ODA0ODkwNzQ= | 2,840 | How can I compute BLEU-4 score use `load_metric` ? | {
"avatar_url": "https://avatars.githubusercontent.com/u/26213546?v=4",
"events_url": "https://api.github.com/users/Doragd/events{/privacy}",
"followers_url": "https://api.github.com/users/Doragd/followers",
"following_url": "https://api.github.com/users/Doragd/following{/other_user}",
"gists_url": "https://api.github.com/users/Doragd/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Doragd",
"id": 26213546,
"login": "Doragd",
"node_id": "MDQ6VXNlcjI2MjEzNTQ2",
"organizations_url": "https://api.github.com/users/Doragd/orgs",
"received_events_url": "https://api.github.com/users/Doragd/received_events",
"repos_url": "https://api.github.com/users/Doragd/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Doragd/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Doragd/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Doragd",
"user_view_type": "public"
} | [] | closed | false | null | [] | null | [] | 2021-08-26T17:36:37Z | 2021-08-27T08:13:24Z | 2021-08-27T08:13:24Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | I have found the sacrebleu metric. But, I do not know the difference between it and BLEU-4.
If I want to compute BLEU-4 score, what can i do? | {
"avatar_url": "https://avatars.githubusercontent.com/u/26213546?v=4",
"events_url": "https://api.github.com/users/Doragd/events{/privacy}",
"followers_url": "https://api.github.com/users/Doragd/followers",
"following_url": "https://api.github.com/users/Doragd/following{/other_user}",
"gists_url": "https://api.github.com/users/Doragd/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Doragd",
"id": 26213546,
"login": "Doragd",
"node_id": "MDQ6VXNlcjI2MjEzNTQ2",
"organizations_url": "https://api.github.com/users/Doragd/orgs",
"received_events_url": "https://api.github.com/users/Doragd/received_events",
"repos_url": "https://api.github.com/users/Doragd/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Doragd/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Doragd/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Doragd",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2840/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2840/timeline | null | completed | null | null | 14.613056 | 4,739 |
https://api.github.com/repos/huggingface/datasets/issues/2839 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2839/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2839/comments | https://api.github.com/repos/huggingface/datasets/issues/2839/events | https://github.com/huggingface/datasets/issues/2839 | 980,271,715 | MDU6SXNzdWU5ODAyNzE3MTU= | 2,839 | OpenWebText: NonMatchingSplitsSizesError | {
"avatar_url": "https://avatars.githubusercontent.com/u/24695242?v=4",
"events_url": "https://api.github.com/users/thomasw21/events{/privacy}",
"followers_url": "https://api.github.com/users/thomasw21/followers",
"following_url": "https://api.github.com/users/thomasw21/following{/other_user}",
"gists_url": "https://api.github.com/users/thomasw21/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/thomasw21",
"id": 24695242,
"login": "thomasw21",
"node_id": "MDQ6VXNlcjI0Njk1MjQy",
"organizations_url": "https://api.github.com/users/thomasw21/orgs",
"received_events_url": "https://api.github.com/users/thomasw21/received_events",
"repos_url": "https://api.github.com/users/thomasw21/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/thomasw21/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thomasw21/subscriptions",
"type": "User",
"url": "https://api.github.com/users/thomasw21",
"user_view_type": "public"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists... | null | [
"Thanks for reporting, I'm updating the verifications metadata",
"I just regenerated the verifications metadata and noticed that nothing changed: the data file is fine (the checksum didn't change), and the number of examples is still 8013769. Not sure how you managed to get 7982430 examples.\r\n\r\nCan you try to... | 2021-08-26T13:50:26Z | 2021-09-21T14:12:40Z | 2021-09-21T14:09:43Z | CONTRIBUTOR | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ## Describe the bug
When downloading `openwebtext`, I'm getting:
```
datasets.utils.info_utils.NonMatchingSplitsSizesError: [{'expected': SplitInfo(name='train', num_bytes=39769494896, num_examples=8013769, dataset_name='openwebtext'), 'recorded': SplitInfo(name='train', num_bytes=39611023912, num_examples=7982430, dataset_name='openwebtext')}]
```
I suspect that the file we download from has changed since the size doesn't look like to match with documentation
`Downloading: 0%| | 0.00/12.9G [00:00<?, ?B/s]` This suggest the total size is 12.9GB, whereas the one documented mentions `Size of downloaded dataset files: 12283.35 MB`.
## Steps to reproduce the bug
```python
from datasets import load_dataset
load_dataset("openwebtext", download_mode="force_redownload")
```
## Expected results
Loading is successful
## Actual results
Loading throws above error.
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.10.2
- Platform: linux (Redhat version 8.1)
- Python version: 3.8
- PyArrow version: 4.0.1
| {
"avatar_url": "https://avatars.githubusercontent.com/u/24695242?v=4",
"events_url": "https://api.github.com/users/thomasw21/events{/privacy}",
"followers_url": "https://api.github.com/users/thomasw21/followers",
"following_url": "https://api.github.com/users/thomasw21/following{/other_user}",
"gists_url": "https://api.github.com/users/thomasw21/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/thomasw21",
"id": 24695242,
"login": "thomasw21",
"node_id": "MDQ6VXNlcjI0Njk1MjQy",
"organizations_url": "https://api.github.com/users/thomasw21/orgs",
"received_events_url": "https://api.github.com/users/thomasw21/received_events",
"repos_url": "https://api.github.com/users/thomasw21/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/thomasw21/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thomasw21/subscriptions",
"type": "User",
"url": "https://api.github.com/users/thomasw21",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2839/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2839/timeline | null | completed | null | null | 624.321389 | 4,740 |
https://api.github.com/repos/huggingface/datasets/issues/2837 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2837/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2837/comments | https://api.github.com/repos/huggingface/datasets/issues/2837/events | https://github.com/huggingface/datasets/issues/2837 | 979,298,297 | MDU6SXNzdWU5NzkyOTgyOTc= | 2,837 | prepare_module issue when loading from read-only fs | {
"avatar_url": "https://avatars.githubusercontent.com/u/8976546?v=4",
"events_url": "https://api.github.com/users/Dref360/events{/privacy}",
"followers_url": "https://api.github.com/users/Dref360/followers",
"following_url": "https://api.github.com/users/Dref360/following{/other_user}",
"gists_url": "https://api.github.com/users/Dref360/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Dref360",
"id": 8976546,
"login": "Dref360",
"node_id": "MDQ6VXNlcjg5NzY1NDY=",
"organizations_url": "https://api.github.com/users/Dref360/orgs",
"received_events_url": "https://api.github.com/users/Dref360/received_events",
"repos_url": "https://api.github.com/users/Dref360/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Dref360/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Dref360/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Dref360",
"user_view_type": "public"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"Hello, I opened #2887 to fix this."
] | 2021-08-25T15:21:26Z | 2021-10-05T17:58:22Z | 2021-10-05T17:58:22Z | CONTRIBUTOR | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ## Describe the bug
When we use prepare_module from a readonly file system, we create a FileLock using the `local_path`.
This path is not necessarily writable.
`lock_path = local_path + ".lock"`
## Steps to reproduce the bug
Run `load_dataset` on a readonly python loader file.
```python
ds = load_dataset(
python_loader, data_files={"train": train_path, "test": test_path}
)
```
where `python_loader` is a path to a file located in a readonly folder.
## Expected results
This should work I think?
## Actual results
```python
return load_dataset(
File "/usr/local/lib/python3.8/dist-packages/datasets/load.py", line 711, in load_dataset
module_path, hash, resolved_file_path = prepare_module(
File "/usr/local/lib/python3.8/dist-packages/datasets/load.py", line 465, in prepare_module
with FileLock(lock_path):
File "/usr/local/lib/python3.8/dist-packages/datasets/utils/filelock.py", line 314, in __enter__
self.acquire()
File "/usr/local/lib/python3.8/dist-packages/datasets/utils/filelock.py", line 263, in acquire
self._acquire()
File "/usr/local/lib/python3.8/dist-packages/datasets/utils/filelock.py", line 378, in _acquire
fd = os.open(self._lock_file, open_mode)
OSError: [Errno 30] Read-only file system: 'YOUR_FILE.py.lock'
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.7.0
- Platform: macOS-10.15.7-x86_64-i386-64bit
- Python version: 3.8.8
- PyArrow version: 3.0.0
| {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2837/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2837/timeline | null | completed | null | null | 986.615556 | 4,742 |
https://api.github.com/repos/huggingface/datasets/issues/2833 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2833/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2833/comments | https://api.github.com/repos/huggingface/datasets/issues/2833/events | https://github.com/huggingface/datasets/issues/2833 | 978,296,140 | MDU6SXNzdWU5NzgyOTYxNDA= | 2,833 | IndexError when accessing first element of a Dataset if first RecordBatch is empty | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
} | [] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists... | null | [] | 2021-08-24T16:49:20Z | 2021-08-24T17:21:17Z | 2021-08-24T17:21:17Z | MEMBER | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | The computation of the offsets of the underlying Table of a Dataset has some issues if the first RecordBatch is empty.
```python
from datasets import Dataset
import pyarrow as pa
pa_table = pa.Table.from_pydict({"a": [1]})
pa_table2 = pa.Table.from_pydict({"a": []}, schema=pa_table.schema)
ds_table = pa.concat_tables([pa_table2, pa_table])
dataset = Dataset(ds_table)
print([len(b) for b in dataset.data._batches])
# [0, 1]
print(dataset.data._offsets)
# [0 0 1] (should be [0, 1])
dataset[0]
```
raises
```python
---------------------------------------------------------------------------
IndexError Traceback (most recent call last)
/usr/local/lib/python3.7/dist-packages/datasets/table.py in _interpolation_search(arr, x)
90 else:
91 i, j = i, k
---> 92 raise IndexError(f"Invalid query '{x}' for size {arr[-1] if len(arr) else 'none'}.")
93
94
IndexError: Invalid query '0' for size 1.
```
This can be fixed by ignoring empty batches when computing `table._batches` and `table._offsets`
cc @SaulLu | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 1,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2833/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2833/timeline | null | completed | null | null | 0.5325 | 4,746 |
https://api.github.com/repos/huggingface/datasets/issues/2832 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2832/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2832/comments | https://api.github.com/repos/huggingface/datasets/issues/2832/events | https://github.com/huggingface/datasets/issues/2832 | 978,012,800 | MDU6SXNzdWU5NzgwMTI4MDA= | 2,832 | Logging levels not taken into account | {
"avatar_url": "https://avatars.githubusercontent.com/u/30755778?v=4",
"events_url": "https://api.github.com/users/LysandreJik/events{/privacy}",
"followers_url": "https://api.github.com/users/LysandreJik/followers",
"following_url": "https://api.github.com/users/LysandreJik/following{/other_user}",
"gists_url": "https://api.github.com/users/LysandreJik/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/LysandreJik",
"id": 30755778,
"login": "LysandreJik",
"node_id": "MDQ6VXNlcjMwNzU1Nzc4",
"organizations_url": "https://api.github.com/users/LysandreJik/orgs",
"received_events_url": "https://api.github.com/users/LysandreJik/received_events",
"repos_url": "https://api.github.com/users/LysandreJik/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/LysandreJik/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/LysandreJik/subscriptions",
"type": "User",
"url": "https://api.github.com/users/LysandreJik",
"user_view_type": "public"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
... | null | [
"I just take a look at all the outputs produced by `datasets` using the different log-levels.\r\nAs far as i can tell using `datasets==1.17.0` they overall issue seems to be fixed.\r\n\r\nHowever, I noticed that there is one tqdm based progress indicator appearing on STDERR that I can simply not suppress.\r\n```\r\... | 2021-08-24T11:50:41Z | 2023-07-12T17:19:30Z | 2023-07-12T17:19:29Z | MEMBER | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ## Describe the bug
The `logging` module isn't working as intended relative to the levels to set.
## Steps to reproduce the bug
```python
from datasets import logging
logging.set_verbosity_debug()
logger = logging.get_logger()
logger.error("ERROR")
logger.warning("WARNING")
logger.info("INFO")
logger.debug("DEBUG"
```
## Expected results
I expect all logs to be output since I'm putting a `debug` level.
## Actual results
Only the two first logs are output.
## Environment info
- `datasets` version: 1.11.0
- Platform: Linux-5.13.9-arch1-1-x86_64-with-glibc2.33
- Python version: 3.9.6
- PyArrow version: 5.0.0
## To go further
This logging issue appears in `datasets` but not in `transformers`. It happens because there is no handler defined for the logger. When no handler is defined, the `logging` library will output a one-off error to stderr, using a `StderrHandler` with level `WARNING`.
`transformers` sets a default `StreamHandler` [here](https://github.com/huggingface/transformers/blob/5c6eca71a983bae2589eed01e5c04fcf88ba5690/src/transformers/utils/logging.py#L86) | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
} | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2832/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2832/timeline | null | completed | null | null | 16,493.48 | 4,747 |
https://api.github.com/repos/huggingface/datasets/issues/2829 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2829/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2829/comments | https://api.github.com/repos/huggingface/datasets/issues/2829/events | https://github.com/huggingface/datasets/issues/2829 | 977,233,360 | MDU6SXNzdWU5NzcyMzMzNjA= | 2,829 | Optimize streaming from TAR archives | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
} | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
},
{
"color": "fef2c0",
"default": fals... | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists... | null | [
"Closed by: \r\n- #3066"
] | 2021-08-23T16:56:40Z | 2022-09-21T14:29:46Z | 2022-09-21T14:08:39Z | MEMBER | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | Hi ! As you know TAR has some constraints for data streaming. While it is optimized for buffering, the files in the TAR archive **need to be streamed in order**. It means that we can't choose which file to stream from, and this notation is to be avoided for TAR archives:
```
tar://books_large_p1.txt::https://storage.googleapis.com/huggingface-nlp/datasets/bookcorpus/bookcorpus.tar.bz2
```
Instead, I suggest we implement `iter_archive` for the `StreamingDownloadManager`.
The regular `DownloadManager` already has it.
Then we will have to update the json/txt/csv/etc. loaders to make them use `iter_archive` on TAR archives.
That's also what Tensorflow Datasets is doing in this case.
See this [dataset](https://github.com/tensorflow/datasets/blob/93895059c80a9e05805e8f32a2e310f66a23fc98/tensorflow_datasets/image_classification/flowers.py) for example.
Therefore instead of doing
```python
uncompressed = dl_manager.extract(tar_archive)
filename = "books_large_p1.txt"
with open(os.path.join(uncompressed, filename)) as f:
for line in f:
...
```
we'll do
```python
for filename, f in dl_manager.iter_archive(tar_archive):
for line in f:
...
``` | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2829/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2829/timeline | null | completed | null | null | 9,453.199722 | 4,750 |
https://api.github.com/repos/huggingface/datasets/issues/2826 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2826/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2826/comments | https://api.github.com/repos/huggingface/datasets/issues/2826/events | https://github.com/huggingface/datasets/issues/2826 | 976,974,254 | MDU6SXNzdWU5NzY5NzQyNTQ= | 2,826 | Add a Text Classification dataset: KanHope | {
"avatar_url": "https://avatars.githubusercontent.com/u/46108405?v=4",
"events_url": "https://api.github.com/users/adeepH/events{/privacy}",
"followers_url": "https://api.github.com/users/adeepH/followers",
"following_url": "https://api.github.com/users/adeepH/following{/other_user}",
"gists_url": "https://api.github.com/users/adeepH/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/adeepH",
"id": 46108405,
"login": "adeepH",
"node_id": "MDQ6VXNlcjQ2MTA4NDA1",
"organizations_url": "https://api.github.com/users/adeepH/orgs",
"received_events_url": "https://api.github.com/users/adeepH/received_events",
"repos_url": "https://api.github.com/users/adeepH/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/adeepH/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/adeepH/subscriptions",
"type": "User",
"url": "https://api.github.com/users/adeepH",
"user_view_type": "public"
} | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
}
] | closed | false | null | [] | null | [
"Hi ! In your script it looks like you're trying to load the dataset `bn_hate_speech,`, not KanHope.\r\n\r\nMoreover the error `KeyError: ' '` means that you have a feature of type ClassLabel, but for a certain example of the dataset, it looks like the label is empty (it's just a string with a space). Can you make ... | 2021-08-23T12:21:58Z | 2021-10-01T18:06:59Z | 2021-10-01T18:06:59Z | CONTRIBUTOR | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ## Adding a Dataset
- **Name:** *KanHope*
- **Description:** *A code-mixed English-Kannada dataset for Hope speech detection*
- **Paper:** *https://arxiv.org/abs/2108.04616* (I am the author of the paper}
- **Author:** *[AdeepH](https://github.com/adeepH)*
- **Data:** *https://github.com/adeepH/KanHope/tree/main/dataset*
- **Motivation:** *The dataset is amongst the very few resources available for code-mixed Dravidian languages*
- I tried following the steps as per the instructions. However, could not resolve an error. Any help would be appreciated.
- The dataset card and the scripts for the dataset *https://github.com/adeepH/datasets/tree/multilingual-hope-speech/datasets/mhs_eval*
```
Using custom data configuration default
Downloading and preparing dataset bn_hate_speech/default (download: Unknown size, generated: Unknown size, post-processed: Unknown size, total: Unknown size) to /root/.cache/huggingface/datasets/bn_hate_speech/default/0.0.0/5f417ddc89777278abd29988f909f39495f0ec802090f7d8fa63b5bffb121762...
---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
<ipython-input-114-4a9cdb519e4c> in <module>()
1 from datasets import load_dataset
2
----> 3 data = load_dataset('/content/bn')
9 frames
/usr/local/lib/python3.7/dist-packages/datasets/load.py in load_dataset(path, name, data_dir, data_files, split, cache_dir, features, download_config, download_mode, ignore_verifications, keep_in_memory, save_infos, script_version, use_auth_token, task, streaming, **config_kwargs)
850 ignore_verifications=ignore_verifications,
851 try_from_hf_gcs=try_from_hf_gcs,
--> 852 use_auth_token=use_auth_token,
853 )
854
/usr/local/lib/python3.7/dist-packages/datasets/builder.py in download_and_prepare(self, download_config, download_mode, ignore_verifications, try_from_hf_gcs, dl_manager, base_path, use_auth_token, **download_and_prepare_kwargs)
614 if not downloaded_from_gcs:
615 self._download_and_prepare(
--> 616 dl_manager=dl_manager, verify_infos=verify_infos, **download_and_prepare_kwargs
617 )
618 # Sync info
/usr/local/lib/python3.7/dist-packages/datasets/builder.py in _download_and_prepare(self, dl_manager, verify_infos, **prepare_split_kwargs)
691 try:
692 # Prepare split will record examples associated to the split
--> 693 self._prepare_split(split_generator, **prepare_split_kwargs)
694 except OSError as e:
695 raise OSError(
/usr/local/lib/python3.7/dist-packages/datasets/builder.py in _prepare_split(self, split_generator)
1107 disable=bool(logging.get_verbosity() == logging.NOTSET),
1108 ):
-> 1109 example = self.info.features.encode_example(record)
1110 writer.write(example, key)
1111 finally:
/usr/local/lib/python3.7/dist-packages/datasets/features.py in encode_example(self, example)
1015 """
1016 example = cast_to_python_objects(example)
-> 1017 return encode_nested_example(self, example)
1018
1019 def encode_batch(self, batch):
/usr/local/lib/python3.7/dist-packages/datasets/features.py in encode_nested_example(schema, obj)
863 if isinstance(schema, dict):
864 return {
--> 865 k: encode_nested_example(sub_schema, sub_obj) for k, (sub_schema, sub_obj) in utils.zip_dict(schema, obj)
866 }
867 elif isinstance(schema, (list, tuple)):
/usr/local/lib/python3.7/dist-packages/datasets/features.py in <dictcomp>(.0)
863 if isinstance(schema, dict):
864 return {
--> 865 k: encode_nested_example(sub_schema, sub_obj) for k, (sub_schema, sub_obj) in utils.zip_dict(schema, obj)
866 }
867 elif isinstance(schema, (list, tuple)):
/usr/local/lib/python3.7/dist-packages/datasets/features.py in encode_nested_example(schema, obj)
890 # ClassLabel will convert from string to int, TranslationVariableLanguages does some checks
891 elif isinstance(schema, (ClassLabel, TranslationVariableLanguages, Value, _ArrayXD)):
--> 892 return schema.encode_example(obj)
893 # Other object should be directly convertible to a native Arrow type (like Translation and Translation)
894 return obj
/usr/local/lib/python3.7/dist-packages/datasets/features.py in encode_example(self, example_data)
665 # If a string is given, convert to associated integer
666 if isinstance(example_data, str):
--> 667 example_data = self.str2int(example_data)
668
669 # Allowing -1 to mean no label.
/usr/local/lib/python3.7/dist-packages/datasets/features.py in str2int(self, values)
623 if value not in self._str2int:
624 value = str(value).strip()
--> 625 output.append(self._str2int[str(value)])
626 else:
627 # No names provided, try to integerize
KeyError: ' '
``` | {
"avatar_url": "https://avatars.githubusercontent.com/u/46108405?v=4",
"events_url": "https://api.github.com/users/adeepH/events{/privacy}",
"followers_url": "https://api.github.com/users/adeepH/followers",
"following_url": "https://api.github.com/users/adeepH/following{/other_user}",
"gists_url": "https://api.github.com/users/adeepH/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/adeepH",
"id": 46108405,
"login": "adeepH",
"node_id": "MDQ6VXNlcjQ2MTA4NDA1",
"organizations_url": "https://api.github.com/users/adeepH/orgs",
"received_events_url": "https://api.github.com/users/adeepH/received_events",
"repos_url": "https://api.github.com/users/adeepH/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/adeepH/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/adeepH/subscriptions",
"type": "User",
"url": "https://api.github.com/users/adeepH",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2826/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2826/timeline | null | completed | null | null | 941.750278 | 4,753 |
https://api.github.com/repos/huggingface/datasets/issues/2825 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2825/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2825/comments | https://api.github.com/repos/huggingface/datasets/issues/2825/events | https://github.com/huggingface/datasets/issues/2825 | 976,584,926 | MDU6SXNzdWU5NzY1ODQ5MjY= | 2,825 | The datasets.map function does not load cached dataset after moving python script | {
"avatar_url": "https://avatars.githubusercontent.com/u/35392624?v=4",
"events_url": "https://api.github.com/users/hobbitlzy/events{/privacy}",
"followers_url": "https://api.github.com/users/hobbitlzy/followers",
"following_url": "https://api.github.com/users/hobbitlzy/following{/other_user}",
"gists_url": "https://api.github.com/users/hobbitlzy/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/hobbitlzy",
"id": 35392624,
"login": "hobbitlzy",
"node_id": "MDQ6VXNlcjM1MzkyNjI0",
"organizations_url": "https://api.github.com/users/hobbitlzy/orgs",
"received_events_url": "https://api.github.com/users/hobbitlzy/received_events",
"repos_url": "https://api.github.com/users/hobbitlzy/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/hobbitlzy/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/hobbitlzy/subscriptions",
"type": "User",
"url": "https://api.github.com/users/hobbitlzy",
"user_view_type": "public"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists... | null | [
"This also happened to me on COLAB.\r\nDetails:\r\nI ran the `run_mlm.py` in two different notebooks. \r\nIn the first notebook, I do tokenization since I can get 4 CPU cores without any GPUs, and save the cache into a folder which I copy to drive.\r\nIn the second notebook, I copy the cache folder from drive and r... | 2021-08-23T03:23:37Z | 2024-07-29T11:25:50Z | 2021-08-31T13:13:36Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ## Describe the bug
The datasets.map function caches the processed data to a certain directory. When the map function is called another time with totally the same parameters, the cached data are supposed to be reloaded instead of re-processing. However, it doesn't reuse cached data sometimes. I use the common data processing in different tasks, the datasets are processed again, the only difference is that I run them in different files.
## Steps to reproduce the bug
Just run the following codes in different .py files.
```python
if __name__ == '__main__':
from datasets import load_dataset
from transformers import AutoTokenizer
raw_datasets = load_dataset("wikitext", "wikitext-2-raw-v1")
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
def tokenize_function(examples):
return tokenizer(examples["text"], padding="max_length", truncation=True)
tokenized_datasets = raw_datasets.map(tokenize_function, batched=True)
```
## Expected results
The map function should reload data in the second or any later runs.
## Actual results
The processing happens in each run.
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.8.0
- Platform: linux
- Python version: 3.7.6
- PyArrow version: 3.0.0
This is the first time I report a bug. If there is any problem or confusing description, please let me know 😄.
| {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
} | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2825/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2825/timeline | null | completed | null | null | 201.833056 | 4,754 |
https://api.github.com/repos/huggingface/datasets/issues/2823 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2823/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2823/comments | https://api.github.com/repos/huggingface/datasets/issues/2823/events | https://github.com/huggingface/datasets/issues/2823 | 976,135,355 | MDU6SXNzdWU5NzYxMzUzNTU= | 2,823 | HF_DATASETS_CACHE variable in Windows | {
"avatar_url": "https://avatars.githubusercontent.com/u/8453798?v=4",
"events_url": "https://api.github.com/users/rp2839/events{/privacy}",
"followers_url": "https://api.github.com/users/rp2839/followers",
"following_url": "https://api.github.com/users/rp2839/following{/other_user}",
"gists_url": "https://api.github.com/users/rp2839/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/rp2839",
"id": 8453798,
"login": "rp2839",
"node_id": "MDQ6VXNlcjg0NTM3OTg=",
"organizations_url": "https://api.github.com/users/rp2839/orgs",
"received_events_url": "https://api.github.com/users/rp2839/received_events",
"repos_url": "https://api.github.com/users/rp2839/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/rp2839/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/rp2839/subscriptions",
"type": "User",
"url": "https://api.github.com/users/rp2839",
"user_view_type": "public"
} | [] | closed | false | null | [] | null | [
"Agh - I'm a muppet. No quote marks are needed.\r\nset HF_DATASETS_CACHE = C:\\Datasets\r\nworks as intended."
] | 2021-08-21T13:17:44Z | 2021-08-21T13:20:11Z | 2021-08-21T13:20:11Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | I can't seem to use a custom Cache directory in Windows. I have tried:
set HF_DATASETS_CACHE = "C:\Datasets"
set HF_DATASETS_CACHE = "C:/Datasets"
set HF_DATASETS_CACHE = "C:\\Datasets"
set HF_DATASETS_CACHE = "r'C:\Datasets'"
set HF_DATASETS_CACHE = "\Datasets"
set HF_DATASETS_CACHE = "/Datasets"
In each instance I get the "[WinError 123] The filename, directory name, or volume label syntax is incorrect" error when attempting to load a dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/8453798?v=4",
"events_url": "https://api.github.com/users/rp2839/events{/privacy}",
"followers_url": "https://api.github.com/users/rp2839/followers",
"following_url": "https://api.github.com/users/rp2839/following{/other_user}",
"gists_url": "https://api.github.com/users/rp2839/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/rp2839",
"id": 8453798,
"login": "rp2839",
"node_id": "MDQ6VXNlcjg0NTM3OTg=",
"organizations_url": "https://api.github.com/users/rp2839/orgs",
"received_events_url": "https://api.github.com/users/rp2839/received_events",
"repos_url": "https://api.github.com/users/rp2839/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/rp2839/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/rp2839/subscriptions",
"type": "User",
"url": "https://api.github.com/users/rp2839",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2823/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2823/timeline | null | completed | null | null | 0.040833 | 4,756 |
https://api.github.com/repos/huggingface/datasets/issues/2821 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2821/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2821/comments | https://api.github.com/repos/huggingface/datasets/issues/2821/events | https://github.com/huggingface/datasets/issues/2821 | 975,556,032 | MDU6SXNzdWU5NzU1NTYwMzI= | 2,821 | Cannot load linnaeus dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/48327001?v=4",
"events_url": "https://api.github.com/users/NielsRogge/events{/privacy}",
"followers_url": "https://api.github.com/users/NielsRogge/followers",
"following_url": "https://api.github.com/users/NielsRogge/following{/other_user}",
"gists_url": "https://api.github.com/users/NielsRogge/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/NielsRogge",
"id": 48327001,
"login": "NielsRogge",
"node_id": "MDQ6VXNlcjQ4MzI3MDAx",
"organizations_url": "https://api.github.com/users/NielsRogge/orgs",
"received_events_url": "https://api.github.com/users/NielsRogge/received_events",
"repos_url": "https://api.github.com/users/NielsRogge/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/NielsRogge/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/NielsRogge/subscriptions",
"type": "User",
"url": "https://api.github.com/users/NielsRogge",
"user_view_type": "public"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"Thanks for reporting ! #2852 fixed this error\r\n\r\nWe'll do a new release of `datasets` soon :)"
] | 2021-08-20T12:15:15Z | 2021-08-31T13:13:02Z | 2021-08-31T13:12:09Z | CONTRIBUTOR | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ## Describe the bug
The [linnaeus](https://huggingface.co/datasets/linnaeus) dataset cannot be loaded. To reproduce:
```
from datasets import load_dataset
datasets = load_dataset("linnaeus")
```
This results in:
```
Downloading and preparing dataset linnaeus/linnaeus (download: 17.36 MiB, generated: 8.74 MiB, post-processed: Unknown size, total: 26.10 MiB) to /root/.cache/huggingface/datasets/linnaeus/linnaeus/1.0.0/2ff05dbc256108233262f596e09e322dbc3db067202de14286913607cd9cb704...
---------------------------------------------------------------------------
ConnectionError Traceback (most recent call last)
<ipython-input-4-7ef3a88f6276> in <module>()
1 from datasets import load_dataset
2
----> 3 datasets = load_dataset("linnaeus")
11 frames
/usr/local/lib/python3.7/dist-packages/datasets/utils/file_utils.py in get_from_cache(url, cache_dir, force_download, proxies, etag_timeout, resume_download, user_agent, local_files_only, use_etag, max_retries, use_auth_token)
603 raise FileNotFoundError("Couldn't find file at {}".format(url))
604 _raise_if_offline_mode_is_enabled(f"Tried to reach {url}")
--> 605 raise ConnectionError("Couldn't reach {}".format(url))
606
607 # Try a second time
ConnectionError: Couldn't reach https://drive.google.com/u/0/uc?id=1OletxmPYNkz2ltOr9pyT0b0iBtUWxslh&export=download/
``` | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2821/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2821/timeline | null | completed | null | null | 264.948333 | 4,758 |
https://api.github.com/repos/huggingface/datasets/issues/2820 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2820/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2820/comments | https://api.github.com/repos/huggingface/datasets/issues/2820/events | https://github.com/huggingface/datasets/issues/2820 | 975,210,712 | MDU6SXNzdWU5NzUyMTA3MTI= | 2,820 | Downloading “reddit” dataset keeps timing out. | {
"avatar_url": "https://avatars.githubusercontent.com/u/43877130?v=4",
"events_url": "https://api.github.com/users/smeyerhot/events{/privacy}",
"followers_url": "https://api.github.com/users/smeyerhot/followers",
"following_url": "https://api.github.com/users/smeyerhot/following{/other_user}",
"gists_url": "https://api.github.com/users/smeyerhot/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/smeyerhot",
"id": 43877130,
"login": "smeyerhot",
"node_id": "MDQ6VXNlcjQzODc3MTMw",
"organizations_url": "https://api.github.com/users/smeyerhot/orgs",
"received_events_url": "https://api.github.com/users/smeyerhot/received_events",
"repos_url": "https://api.github.com/users/smeyerhot/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/smeyerhot/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/smeyerhot/subscriptions",
"type": "User",
"url": "https://api.github.com/users/smeyerhot",
"user_view_type": "public"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"```\r\nUsing custom data configuration default\r\nDownloading and preparing dataset reddit/default (download: 2.93 GiB, generated: 17.64 GiB, post-processed: Unknown size, total: 20.57 GiB) to /Volumes/My Passport for Mac/og-chat-data/reddit/default/1.0.0/98ba5abea674d3178f7588aa6518a5510dc0c6fa8176d9653a3546d5afc... | 2021-08-20T02:52:36Z | 2021-09-08T14:52:02Z | 2021-09-08T14:52:02Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ## Describe the bug
A clear and concise description of what the bug is.
Everytime I try and download the reddit dataset it times out before finishing and I have to try again.
There is some timeout error that I will post once it happens again.
## Steps to reproduce the bug
```python
from datasets import load_dataset
dataset = load_dataset("reddit", ignore_verifications=True, cache_dir="/Volumes/My Passport for Mac/og-chat-data")
```
## Expected results
A clear and concise description of the expected results.
I would expect the download to finish, or at least provide a parameter to extend the read timeout window.
## Actual results
Specify the actual results or traceback.
Shown below in error message.
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.11.0
- Platform: macOS
- Python version: 3.9.6 (conda env)
- PyArrow version: N/A
| {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2820/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2820/timeline | null | completed | null | null | 467.990556 | 4,759 |
https://api.github.com/repos/huggingface/datasets/issues/2818 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2818/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2818/comments | https://api.github.com/repos/huggingface/datasets/issues/2818/events | https://github.com/huggingface/datasets/issues/2818 | 974,552,009 | MDU6SXNzdWU5NzQ1NTIwMDk= | 2,818 | cannot load data from my loacal path | {
"avatar_url": "https://avatars.githubusercontent.com/u/46920280?v=4",
"events_url": "https://api.github.com/users/yang-collect/events{/privacy}",
"followers_url": "https://api.github.com/users/yang-collect/followers",
"following_url": "https://api.github.com/users/yang-collect/following{/other_user}",
"gists_url": "https://api.github.com/users/yang-collect/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/yang-collect",
"id": 46920280,
"login": "yang-collect",
"node_id": "MDQ6VXNlcjQ2OTIwMjgw",
"organizations_url": "https://api.github.com/users/yang-collect/orgs",
"received_events_url": "https://api.github.com/users/yang-collect/received_events",
"repos_url": "https://api.github.com/users/yang-collect/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/yang-collect/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/yang-collect/subscriptions",
"type": "User",
"url": "https://api.github.com/users/yang-collect",
"user_view_type": "public"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"Hi ! The `data_files` parameter must be a string, a list/tuple or a python dict.\r\n\r\nCan you check the type of your `config.train_path` please ? Or use `data_files=str(config.train_path)` ?"
] | 2021-08-19T11:13:30Z | 2023-07-25T17:42:15Z | 2023-07-25T17:42:15Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ## Describe the bug
I just want to directly load data from my local path,but find a bug.And I compare it with pandas to provide my local path is real.
here is my code
```python3
# print my local path
print(config.train_path)
# read data and print data length
tarin=pd.read_csv(config.train_path)
print(len(tarin))
# loading data by load_dataset
data = load_dataset('csv',data_files=config.train_path)
print(len(data))
```
## Steps to reproduce the bug
```python
C:\Users\wie\Documents\项目\文本分类\data\train.csv
7613
Traceback (most recent call last):
File "c:/Users/wie/Documents/项目/文本分类/lib/DataPrecess.py", line 17, in <module>
data = load_dataset('csv',data_files=config.train_path)
File "C:\Users\wie\Miniconda3\lib\site-packages\datasets\load.py", line 830, in load_dataset
**config_kwargs,
File "C:\Users\wie\Miniconda3\lib\site-packages\datasets\load.py", line 710, in load_dataset_builder
**config_kwargs,
File "C:\Users\wie\Miniconda3\lib\site-packages\datasets\builder.py", line 271, in __init__
**config_kwargs,
File "C:\Users\wie\Miniconda3\lib\site-packages\datasets\builder.py", line 386, in _create_builder_config
config_kwargs, custom_features=custom_features, use_auth_token=self.use_auth_token
File "C:\Users\wie\Miniconda3\lib\site-packages\datasets\builder.py", line 156, in create_config_id
raise ValueError("Please provide a valid `data_files` in `DatasetBuilder`")
ValueError: Please provide a valid `data_files` in `DatasetBuilder`
```
## Expected results
A clear and concise description of the expected results.
## Actual results
Specify the actual results or traceback.
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.11.0
- Platform: win10
- Python version: 3.7.9
- PyArrow version: 5.0.0
| {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2818/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2818/timeline | null | completed | null | null | 16,926.479167 | 4,761 |
https://api.github.com/repos/huggingface/datasets/issues/2813 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2813/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2813/comments | https://api.github.com/repos/huggingface/datasets/issues/2813/events | https://github.com/huggingface/datasets/issues/2813 | 973,470,580 | MDU6SXNzdWU5NzM0NzA1ODA= | 2,813 | Remove compression from xopen | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | [
{
"color": "c5def5",
"default": false,
"description": "Generic discussion on the library",
"id": 2067400324,
"name": "generic discussion",
"node_id": "MDU6TGFiZWwyMDY3NDAwMzI0",
"url": "https://api.github.com/repos/huggingface/datasets/labels/generic%20discussion"
}
] | closed | false | null | [] | null | [
"After discussing with @lhoestq, a reasonable alternative:\r\n- `download_manager.extract(urlpath)` adds prefixes to `urlpath` in the same way as `fsspec` does for protocols, but we implement custom prefixes for all compression formats: \r\n `bz2::http://domain.org/filename.bz2`\r\n- `xopen` parses the `urlpath` a... | 2021-08-18T09:35:59Z | 2021-08-23T15:59:14Z | 2021-08-23T15:59:14Z | MEMBER | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | We implemented support for streaming with 2 requirements:
- transparent use for the end user: just needs to pass the parameter `streaming=True`
- no additional work for the contributors: previous loading scripts should also work in streaming mode with no (or minor) changes; and new loading scripts should not involve additional code to support streaming
In order to fulfill these requirements, streaming implementation patched some Python functions:
- the `open(urlpath)` function was patched with `fsspec.open(urlpath)`
- the `os.path.join(urlpath, *others)` function was patched in order to add to `urlpath` hops (`::`) and extractor protocols (`zip://`), which are required by `fsspec.open`
Recently, we implemented support for streaming all archive+compression formats: zip, tar, gz, bz2, lz4, xz, zst; tar.gz, tar.bz2,...
Under the hood, the implementation:
- passes an additional parameter `compression` to `fsspec.open`, so that it performs the decompression on the fly: `fsspec.open(urlpath, compression=...)`
Some concerns have been raised about passing the parameter `compression` to `fsspec.open`:
- https://github.com/huggingface/datasets/pull/2786#discussion_r689550254
- #2811
The main argument is that if `open` decompresses the file and afterwards we call `gzip.open` on it, that will raise an error in `oscar` dataset:
```python
gzip.open(open(urlpath
```
While this is true:
- it is not natural/usual to call `open` inside `gzip.open` (never seen this before)
- indeed, this was recently (2 months ago) coded that way in `datasets` in order to allow streaming support (with previous implementation of streaming)
In this particular case, there is a natural fix solution: #2811:
- Revert the `open` inside the `gzip.open` (change done 2 months ago): `gzip.open(open(urlpath` => `gzip.open(urlpath`
- Patch `gzip.open(urlpath` with `fsspec.open(urlpath, compression="gzip"`
Are there other issues apart from this?
Note that there is an issue just because the open inside of the gzip.open. There is no issue in the other cases where datasets loading scripts use just
- `gzip.open`
- `open` (after having called dl_manager.download_and_extract)
TODO:
- [ ] Is this really an issue? Please enumerate the `datasets` loading scripts where this is problematic.
- For the moment, there are only 3 datasets where we have an `open` inside a `gzip.open`:
- oscar (since 23 June), mc4 (since 2 July) and c4 (since 2 July)
- In the 3 datasets, the only reason to put an open inside a gzip.open was indeed to force supporting streaming
- [ ] If this is indeed an issue, which are the possible alternatives? Pros/cons? | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2813/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2813/timeline | null | completed | null | null | 126.3875 | 4,766 |
https://api.github.com/repos/huggingface/datasets/issues/2808 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2808/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2808/comments | https://api.github.com/repos/huggingface/datasets/issues/2808/events | https://github.com/huggingface/datasets/issues/2808 | 971,882,320 | MDU6SXNzdWU5NzE4ODIzMjA= | 2,808 | Enable streaming for Wikipedia corpora | {
"avatar_url": "https://avatars.githubusercontent.com/u/26859204?v=4",
"events_url": "https://api.github.com/users/lewtun/events{/privacy}",
"followers_url": "https://api.github.com/users/lewtun/followers",
"following_url": "https://api.github.com/users/lewtun/following{/other_user}",
"gists_url": "https://api.github.com/users/lewtun/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lewtun",
"id": 26859204,
"login": "lewtun",
"node_id": "MDQ6VXNlcjI2ODU5MjA0",
"organizations_url": "https://api.github.com/users/lewtun/orgs",
"received_events_url": "https://api.github.com/users/lewtun/received_events",
"repos_url": "https://api.github.com/users/lewtun/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lewtun/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lewtun/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lewtun",
"user_view_type": "public"
} | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | null | [] | null | [
"Closing as this has been addressed in https://github.com/huggingface/datasets/pull/5689."
] | 2021-08-16T15:59:12Z | 2023-07-20T13:45:30Z | 2023-07-20T13:45:30Z | MEMBER | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | **Is your feature request related to a problem? Please describe.**
Several of the [Wikipedia corpora](https://huggingface.co/datasets?search=wiki) on the Hub involve quite large files that would be a good candidate for streaming. Currently it is not possible to stream these corpora:
```python
from datasets import load_dataset
# Throws ValueError: Builder wikipedia is not streamable.
wiki_dataset_streamed = load_dataset("wikipedia", "20200501.en", split="train", streaming=True)
```
Given that these corpora are derived from Wikipedia dumps in XML format which are then processed with Apache Beam, I am not sure whether streaming is possible in principle. The goal of this issue is to discuss whether this feature even makes sense :)
**Describe the solution you'd like**
It would be nice to be able to stream Wikipedia corpora from the Hub with something like
```python
from datasets import load_dataset
wiki_dataset_streamed = load_dataset("wikipedia", "20200501.en", split="train", streaming=True)
``` | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
} | {
"+1": 5,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 5,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2808/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2808/timeline | null | completed | null | null | 16,869.771667 | 4,771 |
https://api.github.com/repos/huggingface/datasets/issues/2799 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2799/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2799/comments | https://api.github.com/repos/huggingface/datasets/issues/2799/events | https://github.com/huggingface/datasets/issues/2799 | 970,507,351 | MDU6SXNzdWU5NzA1MDczNTE= | 2,799 | Loading JSON throws ArrowNotImplementedError | {
"avatar_url": "https://avatars.githubusercontent.com/u/26859204?v=4",
"events_url": "https://api.github.com/users/lewtun/events{/privacy}",
"followers_url": "https://api.github.com/users/lewtun/followers",
"following_url": "https://api.github.com/users/lewtun/following{/other_user}",
"gists_url": "https://api.github.com/users/lewtun/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lewtun",
"id": 26859204,
"login": "lewtun",
"node_id": "MDQ6VXNlcjI2ODU5MjA0",
"organizations_url": "https://api.github.com/users/lewtun/orgs",
"received_events_url": "https://api.github.com/users/lewtun/received_events",
"repos_url": "https://api.github.com/users/lewtun/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lewtun/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lewtun/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lewtun",
"user_view_type": "public"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"Hi @lewtun, thanks for reporting.\r\n\r\nApparently, `pyarrow.json` tries to cast timestamp-like fields in your JSON file to pyarrow timestamp type, and it fails with `ArrowNotImplementedError`.\r\n\r\nI will investigate if there is a way to tell pyarrow not to try that timestamp casting.",
"I think the issue is... | 2021-08-13T15:31:48Z | 2022-01-10T18:59:32Z | 2022-01-10T18:59:32Z | MEMBER | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ## Describe the bug
I have created a [dataset](https://huggingface.co/datasets/lewtun/github-issues-test) of GitHub issues in line-separated JSON format and am finding that I cannot load it with the `json` loading script (see stack trace below).
Curiously, there is no problem loading the dataset with `pandas` which suggests some incorrect type inference is being made on the `datasets` side. For example, the stack trace indicates that some URL fields are being parsed as timestamps.
You can find a Colab notebook which reproduces the error [here](https://colab.research.google.com/drive/1YUCM0j1vx5ZrouQbYSzal6RwB4-Aoh4o?usp=sharing).
**Edit:** If one repeatedly tries to load the dataset, it _eventually_ works but I think it would still be good to understand why it fails in the first place :)
## Steps to reproduce the bug
```python
from datasets import load_dataset
from huggingface_hub import hf_hub_url
import pandas as pd
# returns https://huggingface.co/datasets/lewtun/github-issues-test/resolve/main/issues-datasets.jsonl
data_files = hf_hub_url(repo_id="lewtun/github-issues-test", filename="issues-datasets.jsonl", repo_type="dataset")
# throws ArrowNotImplementedError
dset = load_dataset("json", data_files=data_files, split="test")
# no problem with pandas ...
df = pd.read_json(data_files, orient="records", lines=True)
df.head()
```
## Expected results
I can load any line-separated JSON file, similar to `pandas`.
## Actual results
```
---------------------------------------------------------------------------
ArrowNotImplementedError Traceback (most recent call last)
<ipython-input-7-5b8e82b6c3a2> in <module>()
----> 1 dset = load_dataset("json", data_files=data_files, split="test")
9 frames
/usr/local/lib/python3.7/dist-packages/pyarrow/error.pxi in pyarrow.lib.check_status()
ArrowNotImplementedError: JSON conversion to struct<url: timestamp[s], html_url: timestamp[s], labels_url: timestamp[s], id: int64, node_id: timestamp[s], number: int64, title: timestamp[s], description: timestamp[s], creator: struct<login: timestamp[s], id: int64, node_id: timestamp[s], avatar_url: timestamp[s], gravatar_id: timestamp[s], url: timestamp[s], html_url: timestamp[s], followers_url: timestamp[s], following_url: timestamp[s], gists_url: timestamp[s], starred_url: timestamp[s], subscriptions_url: timestamp[s], organizations_url: timestamp[s], repos_url: timestamp[s], events_url: timestamp[s], received_events_url: timestamp[s], type: timestamp[s], site_admin: bool>, open_issues: int64, closed_issues: int64, state: timestamp[s], created_at: timestamp[s], updated_at: timestamp[s], due_on: timestamp[s], closed_at: timestamp[s]> is not supported
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.11.0
- Platform: Linux-5.4.104+-x86_64-with-Ubuntu-18.04-bionic
- Python version: 3.7.11
- PyArrow version: 3.0.0
| {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2799/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2799/timeline | null | completed | null | null | 3,603.462222 | 4,780 |
https://api.github.com/repos/huggingface/datasets/issues/2788 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2788/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2788/comments | https://api.github.com/repos/huggingface/datasets/issues/2788/events | https://github.com/huggingface/datasets/issues/2788 | 967,149,389 | MDU6SXNzdWU5NjcxNDkzODk= | 2,788 | How to sample every file in a list of files making up a split in a dataset when loading? | {
"avatar_url": "https://avatars.githubusercontent.com/u/11220949?v=4",
"events_url": "https://api.github.com/users/brijow/events{/privacy}",
"followers_url": "https://api.github.com/users/brijow/followers",
"following_url": "https://api.github.com/users/brijow/following{/other_user}",
"gists_url": "https://api.github.com/users/brijow/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/brijow",
"id": 11220949,
"login": "brijow",
"node_id": "MDQ6VXNlcjExMjIwOTQ5",
"organizations_url": "https://api.github.com/users/brijow/orgs",
"received_events_url": "https://api.github.com/users/brijow/received_events",
"repos_url": "https://api.github.com/users/brijow/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/brijow/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/brijow/subscriptions",
"type": "User",
"url": "https://api.github.com/users/brijow",
"user_view_type": "public"
} | [] | closed | false | null | [] | null | [
"Hi ! This is not possible just with `load_dataset`.\r\n\r\nYou can do something like this instead:\r\n```python\r\nseed=42\r\ndata_files_dict = {\r\n \"train\": [train_file1, train_file2],\r\n \"test\": [test_file1, test_file2],\r\n \"val\": [val_file1, val_file2]\r\n}\r\ndataset = datasets.load_dataset(\... | 2021-08-11T17:43:21Z | 2023-07-25T17:40:50Z | 2023-07-25T17:40:50Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | I am loading a dataset with multiple train, test, and validation files like this:
```
data_files_dict = {
"train": [train_file1, train_file2],
"test": [test_file1, test_file2],
"val": [val_file1, val_file2]
}
dataset = datasets.load_dataset(
"csv",
data_files=data_files_dict,
split=['train[:8]', 'test[:8]', 'val[:8]']
)
```
However, this only selects the first 8 rows from train_file1, test_file1, val_file1, since they are the first files in the lists.
I'm trying to formulate a split argument that can sample from each file specified in my list of files that make up each split.
Is this type of splitting supported? If so, how can I do it? | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2788/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2788/timeline | null | completed | null | null | 17,111.958056 | 4,790 |
https://api.github.com/repos/huggingface/datasets/issues/2787 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2787/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2787/comments | https://api.github.com/repos/huggingface/datasets/issues/2787/events | https://github.com/huggingface/datasets/issues/2787 | 967,018,406 | MDU6SXNzdWU5NjcwMTg0MDY= | 2,787 | ConnectionError: Couldn't reach https://raw.githubusercontent.com | {
"avatar_url": "https://avatars.githubusercontent.com/u/39627475?v=4",
"events_url": "https://api.github.com/users/jinec/events{/privacy}",
"followers_url": "https://api.github.com/users/jinec/followers",
"following_url": "https://api.github.com/users/jinec/following{/other_user}",
"gists_url": "https://api.github.com/users/jinec/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/jinec",
"id": 39627475,
"login": "jinec",
"node_id": "MDQ6VXNlcjM5NjI3NDc1",
"organizations_url": "https://api.github.com/users/jinec/orgs",
"received_events_url": "https://api.github.com/users/jinec/received_events",
"repos_url": "https://api.github.com/users/jinec/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/jinec/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jinec/subscriptions",
"type": "User",
"url": "https://api.github.com/users/jinec",
"user_view_type": "public"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"the bug code locate in :\r\n if data_args.task_name is not None:\r\n # Downloading and loading a dataset from the hub.\r\n datasets = load_dataset(\"glue\", data_args.task_name, cache_dir=model_args.cache_dir)",
"Hi @jinec,\r\n\r\nFrom time to time we get this kind of `ConnectionError` coming fr... | 2021-08-11T16:19:01Z | 2023-10-03T12:39:25Z | 2021-08-18T15:09:18Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | Hello,
I am trying to run run_glue.py and it gives me this error -
Traceback (most recent call last):
File "E:/BERT/pytorch_hugging/transformers/examples/pytorch/text-classification/run_glue.py", line 546, in <module>
main()
File "E:/BERT/pytorch_hugging/transformers/examples/pytorch/text-classification/run_glue.py", line 250, in main
datasets = load_dataset("glue", data_args.task_name, cache_dir=model_args.cache_dir)
File "C:\install\Anaconda3\envs\huggingface\lib\site-packages\datasets\load.py", line 718, in load_dataset
use_auth_token=use_auth_token,
File "C:\install\Anaconda3\envs\huggingface\lib\site-packages\datasets\load.py", line 320, in prepare_module
local_path = cached_path(file_path, download_config=download_config)
File "C:\install\Anaconda3\envs\huggingface\lib\site-packages\datasets\utils\file_utils.py", line 291, in cached_path
use_auth_token=download_config.use_auth_token,
File "C:\install\Anaconda3\envs\huggingface\lib\site-packages\datasets\utils\file_utils.py", line 623, in get_from_cache
raise ConnectionError("Couldn't reach {}".format(url))
ConnectionError: Couldn't reach https://raw.githubusercontent.com/huggingface/datasets/1.7.0/datasets/glue/glue.py
Trying to do python run_glue.py --model_name_or_path
bert-base-cased
--task_name
mrpc
--do_train
--do_eval
--max_seq_length
128
--per_device_train_batch_size
32
--learning_rate
2e-5
--num_train_epochs
3
--output_dir
./tmp/mrpc/
Is this something on my end? From what I can tell, this was re-fixeded by @fullyz a few months ago.
Thank you!
| {
"avatar_url": "https://avatars.githubusercontent.com/u/39627475?v=4",
"events_url": "https://api.github.com/users/jinec/events{/privacy}",
"followers_url": "https://api.github.com/users/jinec/followers",
"following_url": "https://api.github.com/users/jinec/following{/other_user}",
"gists_url": "https://api.github.com/users/jinec/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/jinec",
"id": 39627475,
"login": "jinec",
"node_id": "MDQ6VXNlcjM5NjI3NDc1",
"organizations_url": "https://api.github.com/users/jinec/orgs",
"received_events_url": "https://api.github.com/users/jinec/received_events",
"repos_url": "https://api.github.com/users/jinec/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/jinec/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jinec/subscriptions",
"type": "User",
"url": "https://api.github.com/users/jinec",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2787/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2787/timeline | null | completed | null | null | 166.838056 | 4,791 |
https://api.github.com/repos/huggingface/datasets/issues/2781 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2781/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2781/comments | https://api.github.com/repos/huggingface/datasets/issues/2781/events | https://github.com/huggingface/datasets/issues/2781 | 964,805,351 | MDU6SXNzdWU5NjQ4MDUzNTE= | 2,781 | Latest v2.0.0 release of sacrebleu has broken some metrics | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [] | 2021-08-10T09:59:41Z | 2021-08-10T11:16:07Z | 2021-08-10T11:16:07Z | MEMBER | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ## Describe the bug
After `sacrebleu` v2.0.0 release (see changes here: https://github.com/mjpost/sacrebleu/pull/152/files#diff-2553a315bb1f7e68c9c1b00d56eaeb74f5205aeb3a189bc3e527b122c6078795L17-R15), some of `datasets` metrics are broken:
- Default tokenizer `sacrebleu.DEFAULT_TOKENIZER` no longer exists:
- #2739
- #2778
- Bleu tokenizers are no longer accessible with `sacrebleu.TOKENIZERS`:
- #2779
- `corpus_bleu` args have been renamed from `(sys_stream, ref_streams)` to `(hipotheses, references)`:
- #2782 | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2781/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2781/timeline | null | completed | null | null | 1.273889 | 4,795 |
https://api.github.com/repos/huggingface/datasets/issues/2775 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2775/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2775/comments | https://api.github.com/repos/huggingface/datasets/issues/2775/events | https://github.com/huggingface/datasets/issues/2775 | 964,303,626 | MDU6SXNzdWU5NjQzMDM2MjY= | 2,775 | `generate_random_fingerprint()` deterministic with 🤗Transformers' `set_seed()` | {
"avatar_url": "https://avatars.githubusercontent.com/u/1170062?v=4",
"events_url": "https://api.github.com/users/mbforbes/events{/privacy}",
"followers_url": "https://api.github.com/users/mbforbes/followers",
"following_url": "https://api.github.com/users/mbforbes/following{/other_user}",
"gists_url": "https://api.github.com/users/mbforbes/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mbforbes",
"id": 1170062,
"login": "mbforbes",
"node_id": "MDQ6VXNlcjExNzAwNjI=",
"organizations_url": "https://api.github.com/users/mbforbes/orgs",
"received_events_url": "https://api.github.com/users/mbforbes/received_events",
"repos_url": "https://api.github.com/users/mbforbes/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mbforbes/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mbforbes/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mbforbes",
"user_view_type": "public"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"I dug into what I believe is the root of this issue and added a repro in my comment. If this is better addressed as a cross-team issue, let me know and I can open an issue in the Transformers repo",
"Hi !\r\n\r\nIMO we shouldn't try to modify `set_seed` from transformers but maybe make `datasets` have its own RN... | 2021-08-09T19:28:51Z | 2024-01-26T15:05:36Z | 2024-01-26T15:05:35Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ## Describe the bug
**Update:** I dug into this to try to reproduce the underlying issue, and I believe it's that `set_seed()` from the `transformers` library makes the "random" fingerprint identical each time. I believe this is still a bug, because `datasets` is used exactly this way in `transformers` after `set_seed()` has been called, and I think that using `set_seed()` is a standard procedure to aid reproducibility. I've added more details to reproduce this below.
Hi there! I'm using my own local dataset and custom preprocessing function. My preprocessing function seems to be unpickle-able, perhaps because it is from a closure (will debug this separately). I get this warning, which is expected:
https://github.com/huggingface/datasets/blob/450b9174765374111e5c6daab0ed294bc3d9b639/src/datasets/fingerprint.py#L260-L265
However, what's not expected is that the `datasets` actually _does_ seem to cache and reuse this dataset between runs! After that line, the next thing that's logged looks like:
```text
Loading cached processed dataset at /home/xxx/.cache/huggingface/datasets/csv/default-xxx/0.0.0/xxx/cache-xxx.arrow
```
The path is exactly the same each run (e.g., last 26 runs).
This becomes a problem because I'll pass in the `--max_eval_samples` flag to the HuggingFace example script I'm running off of ([run_swag.py](https://github.com/huggingface/transformers/blob/master/examples/pytorch/multiple-choice/run_swag.py)). The fact that the cached dataset is reused means this flag gets ignored. I'll try to load 100 examples, and it will load the full cached 1,000,000.
I think that
https://github.com/huggingface/datasets/blob/450b9174765374111e5c6daab0ed294bc3d9b639/src/datasets/fingerprint.py#L248
... is actually consistent because randomness is being controlled in HuggingFace/Transformers for reproducibility. I've added a demo of this below.
## Steps to reproduce the bug
```python
# Contents of print_fingerprint.py
from transformers import set_seed
from datasets.fingerprint import generate_random_fingerprint
set_seed(42)
print(generate_random_fingerprint())
```
```bash
for i in {0..10}; do
python print_fingerprint.py
done
1c80317fa3b1799d
1c80317fa3b1799d
1c80317fa3b1799d
1c80317fa3b1799d
1c80317fa3b1799d
1c80317fa3b1799d
1c80317fa3b1799d
1c80317fa3b1799d
1c80317fa3b1799d
1c80317fa3b1799d
1c80317fa3b1799d
```
## Expected results
After the "random hash" warning is emitted, a random hash is generated, and no outdated cached datasets are reused.
## Actual results
After the "random hash" warning is emitted, an identical hash is generated each time, and an outdated cached dataset is reused each run.
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.9.0
- Platform: Linux-5.8.0-1038-gcp-x86_64-with-glibc2.31
- Python version: 3.9.6
- PyArrow version: 4.0.1 | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2775/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2775/timeline | null | completed | null | null | 21,595.612222 | 4,801 |
https://api.github.com/repos/huggingface/datasets/issues/2773 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2773/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2773/comments | https://api.github.com/repos/huggingface/datasets/issues/2773/events | https://github.com/huggingface/datasets/issues/2773 | 963,730,497 | MDU6SXNzdWU5NjM3MzA0OTc= | 2,773 | Remove dataset_infos.json | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
},
{
"color": "c5def5",
"default": fals... | closed | false | null | [] | null | [
"This was closed by:\r\n- #4926"
] | 2021-08-09T07:43:19Z | 2024-05-04T14:52:10Z | 2024-05-04T14:52:10Z | MEMBER | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | **Is your feature request related to a problem? Please describe.**
As discussed, there are infos in the `dataset_infos.json` which are redundant and we could have them only in the README file.
Others could be migrated to the README, like: "dataset_size", "size_in_bytes", "download_size", "splits.split_name.[num_bytes, num_examples]",...
However, there are others that do not seem too meaningful in the README, like the checksums.
**Describe the solution you'd like**
Open a discussion to decide what to do with the `dataset_infos.json` files: which information to be migrated and/or which information to be kept.
cc: @julien-c @lhoestq | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2773/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2773/timeline | null | completed | null | null | 23,983.1475 | 4,803 |
https://api.github.com/repos/huggingface/datasets/issues/2768 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2768/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2768/comments | https://api.github.com/repos/huggingface/datasets/issues/2768/events | https://github.com/huggingface/datasets/issues/2768 | 963,229,173 | MDU6SXNzdWU5NjMyMjkxNzM= | 2,768 | `ArrowInvalid: Added column's length must match table's length.` after using `select` | {
"avatar_url": "https://avatars.githubusercontent.com/u/8264887?v=4",
"events_url": "https://api.github.com/users/lvwerra/events{/privacy}",
"followers_url": "https://api.github.com/users/lvwerra/followers",
"following_url": "https://api.github.com/users/lvwerra/following{/other_user}",
"gists_url": "https://api.github.com/users/lvwerra/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lvwerra",
"id": 8264887,
"login": "lvwerra",
"node_id": "MDQ6VXNlcjgyNjQ4ODc=",
"organizations_url": "https://api.github.com/users/lvwerra/orgs",
"received_events_url": "https://api.github.com/users/lvwerra/received_events",
"repos_url": "https://api.github.com/users/lvwerra/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lvwerra/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lvwerra/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lvwerra",
"user_view_type": "public"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"Hi,\r\n\r\nthe `select` method creates an indices mapping and doesn't modify the underlying PyArrow table by default for better performance. To modify the underlying table after the `select` call, call `flatten_indices` on the dataset object as follows:\r\n```python\r\nfrom datasets import load_dataset\r\n\r\nds =... | 2021-08-07T13:17:29Z | 2021-08-09T11:26:43Z | 2021-08-09T11:26:43Z | MEMBER | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ## Describe the bug
I would like to add a column to a downsampled dataset. However I get an error message saying the length don't match with the length of the unsampled dataset indicated. I suspect that the dataset size is not updated when calling `select`.
## Steps to reproduce the bug
```python
from datasets import load_dataset
ds = load_dataset("tweets_hate_speech_detection")['train'].select(range(128))
ds = ds.add_column('ones', [1]*128)
```
## Expected results
I would expect a new column named `ones` filled with `1`. When I check the length of `ds` it says `128`. Interestingly, it works when calling `ds = ds.map(lambda x: x)` before adding the column.
## Actual results
Specify the actual results or traceback.
```python
---------------------------------------------------------------------------
ArrowInvalid Traceback (most recent call last)
/var/folders/l4/2905jygx4tx5jv8_kn03vxsw0000gn/T/ipykernel_6301/868709636.py in <module>
1 from datasets import load_dataset
2 ds = load_dataset("tweets_hate_speech_detection")['train'].select(range(128))
----> 3 ds = ds.add_column('ones', [0]*128)
~/git/semantic-clustering/env/lib/python3.8/site-packages/datasets/arrow_dataset.py in wrapper(*args, **kwargs)
183 }
184 # apply actual function
--> 185 out: Union["Dataset", "DatasetDict"] = func(self, *args, **kwargs)
186 datasets: List["Dataset"] = list(out.values()) if isinstance(out, dict) else [out]
187 # re-apply format to the output
~/git/semantic-clustering/env/lib/python3.8/site-packages/datasets/fingerprint.py in wrapper(*args, **kwargs)
395 # Call actual function
396
--> 397 out = func(self, *args, **kwargs)
398
399 # Update fingerprint of in-place transforms + update in-place history of transforms
~/git/semantic-clustering/env/lib/python3.8/site-packages/datasets/arrow_dataset.py in add_column(self, name, column, new_fingerprint)
2965 column_table = InMemoryTable.from_pydict({name: column})
2966 # Concatenate tables horizontally
-> 2967 table = ConcatenationTable.from_tables([self._data, column_table], axis=1)
2968 # Update features
2969 info = self.info.copy()
~/git/semantic-clustering/env/lib/python3.8/site-packages/datasets/table.py in from_tables(cls, tables, axis)
715 table_blocks = to_blocks(table)
716 blocks = _extend_blocks(blocks, table_blocks, axis=axis)
--> 717 return cls.from_blocks(blocks)
718
719 @property
~/git/semantic-clustering/env/lib/python3.8/site-packages/datasets/table.py in from_blocks(cls, blocks)
663 return cls(table, blocks)
664 else:
--> 665 table = cls._concat_blocks_horizontally_and_vertically(blocks)
666 return cls(table, blocks)
667
~/git/semantic-clustering/env/lib/python3.8/site-packages/datasets/table.py in _concat_blocks_horizontally_and_vertically(cls, blocks)
623 if not tables:
624 continue
--> 625 pa_table_horizontally_concatenated = cls._concat_blocks(tables, axis=1)
626 pa_tables_to_concat_vertically.append(pa_table_horizontally_concatenated)
627 return cls._concat_blocks(pa_tables_to_concat_vertically, axis=0)
~/git/semantic-clustering/env/lib/python3.8/site-packages/datasets/table.py in _concat_blocks(blocks, axis)
612 else:
613 for name, col in zip(table.column_names, table.columns):
--> 614 pa_table = pa_table.append_column(name, col)
615 return pa_table
616 else:
~/git/semantic-clustering/env/lib/python3.8/site-packages/pyarrow/table.pxi in pyarrow.lib.Table.append_column()
~/git/semantic-clustering/env/lib/python3.8/site-packages/pyarrow/table.pxi in pyarrow.lib.Table.add_column()
~/git/semantic-clustering/env/lib/python3.8/site-packages/pyarrow/error.pxi in pyarrow.lib.pyarrow_internal_check_status()
~/git/semantic-clustering/env/lib/python3.8/site-packages/pyarrow/error.pxi in pyarrow.lib.check_status()
ArrowInvalid: Added column's length must match table's length. Expected length 31962 but got length 128
```
## Environment info
- `datasets` version: 1.11.0
- Platform: macOS-10.16-x86_64-i386-64bit
- Python version: 3.8.5
- PyArrow version: 5.0.0
| {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2768/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2768/timeline | null | completed | null | null | 46.153889 | 4,808 |
https://api.github.com/repos/huggingface/datasets/issues/2767 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2767/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2767/comments | https://api.github.com/repos/huggingface/datasets/issues/2767/events | https://github.com/huggingface/datasets/issues/2767 | 963,002,120 | MDU6SXNzdWU5NjMwMDIxMjA= | 2,767 | equal operation to perform unbatch for huggingface datasets | {
"avatar_url": "https://avatars.githubusercontent.com/u/79288051?v=4",
"events_url": "https://api.github.com/users/dorooddorood606/events{/privacy}",
"followers_url": "https://api.github.com/users/dorooddorood606/followers",
"following_url": "https://api.github.com/users/dorooddorood606/following{/other_user}",
"gists_url": "https://api.github.com/users/dorooddorood606/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/dorooddorood606",
"id": 79288051,
"login": "dorooddorood606",
"node_id": "MDQ6VXNlcjc5Mjg4MDUx",
"organizations_url": "https://api.github.com/users/dorooddorood606/orgs",
"received_events_url": "https://api.github.com/users/dorooddorood606/received_events",
"repos_url": "https://api.github.com/users/dorooddorood606/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/dorooddorood606/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/dorooddorood606/subscriptions",
"type": "User",
"url": "https://api.github.com/users/dorooddorood606",
"user_view_type": "public"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"Hi @lhoestq \r\nMaybe this is clearer to explain like this, currently map function, map one example to \"one\" modified one, lets assume we want to map one example to \"multiple\" examples, in which we do not know in advance how many examples they would be per each entry. I greatly appreciate telling me how I can ... | 2021-08-06T19:45:52Z | 2022-03-07T13:58:00Z | 2022-03-07T13:58:00Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | Hi
I need to use "unbatch" operation in tensorflow on a huggingface dataset, I could not find this operation, could you kindly direct me how I can do it, here is the problem I am trying to solve:
I am considering "record" dataset in SuperGlue and I need to replicate each entery of the dataset for each answer, to make it similar to what T5 originally did:
https://github.com/google-research/text-to-text-transfer-transformer/blob/3c58859b8fe72c2dbca6a43bc775aa510ba7e706/t5/data/preprocessors.py#L925
Here please find an example:
For example, a typical example from ReCoRD might look like
{
'passsage': 'This is the passage.',
'query': 'A @placeholder is a bird.',
'entities': ['penguin', 'potato', 'pigeon'],
'answers': ['penguin', 'pigeon'],
}
and I need a prosessor which would turn this example into the following two examples:
{
'inputs': 'record query: A @placeholder is a bird. entities: penguin, '
'potato, pigeon passage: This is the passage.',
'targets': 'penguin',
}
and
{
'inputs': 'record query: A @placeholder is a bird. entities: penguin, '
'potato, pigeon passage: This is the passage.',
'targets': 'pigeon',
}
For doing this, one need unbatch, as each entry can map to multiple samples depending on the number of answers, I am not sure how to perform this operation with huggingface datasets library and greatly appreciate your help
@lhoestq
Thank you very much.
| {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2767/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2767/timeline | null | completed | null | null | 5,106.202222 | 4,809 |
https://api.github.com/repos/huggingface/datasets/issues/2765 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2765/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2765/comments | https://api.github.com/repos/huggingface/datasets/issues/2765/events | https://github.com/huggingface/datasets/issues/2765 | 962,861,395 | MDU6SXNzdWU5NjI4NjEzOTU= | 2,765 | BERTScore Error | {
"avatar_url": "https://avatars.githubusercontent.com/u/49101362?v=4",
"events_url": "https://api.github.com/users/gagan3012/events{/privacy}",
"followers_url": "https://api.github.com/users/gagan3012/followers",
"following_url": "https://api.github.com/users/gagan3012/following{/other_user}",
"gists_url": "https://api.github.com/users/gagan3012/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/gagan3012",
"id": 49101362,
"login": "gagan3012",
"node_id": "MDQ6VXNlcjQ5MTAxMzYy",
"organizations_url": "https://api.github.com/users/gagan3012/orgs",
"received_events_url": "https://api.github.com/users/gagan3012/received_events",
"repos_url": "https://api.github.com/users/gagan3012/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/gagan3012/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/gagan3012/subscriptions",
"type": "User",
"url": "https://api.github.com/users/gagan3012",
"user_view_type": "public"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"Hi,\r\n\r\nThe `use_fast_tokenizer` argument has been recently added to the bert-score lib. I've opened a PR with the fix. In the meantime, you can try to downgrade the version of bert-score with the following command to make the code work:\r\n```\r\npip uninstall bert-score\r\npip install \"bert-score<0.3.10\"\r\... | 2021-08-06T15:58:57Z | 2021-08-09T11:16:25Z | 2021-08-09T11:16:25Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ## Describe the bug
A clear and concise description of what the bug is.
## Steps to reproduce the bug
```python
predictions = ["hello there", "general kenobi"]
references = ["hello there", "general kenobi"]
bert = load_metric('bertscore')
bert.compute(predictions=predictions, references=references,lang='en')
```
# Bug
`TypeError: get_hash() missing 1 required positional argument: 'use_fast_tokenizer'`
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version:
- Platform: Colab
- Python version:
- PyArrow version:
| {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2765/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2765/timeline | null | completed | null | null | 67.291111 | 4,811 |
https://api.github.com/repos/huggingface/datasets/issues/2763 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2763/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2763/comments | https://api.github.com/repos/huggingface/datasets/issues/2763/events | https://github.com/huggingface/datasets/issues/2763 | 961,895,523 | MDU6SXNzdWU5NjE4OTU1MjM= | 2,763 | English wikipedia datasets is not clean | {
"avatar_url": "https://avatars.githubusercontent.com/u/23355969?v=4",
"events_url": "https://api.github.com/users/lucadiliello/events{/privacy}",
"followers_url": "https://api.github.com/users/lucadiliello/followers",
"following_url": "https://api.github.com/users/lucadiliello/following{/other_user}",
"gists_url": "https://api.github.com/users/lucadiliello/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lucadiliello",
"id": 23355969,
"login": "lucadiliello",
"node_id": "MDQ6VXNlcjIzMzU1OTY5",
"organizations_url": "https://api.github.com/users/lucadiliello/orgs",
"received_events_url": "https://api.github.com/users/lucadiliello/received_events",
"repos_url": "https://api.github.com/users/lucadiliello/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lucadiliello/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lucadiliello/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lucadiliello",
"user_view_type": "public"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"Hi ! Certain users might need these data (for training or simply to explore/index the dataset).\r\n\r\nFeel free to implement a map function that gets rid of these paragraphs and process the wikipedia dataset with it before training"
] | 2021-08-05T14:37:24Z | 2023-07-25T17:43:04Z | 2023-07-25T17:43:04Z | CONTRIBUTOR | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ## Describe the bug
Wikipedia english dumps contain many wikipedia paragraphs like "References", "Category:" and "See Also" that should not be used for training.
## Steps to reproduce the bug
```python
# Sample code to reproduce the bug
from datasets import load_dataset
w = load_dataset('wikipedia', '20200501.en')
print(w['train'][0]['text'])
```
> 'Yangliuqing () is a market town in Xiqing District, in the western suburbs of Tianjin, People\'s Republic of China. Despite its relatively small size, it has been named since 2006 in the "famous historical and cultural market towns in China".\n\nIt is best known in China for creating nianhua or Yangliuqing nianhua. For more than 400 years, Yangliuqing has in effect specialised in the creation of these woodcuts for the New Year. wood block prints using vivid colourschemes to portray traditional scenes of children\'s games often interwoven with auspiciouse objects.\n\n, it had 27 residential communities () and 25 villages under its administration.\n\nShi Family Grand Courtyard\n\nShi Family Grand Courtyard (Tiānjīn Shí Jiā Dà Yuàn, 天津石家大院) is situated in Yangliuqing Town of Xiqing District, which is the former residence of wealthy merchant Shi Yuanshi - the 4th son of Shi Wancheng, one of the eight great masters in Tianjin. First built in 1875, it covers over 6,000 square meters, including large and small yards and over 200 folk houses, a theater and over 275 rooms that served as apartments and places of business and worship for this powerful family. Shifu Garden, which finished its expansion in October 2003, covers 1,200 square meters, incorporates the elegance of imperial garden and delicacy of south garden. Now the courtyard of Shi family covers about 10,000 square meters, which is called the first mansion in North China. Now it serves as the folk custom museum in Yangliuqing, which has a large collection of folk custom museum in Yanliuqing, which has a large collection of folk art pieces like Yanliuqing New Year pictures, brick sculpture.\n\nShi\'s ancestor came from Dong\'e County in Shandong Province, engaged in water transport of grain. As the wealth gradually accumulated, the Shi Family moved to Yangliuqing and bought large tracts of land and set up their residence. Shi Yuanshi came from the fourth generation of the family, who was a successful businessman and a good household manager, and the residence was thus enlarged for several times until it acquired the present scale. It is believed to be the first mansion in the west of Tianjin.\n\nThe residence is symmetric based on the axis formed by a passageway in the middle, on which there are four archways. On the east side of the courtyard, there are traditional single-story houses with rows of rooms around the four sides, which was once the living area for the Shi Family. The rooms on north side were the accountants\' office. On the west are the major constructions including the family hall for worshipping Buddha, theater and the south reception room. On both sides of the residence are side yard rooms for maids and servants.\n\nToday, the Shi mansion, located in the township of Yangliuqing to the west of central Tianjin, stands as a surprisingly well-preserved monument to China\'s pre-revolution mercantile spirit. It also serves as an on-location shoot for many of China\'s popular historical dramas. Many of the rooms feature period furniture, paintings and calligraphy, and the extensive Shifu Garden.\n\nPart of the complex has been turned into the Yangliuqing Museum, which includes displays focused on symbolic aspects of the courtyards\' construction, local folk art and customs, and traditional period furnishings and crafts.\n\n**See also \n\nList of township-level divisions of Tianjin\n\nReferences \n\n http://arts.cultural-china.com/en/65Arts4795.html\n\nCategory:Towns in Tianjin'**
## Expected results
I expect no junk in the data.
## Actual results
Specify the actual results or traceback.
## Environment info
- `datasets` version: 1.10.2
- Platform: macOS-10.15.7-x86_64-i386-64bit
- Python version: 3.8.5
- PyArrow version: 3.0.0
| {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2763/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2763/timeline | null | completed | null | null | 17,259.094444 | 4,813 |
https://api.github.com/repos/huggingface/datasets/issues/2762 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2762/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2762/comments | https://api.github.com/repos/huggingface/datasets/issues/2762/events | https://github.com/huggingface/datasets/issues/2762 | 961,652,046 | MDU6SXNzdWU5NjE2NTIwNDY= | 2,762 | Add RVL-CDIP dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/48327001?v=4",
"events_url": "https://api.github.com/users/NielsRogge/events{/privacy}",
"followers_url": "https://api.github.com/users/NielsRogge/followers",
"following_url": "https://api.github.com/users/NielsRogge/following{/other_user}",
"gists_url": "https://api.github.com/users/NielsRogge/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/NielsRogge",
"id": 48327001,
"login": "NielsRogge",
"node_id": "MDQ6VXNlcjQ4MzI3MDAx",
"organizations_url": "https://api.github.com/users/NielsRogge/orgs",
"received_events_url": "https://api.github.com/users/NielsRogge/received_events",
"repos_url": "https://api.github.com/users/NielsRogge/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/NielsRogge/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/NielsRogge/subscriptions",
"type": "User",
"url": "https://api.github.com/users/NielsRogge",
"user_view_type": "public"
} | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
},
{
"color": "bfdadc",... | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/17746528?v=4",
"events_url": "https://api.github.com/users/dnaveenr/events{/privacy}",
"followers_url": "https://api.github.com/users/dnaveenr/followers",
"following_url": "https://api.github.com/users/dnaveenr/following{/other_user}",
"gists_url": "https://api.github.com/users/dnaveenr/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/dnaveenr",
"id": 17746528,
"login": "dnaveenr",
"node_id": "MDQ6VXNlcjE3NzQ2NTI4",
"organizations_url": "https://api.github.com/users/dnaveenr/orgs",
"received_events_url": "https://api.github.com/users/dnaveenr/received_events",
"repos_url": "https://api.github.com/users/dnaveenr/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/dnaveenr/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/dnaveenr/subscriptions",
"type": "User",
"url": "https://api.github.com/users/dnaveenr",
"user_view_type": "public"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/17746528?v=4",
"events_url": "https://api.github.com/users/dnaveenr/events{/privacy}",
"followers_url": "https://api.github.com/users/dnaveenr/followers",
"following_url": "https://api.github.com/users/dnaveenr/following{/other_user}",
"gi... | null | [
"cc @nateraw ",
"#self-assign",
"[labels_only.tar.gz](https://docs.google.com/uc?authuser=0&id=0B0NKIRwUL9KYcXo3bV9LU0t3SGs&export=download) on the RVL-CDIP website does not work for me.\r\n\r\n> 404. That’s an error. The requested URL was not found on this server.\r\n\r\nI contacted the author ( Adam Harley) r... | 2021-08-05T09:57:05Z | 2022-04-21T17:15:41Z | 2022-04-21T17:15:41Z | CONTRIBUTOR | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ## Adding a Dataset
- **Name:** RVL-CDIP
- **Description:** The RVL-CDIP (Ryerson Vision Lab Complex Document Information Processing) dataset consists of 400,000 grayscale images in 16 classes, with 25,000 images per class. There are 320,000 training images, 40,000 validation images, and 40,000 test images. The images are sized so their largest dimension does not exceed 1000 pixels.
- **Paper:** https://www.cs.cmu.edu/~aharley/icdar15/
- **Data:** https://www.cs.cmu.edu/~aharley/rvl-cdip/
- **Motivation:** I'm currently adding LayoutLMv2 and LayoutXLM to HuggingFace Transformers. LayoutLM (v1) already exists in the library. This dataset has a large value for document image classification (i.e. classifying scanned documents). LayoutLM models obtain SOTA on this dataset, so would be great to directly use it in notebooks.
Instructions to add a new dataset can be found [here](https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md).
| {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2762/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2762/timeline | null | completed | null | null | 6,223.31 | 4,814 |
https://api.github.com/repos/huggingface/datasets/issues/2761 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2761/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2761/comments | https://api.github.com/repos/huggingface/datasets/issues/2761/events | https://github.com/huggingface/datasets/issues/2761 | 961,568,287 | MDU6SXNzdWU5NjE1NjgyODc= | 2,761 | Error loading C4 realnewslike dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/32061512?v=4",
"events_url": "https://api.github.com/users/danshirron/events{/privacy}",
"followers_url": "https://api.github.com/users/danshirron/followers",
"following_url": "https://api.github.com/users/danshirron/following{/other_user}",
"gists_url": "https://api.github.com/users/danshirron/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/danshirron",
"id": 32061512,
"login": "danshirron",
"node_id": "MDQ6VXNlcjMyMDYxNTEy",
"organizations_url": "https://api.github.com/users/danshirron/orgs",
"received_events_url": "https://api.github.com/users/danshirron/received_events",
"repos_url": "https://api.github.com/users/danshirron/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/danshirron/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/danshirron/subscriptions",
"type": "User",
"url": "https://api.github.com/users/danshirron",
"user_view_type": "public"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"Hi @danshirron, \r\n`c4` was updated few days back by @lhoestq. The new configs are `['en', 'en.noclean', 'en.realnewslike', 'en.webtextlike'].` You'll need to remove any older version of this dataset you previously downloaded and then run `load_dataset` again with new configuration.",
"@bhavitvyamalik @lhoestq ... | 2021-08-05T08:16:58Z | 2021-08-08T19:44:34Z | 2021-08-08T19:44:34Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ## Describe the bug
Error loading C4 realnewslike dataset. Validation part mismatch
## Steps to reproduce the bug
```python
raw_datasets = load_dataset('c4', 'realnewslike', cache_dir=model_args.cache_dir)
## Expected results
success on data loading
## Actual results
Downloading: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 15.3M/15.3M [00:00<00:00, 28.1MB/s]Traceback (most recent call last):
File "run_mlm_tf.py", line 794, in <module>
main()
File "run_mlm_tf.py", line 425, in main
raw_datasets = load_dataset(data_args.dataset_name, data_args.dataset_config_name, cache_dir=model_args.cache_dir) File "/home/dshirron/.local/lib/python3.8/site-packages/datasets/load.py", line 843, in load_dataset
builder_instance.download_and_prepare(
File "/home/dshirron/.local/lib/python3.8/site-packages/datasets/builder.py", line 608, in download_and_prepare
self._download_and_prepare(
File "/home/dshirron/.local/lib/python3.8/site-packages/datasets/builder.py", line 698, in _download_and_prepare verify_splits(self.info.splits, split_dict) File "/home/dshirron/.local/lib/python3.8/site-packages/datasets/utils/info_utils.py", line 74, in verify_splits
raise NonMatchingSplitsSizesError(str(bad_splits))
datasets.utils.info_utils.NonMatchingSplitsSizesError: [{'expected': SplitInfo(name='validation', num_bytes=38165657946, num_examples=13799838, dataset_name='c4'), 'recorded': SplitInfo(name='validation', num_bytes=37875873, num_examples=13863, dataset_name='c4')}]
## Environment info
- `datasets` version: 1.10.2
- Platform: Linux-5.4.0-58-generic-x86_64-with-glibc2.29
- Python version: 3.8.10
- PyArrow version: 4.0.1 | {
"avatar_url": "https://avatars.githubusercontent.com/u/32061512?v=4",
"events_url": "https://api.github.com/users/danshirron/events{/privacy}",
"followers_url": "https://api.github.com/users/danshirron/followers",
"following_url": "https://api.github.com/users/danshirron/following{/other_user}",
"gists_url": "https://api.github.com/users/danshirron/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/danshirron",
"id": 32061512,
"login": "danshirron",
"node_id": "MDQ6VXNlcjMyMDYxNTEy",
"organizations_url": "https://api.github.com/users/danshirron/orgs",
"received_events_url": "https://api.github.com/users/danshirron/received_events",
"repos_url": "https://api.github.com/users/danshirron/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/danshirron/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/danshirron/subscriptions",
"type": "User",
"url": "https://api.github.com/users/danshirron",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2761/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2761/timeline | null | completed | null | null | 83.46 | 4,815 |
https://api.github.com/repos/huggingface/datasets/issues/2757 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2757/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2757/comments | https://api.github.com/repos/huggingface/datasets/issues/2757/events | https://github.com/huggingface/datasets/issues/2757 | 959,984,081 | MDU6SXNzdWU5NTk5ODQwODE= | 2,757 | Unexpected type after `concatenate_datasets` | {
"avatar_url": "https://avatars.githubusercontent.com/u/32683010?v=4",
"events_url": "https://api.github.com/users/JulesBelveze/events{/privacy}",
"followers_url": "https://api.github.com/users/JulesBelveze/followers",
"following_url": "https://api.github.com/users/JulesBelveze/following{/other_user}",
"gists_url": "https://api.github.com/users/JulesBelveze/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/JulesBelveze",
"id": 32683010,
"login": "JulesBelveze",
"node_id": "MDQ6VXNlcjMyNjgzMDEw",
"organizations_url": "https://api.github.com/users/JulesBelveze/orgs",
"received_events_url": "https://api.github.com/users/JulesBelveze/received_events",
"repos_url": "https://api.github.com/users/JulesBelveze/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/JulesBelveze/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/JulesBelveze/subscriptions",
"type": "User",
"url": "https://api.github.com/users/JulesBelveze",
"user_view_type": "public"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [
"Hi @JulesBelveze, thanks for your question.\r\n\r\nNote that 🤗 `datasets` internally store their data in Apache Arrow format.\r\n\r\nHowever, when accessing dataset columns, by default they are returned as native Python objects (lists in this case).\r\n\r\nIf you would like their columns to be returned in a more... | 2021-08-04T07:10:39Z | 2021-08-04T16:01:24Z | 2021-08-04T16:01:23Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ## Describe the bug
I am trying to concatenate two `Dataset` using `concatenate_datasets` but it turns out that after concatenation the features are casted from `torch.Tensor` to `list`.
It then leads to a weird tensors when trying to convert it to a `DataLoader`. However, if I use each `Dataset` separately everything behave as expected.
## Steps to reproduce the bug
```python
>>> featurized_teacher
Dataset({
features: ['t_labels', 't_input_ids', 't_token_type_ids', 't_attention_mask'],
num_rows: 502
})
>>> for f in featurized_teacher.features:
print(featurized_teacher[f].shape)
torch.Size([502])
torch.Size([502, 300])
torch.Size([502, 300])
torch.Size([502, 300])
>>> featurized_student
Dataset({
features: ['s_features', 's_labels'],
num_rows: 502
})
>>> for f in featurized_student.features:
print(featurized_student[f].shape)
torch.Size([502, 64])
torch.Size([502])
```
The shapes seem alright to me. Then the results after concatenation are as follow:
```python
>>> concat_dataset = datasets.concatenate_datasets([featurized_student, featurized_teacher], axis=1)
>>> type(concat_dataset["t_labels"])
<class 'list'>
```
One would expect to obtain the same type as the one before concatenation.
Am I doing something wrong here? Any idea on how to fix this unexpected behavior?
## Environment info
- `datasets` version: 1.9.0
- Platform: macOS-10.14.6-x86_64-i386-64bit
- Python version: 3.9.5
- PyArrow version: 3.0.0
| {
"avatar_url": "https://avatars.githubusercontent.com/u/32683010?v=4",
"events_url": "https://api.github.com/users/JulesBelveze/events{/privacy}",
"followers_url": "https://api.github.com/users/JulesBelveze/followers",
"following_url": "https://api.github.com/users/JulesBelveze/following{/other_user}",
"gists_url": "https://api.github.com/users/JulesBelveze/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/JulesBelveze",
"id": 32683010,
"login": "JulesBelveze",
"node_id": "MDQ6VXNlcjMyNjgzMDEw",
"organizations_url": "https://api.github.com/users/JulesBelveze/orgs",
"received_events_url": "https://api.github.com/users/JulesBelveze/received_events",
"repos_url": "https://api.github.com/users/JulesBelveze/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/JulesBelveze/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/JulesBelveze/subscriptions",
"type": "User",
"url": "https://api.github.com/users/JulesBelveze",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2757/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2757/timeline | null | completed | null | null | 8.845556 | 4,818 |
https://api.github.com/repos/huggingface/datasets/issues/2750 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2750/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2750/comments | https://api.github.com/repos/huggingface/datasets/issues/2750/events | https://github.com/huggingface/datasets/issues/2750 | 958,984,730 | MDU6SXNzdWU5NTg5ODQ3MzA= | 2,750 | Second concatenation of datasets produces errors | {
"avatar_url": "https://avatars.githubusercontent.com/u/36672861?v=4",
"events_url": "https://api.github.com/users/Aktsvigun/events{/privacy}",
"followers_url": "https://api.github.com/users/Aktsvigun/followers",
"following_url": "https://api.github.com/users/Aktsvigun/following{/other_user}",
"gists_url": "https://api.github.com/users/Aktsvigun/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Aktsvigun",
"id": 36672861,
"login": "Aktsvigun",
"node_id": "MDQ6VXNlcjM2NjcyODYx",
"organizations_url": "https://api.github.com/users/Aktsvigun/orgs",
"received_events_url": "https://api.github.com/users/Aktsvigun/received_events",
"repos_url": "https://api.github.com/users/Aktsvigun/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Aktsvigun/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Aktsvigun/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Aktsvigun",
"user_view_type": "public"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [
"@albertvillanova ",
"Hi @Aktsvigun, thanks for reporting.\r\n\r\nI'm investigating this.",
"Hi @albertvillanova ,\r\nany update on this? Can I probably help in some way?",
"Hi @Aktsvigun! We are planning to address this issue before our next release, in a couple of weeks at most. 😅 \r\n\r\nIn the meantime, ... | 2021-08-03T10:47:04Z | 2022-01-19T14:23:43Z | 2022-01-19T14:19:05Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | Hi,
I am need to concatenate my dataset with others several times, and after I concatenate it for the second time, the features of features (e.g. tags names) are collapsed. This hinders, for instance, the usage of tokenize function with `data.map`.
```
from datasets import load_dataset, concatenate_datasets
data = load_dataset('trec')['train']
concatenated = concatenate_datasets([data, data])
concatenated_2 = concatenate_datasets([concatenated, concatenated])
print('True features of features:', concatenated.features)
print('\nProduced features of features:', concatenated_2.features)
```
outputs
```
True features of features: {'label-coarse': ClassLabel(num_classes=6, names=['DESC', 'ENTY', 'ABBR', 'HUM', 'NUM', 'LOC'], names_file=None, id=None), 'label-fine': ClassLabel(num_classes=47, names=['manner', 'cremat', 'animal', 'exp', 'ind', 'gr', 'title', 'def', 'date', 'reason', 'event', 'state', 'desc', 'count', 'other', 'letter', 'religion', 'food', 'country', 'color', 'termeq', 'city', 'body', 'dismed', 'mount', 'money', 'product', 'period', 'substance', 'sport', 'plant', 'techmeth', 'volsize', 'instru', 'abb', 'speed', 'word', 'lang', 'perc', 'code', 'dist', 'temp', 'symbol', 'ord', 'veh', 'weight', 'currency'], names_file=None, id=None), 'text': Value(dtype='string', id=None)}
Produced features of features: {'label-coarse': Value(dtype='int64', id=None), 'label-fine': Value(dtype='int64', id=None), 'text': Value(dtype='string', id=None)}
```
I am using `datasets` v.1.11.0 | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2750/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2750/timeline | null | completed | null | null | 4,059.533611 | 4,825 |
https://api.github.com/repos/huggingface/datasets/issues/2749 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2749/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2749/comments | https://api.github.com/repos/huggingface/datasets/issues/2749/events | https://github.com/huggingface/datasets/issues/2749 | 958,968,748 | MDU6SXNzdWU5NTg5Njg3NDg= | 2,749 | Raise a proper exception when trying to stream a dataset that requires to manually download files | {
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://api.github.com/users/severo/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/severo",
"id": 1676121,
"login": "severo",
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"organizations_url": "https://api.github.com/users/severo/orgs",
"received_events_url": "https://api.github.com/users/severo/received_events",
"repos_url": "https://api.github.com/users/severo/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/severo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/severo/subscriptions",
"type": "User",
"url": "https://api.github.com/users/severo",
"user_view_type": "public"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [
"Hi @severo, thanks for reporting.\r\n\r\nAs discussed, datasets requiring manual download should be:\r\n- programmatically identifiable\r\n- properly handled with more clear error message when trying to load them with streaming\r\n\r\nIn relation with programmatically identifiability, note that for datasets requir... | 2021-08-03T10:26:27Z | 2021-08-09T08:53:35Z | 2021-08-04T11:36:30Z | COLLABORATOR | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ## Describe the bug
At least for 'reclor', 'telugu_books', 'turkish_movie_sentiment', 'ubuntu_dialogs_corpus', 'wikihow', trying to `load_dataset` in streaming mode raises a `TypeError` without any detail about why it fails.
## Steps to reproduce the bug
```python
from datasets import load_dataset
dataset = load_dataset("reclor", streaming=True)
```
## Expected results
Ideally: raise a specific exception, something like `ManualDownloadError`.
Or at least give the reason in the message, as when we load in normal mode:
```python
from datasets import load_dataset
dataset = load_dataset("reclor")
```
```
AssertionError: The dataset reclor with config default requires manual data.
Please follow the manual download instructions: to use ReClor you need to download it manually. Please go to its homepage (http://whyu.me/reclor/) fill the google
form and you will receive a download link and a password to extract it.Please extract all files in one folder and use the path folder in datasets.load_dataset('reclor', data_dir='path/to/folder/folder_name')
.
Manual data can be loaded with `datasets.load_dataset(reclor, data_dir='<path/to/manual/data>')
```
## Actual results
```
TypeError: expected str, bytes or os.PathLike object, not NoneType
```
## Environment info
- `datasets` version: 1.11.0
- Platform: macOS-11.5-x86_64-i386-64bit
- Python version: 3.8.11
- PyArrow version: 4.0.1
| {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2749/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2749/timeline | null | completed | null | null | 25.1675 | 4,826 |
https://api.github.com/repos/huggingface/datasets/issues/2746 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2746/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2746/comments | https://api.github.com/repos/huggingface/datasets/issues/2746/events | https://github.com/huggingface/datasets/issues/2746 | 958,551,619 | MDU6SXNzdWU5NTg1NTE2MTk= | 2,746 | Cannot load `few-nerd` dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/28717374?v=4",
"events_url": "https://api.github.com/users/Mehrad0711/events{/privacy}",
"followers_url": "https://api.github.com/users/Mehrad0711/followers",
"following_url": "https://api.github.com/users/Mehrad0711/following{/other_user}",
"gists_url": "https://api.github.com/users/Mehrad0711/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Mehrad0711",
"id": 28717374,
"login": "Mehrad0711",
"node_id": "MDQ6VXNlcjI4NzE3Mzc0",
"organizations_url": "https://api.github.com/users/Mehrad0711/orgs",
"received_events_url": "https://api.github.com/users/Mehrad0711/received_events",
"repos_url": "https://api.github.com/users/Mehrad0711/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Mehrad0711/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Mehrad0711/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Mehrad0711",
"user_view_type": "public"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"Hi @Mehrad0711,\r\n\r\nI'm afraid there is no \"canonical\" Hugging Face dataset named \"few-nerd\".\r\n\r\nThere are 2 kinds of datasets hosted at the Hugging Face Hub:\r\n- canonical datasets (their identifier contains no slash \"/\"): we, the Hugging Face team, supervise their implementation and we make sure th... | 2021-08-02T22:18:57Z | 2021-11-16T08:51:34Z | 2021-08-03T19:45:43Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ## Describe the bug
Cannot load `few-nerd` dataset.
## Steps to reproduce the bug
```python
from datasets import load_dataset
load_dataset('few-nerd', 'supervised')
```
## Actual results
Executing above code will give the following error:
```
Using the latest cached version of the module from /Users/Mehrad/.cache/huggingface/modules/datasets_modules/datasets/few-nerd/62464ace912a40a0f33a11a8310f9041c9dc3590ff2b3c77c14d83ca53cfec53 (last modified on Wed Jun 2 11:34:25 2021) since it couldn't be found locally at /Users/Mehrad/Documents/GitHub/genienlp/few-nerd/few-nerd.py, or remotely (FileNotFoundError).
Downloading and preparing dataset few_nerd/supervised (download: Unknown size, generated: Unknown size, post-processed: Unknown size, total: Unknown size) to /Users/Mehrad/.cache/huggingface/datasets/few_nerd/supervised/0.0.0/62464ace912a40a0f33a11a8310f9041c9dc3590ff2b3c77c14d83ca53cfec53...
Traceback (most recent call last):
File "/Users/Mehrad/opt/anaconda3/lib/python3.7/site-packages/datasets/builder.py", line 693, in _download_and_prepare
self._prepare_split(split_generator, **prepare_split_kwargs)
File "/Users/Mehrad/opt/anaconda3/lib/python3.7/site-packages/datasets/builder.py", line 1107, in _prepare_split
disable=bool(logging.get_verbosity() == logging.NOTSET),
File "/Users/Mehrad/opt/anaconda3/lib/python3.7/site-packages/tqdm/std.py", line 1133, in __iter__
for obj in iterable:
File "/Users/Mehrad/.cache/huggingface/modules/datasets_modules/datasets/few-nerd/62464ace912a40a0f33a11a8310f9041c9dc3590ff2b3c77c14d83ca53cfec53/few-nerd.py", line 196, in _generate_examples
with open(filepath, encoding="utf-8") as f:
FileNotFoundError: [Errno 2] No such file or directory: '/Users/Mehrad/.cache/huggingface/datasets/downloads/supervised/train.json'
```
The bug is probably in identifying and downloading the dataset. If I download the json splits directly from [link](https://github.com/nbroad1881/few-nerd/tree/main/uncompressed) and put them under the downloads directory, they will be processed into arrow format correctly.
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.11.0
- Python version: 3.8
- PyArrow version: 1.0.1
| {
"avatar_url": "https://avatars.githubusercontent.com/u/28717374?v=4",
"events_url": "https://api.github.com/users/Mehrad0711/events{/privacy}",
"followers_url": "https://api.github.com/users/Mehrad0711/followers",
"following_url": "https://api.github.com/users/Mehrad0711/following{/other_user}",
"gists_url": "https://api.github.com/users/Mehrad0711/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Mehrad0711",
"id": 28717374,
"login": "Mehrad0711",
"node_id": "MDQ6VXNlcjI4NzE3Mzc0",
"organizations_url": "https://api.github.com/users/Mehrad0711/orgs",
"received_events_url": "https://api.github.com/users/Mehrad0711/received_events",
"repos_url": "https://api.github.com/users/Mehrad0711/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Mehrad0711/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Mehrad0711/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Mehrad0711",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2746/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2746/timeline | null | completed | null | null | 21.446111 | 4,829 |
https://api.github.com/repos/huggingface/datasets/issues/2743 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2743/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2743/comments | https://api.github.com/repos/huggingface/datasets/issues/2743/events | https://github.com/huggingface/datasets/issues/2743 | 958,119,251 | MDU6SXNzdWU5NTgxMTkyNTE= | 2,743 | Dataset JSON is incorrect | {
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://api.github.com/users/severo/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/severo",
"id": 1676121,
"login": "severo",
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"organizations_url": "https://api.github.com/users/severo/orgs",
"received_events_url": "https://api.github.com/users/severo/received_events",
"repos_url": "https://api.github.com/users/severo/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/severo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/severo/subscriptions",
"type": "User",
"url": "https://api.github.com/users/severo",
"user_view_type": "public"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [
"As discussed, the metadata JSON files must be regenerated because the keys were nor properly generated and they will not be read by the builder:\r\n> Indeed there is some problem/bug while reading the datasets_info.json file: there is a mismatch with the config.name keys in the file...\r\nIn the meanwhile, in orde... | 2021-08-02T13:01:26Z | 2021-08-03T10:06:57Z | 2021-08-03T09:25:33Z | COLLABORATOR | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ## Describe the bug
The JSON file generated for https://github.com/huggingface/datasets/blob/573f3d35081cee239d1b962878206e9abe6cde91/datasets/journalists_questions/journalists_questions.py is https://github.com/huggingface/datasets/blob/573f3d35081cee239d1b962878206e9abe6cde91/datasets/journalists_questions/dataset_infos.json.
The only config should be `plain_text`, but the first key in the JSON is `journalists_questions` (the dataset id) instead.
```json
{
"journalists_questions": {
"description": "The journalists_questions corpus (version 1.0) is a collection of 10K human-written Arabic\ntweets manually labeled for question identification over Arabic tweets posted by journalists.\n",
...
```
## Steps to reproduce the bug
Look at the files.
## Expected results
The first key should be `plain_text`:
```json
{
"plain_text": {
"description": "The journalists_questions corpus (version 1.0) is a collection of 10K human-written Arabic\ntweets manually labeled for question identification over Arabic tweets posted by journalists.\n",
...
```
## Actual results
```json
{
"journalists_questions": {
"description": "The journalists_questions corpus (version 1.0) is a collection of 10K human-written Arabic\ntweets manually labeled for question identification over Arabic tweets posted by journalists.\n",
...
```
| {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2743/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2743/timeline | null | completed | null | null | 20.401944 | 4,832 |
https://api.github.com/repos/huggingface/datasets/issues/2742 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2742/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2742/comments | https://api.github.com/repos/huggingface/datasets/issues/2742/events | https://github.com/huggingface/datasets/issues/2742 | 958,114,064 | MDU6SXNzdWU5NTgxMTQwNjQ= | 2,742 | Improve detection of streamable file types | {
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://api.github.com/users/severo/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/severo",
"id": 1676121,
"login": "severo",
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"organizations_url": "https://api.github.com/users/severo/orgs",
"received_events_url": "https://api.github.com/users/severo/received_events",
"repos_url": "https://api.github.com/users/severo/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/severo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/severo/subscriptions",
"type": "User",
"url": "https://api.github.com/users/severo",
"user_view_type": "public"
} | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
},
{
"color": "E5583E",
"default": fals... | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists... | null | [
"maybe we should rather attempt to download a `Range` from the server and see if it works?"
] | 2021-08-02T12:55:09Z | 2021-11-12T17:18:10Z | 2021-11-12T17:18:10Z | COLLABORATOR | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | **Is your feature request related to a problem? Please describe.**
```python
from datasets import load_dataset_builder
from datasets.utils.streaming_download_manager import StreamingDownloadManager
builder = load_dataset_builder("journalists_questions", name="plain_text")
builder._split_generators(StreamingDownloadManager(base_path=builder.base_path))
```
raises
```
NotImplementedError: Extraction protocol for file at https://drive.google.com/uc?export=download&id=1CBrh-9OrSpKmPQBxTK_ji6mq6WTN_U9U is not implemented yet
```
But the file at https://drive.google.com/uc?export=download&id=1CBrh-9OrSpKmPQBxTK_ji6mq6WTN_U9U is a text file and it can be streamed:
```bash
curl --header "Range: bytes=0-100" -L https://drive.google.com/uc\?export\=download\&id\=1CBrh-9OrSpKmPQBxTK_ji6mq6WTN_U9U
506938088174940160 yes 1
302221719412830209 yes 1
289761704907268096 yes 1
513820885032378369 yes %
```
Yet, it's wrongly categorized as a file type that cannot be streamed because the test is currently based on 1. the presence of a file extension at the end of the URL (here: no extension), and 2. the inclusion of this extension in a list of supported formats.
**Describe the solution you'd like**
In the case of an URL (instead of a local path), ask for the MIME type, and decide on that value? Note that it would not work in that case, because the value of `content_type` is `text/html; charset=UTF-8`.
**Describe alternatives you've considered**
Add a variable in the dataset script to set the data format by hand.
| {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2742/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2742/timeline | null | completed | null | null | 2,452.383611 | 4,833 |
https://api.github.com/repos/huggingface/datasets/issues/2737 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2737/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2737/comments | https://api.github.com/repos/huggingface/datasets/issues/2737/events | https://github.com/huggingface/datasets/issues/2737 | 957,124,881 | MDU6SXNzdWU5NTcxMjQ4ODE= | 2,737 | SacreBLEU update | {
"avatar_url": "https://avatars.githubusercontent.com/u/46989091?v=4",
"events_url": "https://api.github.com/users/devrimcavusoglu/events{/privacy}",
"followers_url": "https://api.github.com/users/devrimcavusoglu/followers",
"following_url": "https://api.github.com/users/devrimcavusoglu/following{/other_user}",
"gists_url": "https://api.github.com/users/devrimcavusoglu/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/devrimcavusoglu",
"id": 46989091,
"login": "devrimcavusoglu",
"node_id": "MDQ6VXNlcjQ2OTg5MDkx",
"organizations_url": "https://api.github.com/users/devrimcavusoglu/orgs",
"received_events_url": "https://api.github.com/users/devrimcavusoglu/received_events",
"repos_url": "https://api.github.com/users/devrimcavusoglu/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/devrimcavusoglu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/devrimcavusoglu/subscriptions",
"type": "User",
"url": "https://api.github.com/users/devrimcavusoglu",
"user_view_type": "public"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"Hi @devrimcavusoglu, \r\nI tried your code with latest version of `datasets`and `sacrebleu==1.5.1` and it's running fine after changing one small thing:\r\n```\r\nsacrebleu = datasets.load_metric('sacrebleu')\r\npredictions = [\"It is a guide to action which ensures that the military always obeys the commands of t... | 2021-07-30T23:53:08Z | 2021-09-22T10:47:41Z | 2021-08-03T04:23:37Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | With the latest release of [sacrebleu](https://github.com/mjpost/sacrebleu), `datasets.metrics.sacrebleu` is broken, and getting error.
AttributeError: module 'sacrebleu' has no attribute 'DEFAULT_TOKENIZER'
this happens since in new version of sacrebleu there is no `DEFAULT_TOKENIZER`, but sacrebleu.py tries to import it anyways. This can be fixed currently with fixing `sacrebleu==1.5.0`
## Steps to reproduce the bug
```python
sacrebleu= datasets.load_metric('sacrebleu')
predictions = ["It is a guide to action which ensures that the military always obeys the commands of the party"]
references = ["It is a guide to action that ensures that the military will forever heed Party commands"]
results = sacrebleu.compute(predictions=predictions, references=references)
print(results)
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.11.0
- Platform: Windows-10-10.0.19041-SP0
- Python version: Python 3.8.0
- PyArrow version: 5.0.0
| {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2737/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2737/timeline | null | completed | null | null | 76.508056 | 4,838 |
https://api.github.com/repos/huggingface/datasets/issues/2727 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2727/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2727/comments | https://api.github.com/repos/huggingface/datasets/issues/2727/events | https://github.com/huggingface/datasets/issues/2727 | 955,812,149 | MDU6SXNzdWU5NTU4MTIxNDk= | 2,727 | Error in loading the Arabic Billion Words Corpus | {
"avatar_url": "https://avatars.githubusercontent.com/u/9285264?v=4",
"events_url": "https://api.github.com/users/M-Salti/events{/privacy}",
"followers_url": "https://api.github.com/users/M-Salti/followers",
"following_url": "https://api.github.com/users/M-Salti/following{/other_user}",
"gists_url": "https://api.github.com/users/M-Salti/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/M-Salti",
"id": 9285264,
"login": "M-Salti",
"node_id": "MDQ6VXNlcjkyODUyNjQ=",
"organizations_url": "https://api.github.com/users/M-Salti/orgs",
"received_events_url": "https://api.github.com/users/M-Salti/received_events",
"repos_url": "https://api.github.com/users/M-Salti/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/M-Salti/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/M-Salti/subscriptions",
"type": "User",
"url": "https://api.github.com/users/M-Salti",
"user_view_type": "public"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [
"I modified the dataset loading script to catch the `IndexError` and inspect the records at which the error is happening, and I found this:\r\nFor the `Techreen` config, the error happens in 36 records when trying to find the `Text` or `Dateline` tags. All these 36 records look something like:\r\n```\r\n<Techreen>\... | 2021-07-29T12:53:09Z | 2021-07-30T13:03:55Z | 2021-07-30T13:03:55Z | CONTRIBUTOR | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ## Describe the bug
I get `IndexError: list index out of range` when trying to load the `Techreen` and `Almustaqbal` configs of the dataset.
## Steps to reproduce the bug
```python
load_dataset("arabic_billion_words", "Techreen")
load_dataset("arabic_billion_words", "Almustaqbal")
```
## Expected results
The datasets load succefully.
## Actual results
```python
_extract_tags(self, sample, tag)
139 if len(out) > 0:
140 break
--> 141 return out[0]
142
143 def _clean_text(self, text):
IndexError: list index out of range
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.10.2
- Platform: Ubuntu 18.04.5 LTS
- Python version: 3.7.11
- PyArrow version: 3.0.0
| {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2727/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2727/timeline | null | completed | null | null | 24.179444 | 4,848 |
https://api.github.com/repos/huggingface/datasets/issues/2724 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2724/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2724/comments | https://api.github.com/repos/huggingface/datasets/issues/2724/events | https://github.com/huggingface/datasets/issues/2724 | 954,919,607 | MDU6SXNzdWU5NTQ5MTk2MDc= | 2,724 | 404 Error when loading remote data files from private repo | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [
"I guess the issue is when computing the ETags of the remote files. Indeed `use_auth_token` must be passed to `request_etags` here:\r\n\r\nhttps://github.com/huggingface/datasets/blob/35b5e4bc0cb2ed896e40f3eb2a4aa3de1cb1a6c5/src/datasets/builder.py#L160-L160",
"Yes, I remember having properly implemented that: \r... | 2021-07-28T14:24:23Z | 2021-07-29T04:58:49Z | 2021-07-28T16:38:01Z | MEMBER | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ## Describe the bug
When loading remote data files from a private repo, a 404 error is raised.
## Steps to reproduce the bug
```python
url = hf_hub_url("lewtun/asr-preds-test", "preds.jsonl", repo_type="dataset")
dset = load_dataset("json", data_files=url, use_auth_token=True)
# HTTPError: 404 Client Error: Not Found for url: https://huggingface.co/datasets/lewtun/asr-preds-test/resolve/main/preds.jsonl
```
## Expected results
Load dataset.
## Actual results
404 Error.
| {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2724/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2724/timeline | null | completed | null | null | 2.227222 | 4,851 |
https://api.github.com/repos/huggingface/datasets/issues/2722 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2722/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2722/comments | https://api.github.com/repos/huggingface/datasets/issues/2722/events | https://github.com/huggingface/datasets/issues/2722 | 954,446,053 | MDU6SXNzdWU5NTQ0NDYwNTM= | 2,722 | Missing cache file | {
"avatar_url": "https://avatars.githubusercontent.com/u/33200481?v=4",
"events_url": "https://api.github.com/users/PosoSAgapo/events{/privacy}",
"followers_url": "https://api.github.com/users/PosoSAgapo/followers",
"following_url": "https://api.github.com/users/PosoSAgapo/following{/other_user}",
"gists_url": "https://api.github.com/users/PosoSAgapo/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/PosoSAgapo",
"id": 33200481,
"login": "PosoSAgapo",
"node_id": "MDQ6VXNlcjMzMjAwNDgx",
"organizations_url": "https://api.github.com/users/PosoSAgapo/orgs",
"received_events_url": "https://api.github.com/users/PosoSAgapo/received_events",
"repos_url": "https://api.github.com/users/PosoSAgapo/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/PosoSAgapo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/PosoSAgapo/subscriptions",
"type": "User",
"url": "https://api.github.com/users/PosoSAgapo",
"user_view_type": "public"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"This could be solved by going to the glue/ directory and delete sst2 directory, then load the dataset again will help you redownload the dataset.",
"Hi ! Not sure why this file was missing, but yes the way to fix this is to delete the sst2 directory and to reload the dataset"
] | 2021-07-28T03:52:07Z | 2022-03-21T08:27:51Z | 2022-03-21T08:27:51Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | Strangely missing cache file after I restart my program again.
`glue_dataset = datasets.load_dataset('glue', 'sst2')`
`FileNotFoundError: [Errno 2] No such file or directory: /Users/chris/.cache/huggingface/datasets/glue/sst2/1.0.0/dacbe3125aa31d7f70367a07a8a9e72a5a0bfeb5fc42e75c9db75b96d6053ad/dataset_info.json'`
| {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2722/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2722/timeline | null | completed | null | null | 5,668.595556 | 4,853 |
https://api.github.com/repos/huggingface/datasets/issues/2716 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2716/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2716/comments | https://api.github.com/repos/huggingface/datasets/issues/2716/events | https://github.com/huggingface/datasets/issues/2716 | 952,902,778 | MDU6SXNzdWU5NTI5MDI3Nzg= | 2,716 | Calling shuffle on IterableDataset will disable batching in case any functions were mapped | {
"avatar_url": "https://avatars.githubusercontent.com/u/7098967?v=4",
"events_url": "https://api.github.com/users/amankhandelia/events{/privacy}",
"followers_url": "https://api.github.com/users/amankhandelia/followers",
"following_url": "https://api.github.com/users/amankhandelia/following{/other_user}",
"gists_url": "https://api.github.com/users/amankhandelia/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/amankhandelia",
"id": 7098967,
"login": "amankhandelia",
"node_id": "MDQ6VXNlcjcwOTg5Njc=",
"organizations_url": "https://api.github.com/users/amankhandelia/orgs",
"received_events_url": "https://api.github.com/users/amankhandelia/received_events",
"repos_url": "https://api.github.com/users/amankhandelia/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/amankhandelia/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/amankhandelia/subscriptions",
"type": "User",
"url": "https://api.github.com/users/amankhandelia",
"user_view_type": "public"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"Hi :) Good catch ! Feel free to open a PR if you want to contribute, this would be very welcome ;)",
"Have raised the PR [here](https://github.com/huggingface/datasets/pull/2717)",
"Fixed by #2717."
] | 2021-07-26T13:24:59Z | 2021-07-26T18:04:43Z | 2021-07-26T18:04:43Z | CONTRIBUTOR | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | When using dataset in streaming mode, if one applies `shuffle` method on the dataset and `map` method for which `batched=True` than the batching operation will not happen, instead `batched` will be set to `False`
I did RCA on the dataset codebase, the problem is emerging from [this line of code](https://github.com/huggingface/datasets/blob/d25a0bf94d9f9a9aa6cabdf5b450b9c327d19729/src/datasets/iterable_dataset.py#L197) here as it is
`self.ex_iterable.shuffle_data_sources(seed), function=self.function, batch_size=self.batch_size`, as one can see it is missing batched argument, which means that the iterator fallsback to default constructor value, which in this case is `False`.
To remedy the problem we can change this line to
`self.ex_iterable.shuffle_data_sources(seed), function=self.function, batched=self.batched, batch_size=self.batch_size`
| {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2716/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2716/timeline | null | completed | null | null | 4.662222 | 4,859 |
https://api.github.com/repos/huggingface/datasets/issues/2709 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2709/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2709/comments | https://api.github.com/repos/huggingface/datasets/issues/2709/events | https://github.com/huggingface/datasets/issues/2709 | 951,534,757 | MDU6SXNzdWU5NTE1MzQ3NTc= | 2,709 | Missing documentation for wnut_17 (ner_tags) | {
"avatar_url": "https://avatars.githubusercontent.com/u/31095360?v=4",
"events_url": "https://api.github.com/users/maxpel/events{/privacy}",
"followers_url": "https://api.github.com/users/maxpel/followers",
"following_url": "https://api.github.com/users/maxpel/following{/other_user}",
"gists_url": "https://api.github.com/users/maxpel/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/maxpel",
"id": 31095360,
"login": "maxpel",
"node_id": "MDQ6VXNlcjMxMDk1MzYw",
"organizations_url": "https://api.github.com/users/maxpel/orgs",
"received_events_url": "https://api.github.com/users/maxpel/received_events",
"repos_url": "https://api.github.com/users/maxpel/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/maxpel/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/maxpel/subscriptions",
"type": "User",
"url": "https://api.github.com/users/maxpel",
"user_view_type": "public"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [
"Hi @maxpel, thanks for reporting this issue.\r\n\r\nIndeed, the documentation in the dataset card is not complete. I’m opening a Pull Request to fix it.\r\n\r\nAs the paper explains, there are 6 entity types and we have ordered them alphabetically: `corporation`, `creative-work`, `group`, `location`, `person` and ... | 2021-07-23T12:25:32Z | 2021-07-26T09:30:55Z | 2021-07-26T09:30:55Z | CONTRIBUTOR | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | On the info page of the wnut_17 data set (https://huggingface.co/datasets/wnut_17), the model output of ner-tags is only documented for these 5 cases:
`ner_tags: a list of classification labels, with possible values including O (0), B-corporation (1), I-corporation (2), B-creative-work (3), I-creative-work (4).`
I trained a model with the data and it gives me 13 classes:
```
"id2label": {
"0": 0,
"1": 1,
"2": 2,
"3": 3,
"4": 4,
"5": 5,
"6": 6,
"7": 7,
"8": 8,
"9": 9,
"10": 10,
"11": 11,
"12": 12
}
"label2id": {
"0": 0,
"1": 1,
"10": 10,
"11": 11,
"12": 12,
"2": 2,
"3": 3,
"4": 4,
"5": 5,
"6": 6,
"7": 7,
"8": 8,
"9": 9
}
```
The paper (https://www.aclweb.org/anthology/W17-4418.pdf) explains those 6 categories, but the ordering does not match:
```
1. person
2. location (including GPE, facility)
3. corporation
4. product (tangible goods, or well-defined
services)
5. creative-work (song, movie, book and
so on)
6. group (subsuming music band, sports team,
and non-corporate organisations)
```
I would be very helpful for me, if somebody could clarify the model ouputs and explain the "B-" and "I-" prefixes to me.
Really great work with that and the other packages, I couldn't believe that training the model with that data was basically a one-liner! | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2709/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2709/timeline | null | completed | null | null | 69.089722 | 4,864 |
https://api.github.com/repos/huggingface/datasets/issues/2708 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2708/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2708/comments | https://api.github.com/repos/huggingface/datasets/issues/2708/events | https://github.com/huggingface/datasets/issues/2708 | 951,092,660 | MDU6SXNzdWU5NTEwOTI2NjA= | 2,708 | QASC: incomplete training set | {
"avatar_url": "https://avatars.githubusercontent.com/u/2441454?v=4",
"events_url": "https://api.github.com/users/danyaljj/events{/privacy}",
"followers_url": "https://api.github.com/users/danyaljj/followers",
"following_url": "https://api.github.com/users/danyaljj/following{/other_user}",
"gists_url": "https://api.github.com/users/danyaljj/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/danyaljj",
"id": 2441454,
"login": "danyaljj",
"node_id": "MDQ6VXNlcjI0NDE0NTQ=",
"organizations_url": "https://api.github.com/users/danyaljj/orgs",
"received_events_url": "https://api.github.com/users/danyaljj/received_events",
"repos_url": "https://api.github.com/users/danyaljj/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/danyaljj/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/danyaljj/subscriptions",
"type": "User",
"url": "https://api.github.com/users/danyaljj",
"user_view_type": "public"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"Hi @danyaljj, thanks for reporting.\r\n\r\nUnfortunately, I have not been able to reproduce your problem. My train split has 8134 examples:\r\n```ipython\r\nIn [10]: ds[\"train\"]\r\nOut[10]:\r\nDataset({\r\n features: ['id', 'question', 'choices', 'answerKey', 'fact1', 'fact2', 'combinedfact', 'formatted_quest... | 2021-07-22T21:59:44Z | 2021-07-23T13:30:07Z | 2021-07-23T13:30:07Z | CONTRIBUTOR | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ## Describe the bug
The training instances are not loaded properly.
## Steps to reproduce the bug
```python
from datasets import load_dataset
dataset = load_dataset("qasc", script_version='1.10.2')
def load_instances(split):
instances = dataset[split]
print(f"split: {split} - size: {len(instances)}")
for x in instances:
print(json.dumps(x))
load_instances('test')
load_instances('validation')
load_instances('train')
```
## results
For test and validation, we can see the examples in the output (which is good!):
```
split: test - size: 920
{"answerKey": "", "choices": {"label": ["A", "B", "C", "D", "E", "F", "G", "H"], "text": ["Anthax", "under water", "uterus", "wombs", "two", "moles", "live", "embryo"]}, "combinedfact": "", "fact1": "", "fact2": "", "formatted_question": "What type of birth do therian mammals have? (A) Anthax (B) under water (C) uterus (D) wombs (E) two (F) moles (G) live (H) embryo", "id": "3C44YUNSI1OBFBB8D36GODNOZN9DPA", "question": "What type of birth do therian mammals have?"}
{"answerKey": "", "choices": {"label": ["A", "B", "C", "D", "E", "F", "G", "H"], "text": ["Corvidae", "arthropods", "birds", "backbones", "keratin", "Jurassic", "front paws", "Parakeets."]}, "combinedfact": "", "fact1": "", "fact2": "", "formatted_question": "By what time had mouse-sized viviparous mammals evolved? (A) Corvidae (B) arthropods (C) birds (D) backbones (E) keratin (F) Jurassic (G) front paws (H) Parakeets.", "id": "3B1NLC6UGZVERVLZFT7OUYQLD1SGPZ", "question": "By what time had mouse-sized viviparous mammals evolved?"}
{"answerKey": "", "choices": {"label": ["A", "B", "C", "D", "E", "F", "G", "H"], "text": ["Reduced friction", "causes infection", "vital to a good life", "prevents water loss", "camouflage from consumers", "Protection against predators", "spur the growth of the plant", "a smooth surface"]}, "combinedfact": "", "fact1": "", "fact2": "", "formatted_question": "What does a plant's skin do? (A) Reduced friction (B) causes infection (C) vital to a good life (D) prevents water loss (E) camouflage from consumers (F) Protection against predators (G) spur the growth of the plant (H) a smooth surface", "id": "3QRYMNZ7FYGITFVSJET3PS0F4S0NT9", "question": "What does a plant's skin do?"}
...
```
However, only a few instances are loaded for the training split, which is not correct.
## Environment info
- `datasets` version: '1.10.2'
- Platform: MaxOS
- Python version:3.7
- PyArrow version: 3.0.0
| {
"avatar_url": "https://avatars.githubusercontent.com/u/2441454?v=4",
"events_url": "https://api.github.com/users/danyaljj/events{/privacy}",
"followers_url": "https://api.github.com/users/danyaljj/followers",
"following_url": "https://api.github.com/users/danyaljj/following{/other_user}",
"gists_url": "https://api.github.com/users/danyaljj/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/danyaljj",
"id": 2441454,
"login": "danyaljj",
"node_id": "MDQ6VXNlcjI0NDE0NTQ=",
"organizations_url": "https://api.github.com/users/danyaljj/orgs",
"received_events_url": "https://api.github.com/users/danyaljj/received_events",
"repos_url": "https://api.github.com/users/danyaljj/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/danyaljj/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/danyaljj/subscriptions",
"type": "User",
"url": "https://api.github.com/users/danyaljj",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2708/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2708/timeline | null | completed | null | null | 15.506389 | 4,865 |
https://api.github.com/repos/huggingface/datasets/issues/2707 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2707/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2707/comments | https://api.github.com/repos/huggingface/datasets/issues/2707/events | https://github.com/huggingface/datasets/issues/2707 | 950,812,945 | MDU6SXNzdWU5NTA4MTI5NDU= | 2,707 | 404 Not Found Error when loading LAMA dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/26467159?v=4",
"events_url": "https://api.github.com/users/dwil2444/events{/privacy}",
"followers_url": "https://api.github.com/users/dwil2444/followers",
"following_url": "https://api.github.com/users/dwil2444/following{/other_user}",
"gists_url": "https://api.github.com/users/dwil2444/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/dwil2444",
"id": 26467159,
"login": "dwil2444",
"node_id": "MDQ6VXNlcjI2NDY3MTU5",
"organizations_url": "https://api.github.com/users/dwil2444/orgs",
"received_events_url": "https://api.github.com/users/dwil2444/received_events",
"repos_url": "https://api.github.com/users/dwil2444/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/dwil2444/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/dwil2444/subscriptions",
"type": "User",
"url": "https://api.github.com/users/dwil2444",
"user_view_type": "public"
} | [] | closed | false | null | [] | null | [
"Hi @dwil2444! I was able to reproduce your error when I downgraded to v1.1.2. Updating to the latest version of Datasets fixed the error for me :)",
"Hi @dwil2444, thanks for reporting.\r\n\r\nCould you please confirm which `datasets` version you were using and if the problem persists after you update it to the ... | 2021-07-22T15:52:33Z | 2021-07-26T14:29:07Z | 2021-07-26T14:29:07Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | The [LAMA](https://huggingface.co/datasets/viewer/?dataset=lama) probing dataset is not available for download:
Steps to Reproduce:
1. `from datasets import load_dataset`
2. `dataset = load_dataset('lama', 'trex')`.
Results:
`FileNotFoundError: Couldn't find file locally at lama/lama.py, or remotely at https://raw.githubusercontent.com/huggingface/datasets/1.1.2/datasets/lama/lama.py or https://s3.amazonaws.com/datasets.huggingface.co/datasets/datasets/lama/lama.py` | {
"avatar_url": "https://avatars.githubusercontent.com/u/26467159?v=4",
"events_url": "https://api.github.com/users/dwil2444/events{/privacy}",
"followers_url": "https://api.github.com/users/dwil2444/followers",
"following_url": "https://api.github.com/users/dwil2444/following{/other_user}",
"gists_url": "https://api.github.com/users/dwil2444/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/dwil2444",
"id": 26467159,
"login": "dwil2444",
"node_id": "MDQ6VXNlcjI2NDY3MTU5",
"organizations_url": "https://api.github.com/users/dwil2444/orgs",
"received_events_url": "https://api.github.com/users/dwil2444/received_events",
"repos_url": "https://api.github.com/users/dwil2444/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/dwil2444/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/dwil2444/subscriptions",
"type": "User",
"url": "https://api.github.com/users/dwil2444",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2707/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2707/timeline | null | completed | null | null | 94.609444 | 4,866 |
https://api.github.com/repos/huggingface/datasets/issues/2705 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2705/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2705/comments | https://api.github.com/repos/huggingface/datasets/issues/2705/events | https://github.com/huggingface/datasets/issues/2705 | 950,488,583 | MDU6SXNzdWU5NTA0ODg1ODM= | 2,705 | 404 not found error on loading WIKIANN dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/39296659?v=4",
"events_url": "https://api.github.com/users/ronbutan/events{/privacy}",
"followers_url": "https://api.github.com/users/ronbutan/followers",
"following_url": "https://api.github.com/users/ronbutan/following{/other_user}",
"gists_url": "https://api.github.com/users/ronbutan/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/ronbutan",
"id": 39296659,
"login": "ronbutan",
"node_id": "MDQ6VXNlcjM5Mjk2NjU5",
"organizations_url": "https://api.github.com/users/ronbutan/orgs",
"received_events_url": "https://api.github.com/users/ronbutan/received_events",
"repos_url": "https://api.github.com/users/ronbutan/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/ronbutan/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ronbutan/subscriptions",
"type": "User",
"url": "https://api.github.com/users/ronbutan",
"user_view_type": "public"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"Hi @ronbutan, thanks for reporting.\r\n\r\nYou are right: we have recently found that the link to the original PAN-X dataset (also called WikiANN), hosted at Dropbox, is no longer working.\r\n\r\nWe have opened an issue in the GitHub repository of the original dataset (afshinrahimi/mmner#4) and we have also contac... | 2021-07-22T09:55:50Z | 2021-07-23T08:07:32Z | 2021-07-23T08:07:32Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ## Describe the bug
Unable to retreive wikiann English dataset
## Steps to reproduce the bug
```python
from datasets import list_datasets, load_dataset, list_metrics, load_metric
WIKIANN = load_dataset("wikiann","en")
```
## Expected results
Colab notebook should display successful download status
## Actual results
FileNotFoundError: Couldn't find file at https://www.dropbox.com/s/12h3qqog6q4bjve/panx_dataset.tar?dl=1
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.10.1
- Platform: Linux-5.4.104+-x86_64-with-Ubuntu-18.04-bionic
- Python version: 3.7.11
- PyArrow version: 3.0.0
| {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2705/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2705/timeline | null | completed | null | null | 22.195 | 4,868 |
https://api.github.com/repos/huggingface/datasets/issues/2703 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2703/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2703/comments | https://api.github.com/repos/huggingface/datasets/issues/2703/events | https://github.com/huggingface/datasets/issues/2703 | 950,482,284 | MDU6SXNzdWU5NTA0ODIyODQ= | 2,703 | Bad message when config name is missing | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
} | [] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists... | null | [] | 2021-07-22T09:47:23Z | 2021-07-22T10:02:40Z | 2021-07-22T10:02:40Z | MEMBER | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | When loading a dataset that have several configurations, we expect to see an error message if the user doesn't specify a config name.
However in `datasets` 1.10.0 and 1.10.1 it doesn't show the right message:
```python
import datasets
datasets.load_dataset("glue")
```
raises
```python
AttributeError: 'BuilderConfig' object has no attribute 'text_features'
```
instead of
```python
ValueError: Config name is missing.
Please pick one among the available configs: ['cola', 'sst2', 'mrpc', 'qqp', 'stsb', 'mnli', 'mnli_mismatched', 'mnli_matched', 'qnli', 'rte', 'wnli', 'ax']
Example of usage:
`load_dataset('glue', 'cola')`
``` | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2703/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2703/timeline | null | completed | null | null | 0.254722 | 4,870 |
https://api.github.com/repos/huggingface/datasets/issues/2700 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2700/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2700/comments | https://api.github.com/repos/huggingface/datasets/issues/2700/events | https://github.com/huggingface/datasets/issues/2700 | 950,276,325 | MDU6SXNzdWU5NTAyNzYzMjU= | 2,700 | from datasets import Dataset is failing | {
"avatar_url": "https://avatars.githubusercontent.com/u/5582286?v=4",
"events_url": "https://api.github.com/users/kswamy15/events{/privacy}",
"followers_url": "https://api.github.com/users/kswamy15/followers",
"following_url": "https://api.github.com/users/kswamy15/following{/other_user}",
"gists_url": "https://api.github.com/users/kswamy15/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/kswamy15",
"id": 5582286,
"login": "kswamy15",
"node_id": "MDQ6VXNlcjU1ODIyODY=",
"organizations_url": "https://api.github.com/users/kswamy15/orgs",
"received_events_url": "https://api.github.com/users/kswamy15/received_events",
"repos_url": "https://api.github.com/users/kswamy15/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/kswamy15/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/kswamy15/subscriptions",
"type": "User",
"url": "https://api.github.com/users/kswamy15",
"user_view_type": "public"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"Hi @kswamy15, thanks for reporting.\r\n\r\nWe are fixing this critical issue and making an urgent patch release of the `datasets` library today.\r\n\r\nIn the meantime, you can circumvent this issue by updating the `tqdm` library: `!pip install -U tqdm`"
] | 2021-07-22T03:51:23Z | 2021-07-22T07:23:45Z | 2021-07-22T07:09:07Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ## Describe the bug
A clear and concise description of what the bug is.
## Steps to reproduce the bug
```python
# Sample code to reproduce the bug
from datasets import Dataset
```
## Expected results
A clear and concise description of the expected results.
## Actual results
Specify the actual results or traceback.
/usr/local/lib/python3.7/dist-packages/datasets/utils/file_utils.py in <module>()
25 import posixpath
26 import requests
---> 27 from tqdm.contrib.concurrent import thread_map
28
29 from .. import __version__, config, utils
ModuleNotFoundError: No module named 'tqdm.contrib.concurrent'
---------------------------------------------------------------------------
NOTE: If your import is failing due to a missing package, you can
manually install dependencies using either !pip or !apt.
To view examples of installing some common dependencies, click the
"Open Examples" button below.
---------------------------------------------------------------------------
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: latest version as of 07/21/2021
- Platform: Google Colab
- Python version: 3.7
- PyArrow version:
| {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2700/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2700/timeline | null | completed | null | null | 3.295556 | 4,873 |
https://api.github.com/repos/huggingface/datasets/issues/2695 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2695/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2695/comments | https://api.github.com/repos/huggingface/datasets/issues/2695/events | https://github.com/huggingface/datasets/issues/2695 | 949,864,823 | MDU6SXNzdWU5NDk4NjQ4MjM= | 2,695 | Cannot import load_dataset on Colab | {
"avatar_url": "https://avatars.githubusercontent.com/u/43239645?v=4",
"events_url": "https://api.github.com/users/bayartsogt-ya/events{/privacy}",
"followers_url": "https://api.github.com/users/bayartsogt-ya/followers",
"following_url": "https://api.github.com/users/bayartsogt-ya/following{/other_user}",
"gists_url": "https://api.github.com/users/bayartsogt-ya/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/bayartsogt-ya",
"id": 43239645,
"login": "bayartsogt-ya",
"node_id": "MDQ6VXNlcjQzMjM5NjQ1",
"organizations_url": "https://api.github.com/users/bayartsogt-ya/orgs",
"received_events_url": "https://api.github.com/users/bayartsogt-ya/received_events",
"repos_url": "https://api.github.com/users/bayartsogt-ya/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/bayartsogt-ya/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/bayartsogt-ya/subscriptions",
"type": "User",
"url": "https://api.github.com/users/bayartsogt-ya",
"user_view_type": "public"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"I'm facing the same issue on Colab today too.\r\n\r\n```\r\nModuleNotFoundError Traceback (most recent call last)\r\n<ipython-input-4-5833ac0f5437> in <module>()\r\n 3 \r\n 4 from ray import tune\r\n----> 5 from datasets import DatasetDict, Dataset\r\n 6 from datasets import lo... | 2021-07-21T15:52:51Z | 2021-07-22T07:26:25Z | 2021-07-22T07:09:07Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ## Describe the bug
Got tqdm concurrent module not found error during importing load_dataset from datasets.
## Steps to reproduce the bug
Here [colab notebook](https://colab.research.google.com/drive/1pErWWnVP4P4mVHjSFUtkePd8Na_Qirg4?usp=sharing) to reproduce the error
On colab:
```python
!pip install datasets
from datasets import load_dataset
```
## Expected results
Works without error
## Actual results
Specify the actual results or traceback.
```
ModuleNotFoundError Traceback (most recent call last)
<ipython-input-2-8cc7de4c69eb> in <module>()
----> 1 from datasets import load_dataset, load_metric, Metric, MetricInfo, Features, Value
2 from sklearn.metrics import mean_squared_error
/usr/local/lib/python3.7/dist-packages/datasets/__init__.py in <module>()
31 )
32
---> 33 from .arrow_dataset import Dataset, concatenate_datasets
34 from .arrow_reader import ArrowReader, ReadInstruction
35 from .arrow_writer import ArrowWriter
/usr/local/lib/python3.7/dist-packages/datasets/arrow_dataset.py in <module>()
40 from tqdm.auto import tqdm
41
---> 42 from datasets.tasks.text_classification import TextClassification
43
44 from . import config, utils
/usr/local/lib/python3.7/dist-packages/datasets/tasks/__init__.py in <module>()
1 from typing import Optional
2
----> 3 from ..utils.logging import get_logger
4 from .automatic_speech_recognition import AutomaticSpeechRecognition
5 from .base import TaskTemplate
/usr/local/lib/python3.7/dist-packages/datasets/utils/__init__.py in <module>()
19
20 from . import logging
---> 21 from .download_manager import DownloadManager, GenerateMode
22 from .file_utils import DownloadConfig, cached_path, hf_bucket_url, is_remote_url, temp_seed
23 from .mock_download_manager import MockDownloadManager
/usr/local/lib/python3.7/dist-packages/datasets/utils/download_manager.py in <module>()
24
25 from .. import config
---> 26 from .file_utils import (
27 DownloadConfig,
28 cached_path,
/usr/local/lib/python3.7/dist-packages/datasets/utils/file_utils.py in <module>()
25 import posixpath
26 import requests
---> 27 from tqdm.contrib.concurrent import thread_map
28
29 from .. import __version__, config, utils
ModuleNotFoundError: No module named 'tqdm.contrib.concurrent'
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.10.0
- Platform: Colab
- Python version: 3.7.11
- PyArrow version: 3.0.0
| {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | {
"+1": 3,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 3,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2695/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2695/timeline | null | completed | null | null | 15.271111 | 4,878 |
https://api.github.com/repos/huggingface/datasets/issues/2691 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2691/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2691/comments | https://api.github.com/repos/huggingface/datasets/issues/2691/events | https://github.com/huggingface/datasets/issues/2691 | 949,758,379 | MDU6SXNzdWU5NDk3NTgzNzk= | 2,691 | xtreme / pan-x cannot be downloaded | {
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://api.github.com/users/severo/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/severo",
"id": 1676121,
"login": "severo",
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"organizations_url": "https://api.github.com/users/severo/orgs",
"received_events_url": "https://api.github.com/users/severo/received_events",
"repos_url": "https://api.github.com/users/severo/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/severo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/severo/subscriptions",
"type": "User",
"url": "https://api.github.com/users/severo",
"user_view_type": "public"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"Hi @severo, thanks for reporting.\r\n\r\nHowever I have not been able to reproduce this issue. Could you please confirm if the problem persists for you?\r\n\r\nMaybe Dropbox (where the data source is hosted) was temporarily unavailable when you tried.",
"Hmmm, the file (https://www.dropbox.com/s/dl/12h3qqog6q4bj... | 2021-07-21T14:18:05Z | 2021-07-26T09:34:22Z | 2021-07-26T09:34:22Z | COLLABORATOR | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ## Describe the bug
Dataset xtreme / pan-x cannot be loaded
Seems related to https://github.com/huggingface/datasets/pull/2326
## Steps to reproduce the bug
```python
dataset = load_dataset("xtreme", "PAN-X.fr")
```
## Expected results
Load the dataset
## Actual results
```
FileNotFoundError: Couldn't find file at https://www.dropbox.com/s/12h3qqog6q4bjve/panx_dataset.tar?dl=1
```
## Environment info
- `datasets` version: 1.9.0
- Platform: macOS-11.4-x86_64-i386-64bit
- Python version: 3.8.11
- PyArrow version: 4.0.1
| {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2691/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2691/timeline | null | completed | null | null | 115.271389 | 4,882 |
https://api.github.com/repos/huggingface/datasets/issues/2689 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2689/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2689/comments | https://api.github.com/repos/huggingface/datasets/issues/2689/events | https://github.com/huggingface/datasets/issues/2689 | 949,447,104 | MDU6SXNzdWU5NDk0NDcxMDQ= | 2,689 | cannot save the dataset to disk after rename_column | {
"avatar_url": "https://avatars.githubusercontent.com/u/25532159?v=4",
"events_url": "https://api.github.com/users/PaulLerner/events{/privacy}",
"followers_url": "https://api.github.com/users/PaulLerner/followers",
"following_url": "https://api.github.com/users/PaulLerner/following{/other_user}",
"gists_url": "https://api.github.com/users/PaulLerner/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/PaulLerner",
"id": 25532159,
"login": "PaulLerner",
"node_id": "MDQ6VXNlcjI1NTMyMTU5",
"organizations_url": "https://api.github.com/users/PaulLerner/orgs",
"received_events_url": "https://api.github.com/users/PaulLerner/received_events",
"repos_url": "https://api.github.com/users/PaulLerner/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/PaulLerner/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/PaulLerner/subscriptions",
"type": "User",
"url": "https://api.github.com/users/PaulLerner",
"user_view_type": "public"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"Hi ! That's because you are trying to overwrite a file that is already open and being used.\r\nIndeed `foo/dataset.arrow` is open and used by your `dataset` object.\r\n\r\nWhen you do `rename_column`, the resulting dataset reads the data from the same arrow file.\r\nIn other cases like when using `map` on the othe... | 2021-07-21T08:13:40Z | 2025-02-11T23:23:17Z | 2021-07-21T13:11:04Z | CONTRIBUTOR | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ## Describe the bug
If you use `rename_column` and do no other modification, you will be unable to save the dataset using `save_to_disk`
## Steps to reproduce the bug
```python
# Sample code to reproduce the bug
In [1]: from datasets import Dataset, load_from_disk
In [5]: dataset=Dataset.from_dict({'foo': [0]})
In [7]: dataset.save_to_disk('foo')
In [8]: dataset=load_from_disk('foo')
In [10]: dataset=dataset.rename_column('foo', 'bar')
In [11]: dataset.save_to_disk('foo')
---------------------------------------------------------------------------
PermissionError Traceback (most recent call last)
<ipython-input-11-a3bc0d4fc339> in <module>
----> 1 dataset.save_to_disk('foo')
/mnt/beegfs/projects/meerqat/anaconda3/envs/meerqat/lib/python3.7/site-packages/datasets/arrow_dataset.py in save_to_disk(self, dataset_path
, fs)
597 if Path(dataset_path, config.DATASET_ARROW_FILENAME) in cache_files_paths:
598 raise PermissionError(
--> 599 f"Tried to overwrite {Path(dataset_path, config.DATASET_ARROW_FILENAME)} but a dataset can't overwrite itself."
600 )
601 if Path(dataset_path, config.DATASET_INDICES_FILENAME) in cache_files_paths:
PermissionError: Tried to overwrite foo/dataset.arrow but a dataset can't overwrite itself.
```
N. B. I created the dataset from dict to enable easy reproduction but the same happens if you load an existing dataset (e.g. starting from `In [8]`)
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.8.0
- Platform: Linux-3.10.0-1160.11.1.el7.x86_64-x86_64-with-centos-7.9.2009-Core
- Python version: 3.7.10
- PyArrow version: 3.0.0
| {
"avatar_url": "https://avatars.githubusercontent.com/u/25532159?v=4",
"events_url": "https://api.github.com/users/PaulLerner/events{/privacy}",
"followers_url": "https://api.github.com/users/PaulLerner/followers",
"following_url": "https://api.github.com/users/PaulLerner/following{/other_user}",
"gists_url": "https://api.github.com/users/PaulLerner/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/PaulLerner",
"id": 25532159,
"login": "PaulLerner",
"node_id": "MDQ6VXNlcjI1NTMyMTU5",
"organizations_url": "https://api.github.com/users/PaulLerner/orgs",
"received_events_url": "https://api.github.com/users/PaulLerner/received_events",
"repos_url": "https://api.github.com/users/PaulLerner/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/PaulLerner/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/PaulLerner/subscriptions",
"type": "User",
"url": "https://api.github.com/users/PaulLerner",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2689/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2689/timeline | null | completed | null | null | 4.956667 | 4,884 |
https://api.github.com/repos/huggingface/datasets/issues/2688 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2688/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2688/comments | https://api.github.com/repos/huggingface/datasets/issues/2688/events | https://github.com/huggingface/datasets/issues/2688 | 949,182,074 | MDU6SXNzdWU5NDkxODIwNzQ= | 2,688 | hebrew language codes he and iw should be treated as aliases | {
"avatar_url": "https://avatars.githubusercontent.com/u/4436747?v=4",
"events_url": "https://api.github.com/users/eyaler/events{/privacy}",
"followers_url": "https://api.github.com/users/eyaler/followers",
"following_url": "https://api.github.com/users/eyaler/following{/other_user}",
"gists_url": "https://api.github.com/users/eyaler/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/eyaler",
"id": 4436747,
"login": "eyaler",
"node_id": "MDQ6VXNlcjQ0MzY3NDc=",
"organizations_url": "https://api.github.com/users/eyaler/orgs",
"received_events_url": "https://api.github.com/users/eyaler/received_events",
"repos_url": "https://api.github.com/users/eyaler/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/eyaler/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/eyaler/subscriptions",
"type": "User",
"url": "https://api.github.com/users/eyaler",
"user_view_type": "public"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"Hi @eyaler, thanks for reporting.\r\n\r\nWhile you are true with respect the Hebrew language tag (\"iw\" is deprecated and \"he\" is the preferred value), in the \"mc4\" dataset (which is a derived dataset) we have kept the language tags present in the original dataset: [Google C4](https://www.tensorflow.org/datas... | 2021-07-20T23:13:52Z | 2021-07-21T16:34:53Z | 2021-07-21T16:34:53Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | https://huggingface.co/datasets/mc4 not listed when searching for hebrew datasets (he) as it uses the older language code iw, preventing discoverability. | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2688/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2688/timeline | null | completed | null | null | 17.350278 | 4,885 |
https://api.github.com/repos/huggingface/datasets/issues/2683 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2683/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2683/comments | https://api.github.com/repos/huggingface/datasets/issues/2683/events | https://github.com/huggingface/datasets/issues/2683 | 948,721,379 | MDU6SXNzdWU5NDg3MjEzNzk= | 2,683 | Cache directories changed due to recent changes in how config kwargs are handled | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
} | [] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists... | null | [] | 2021-07-20T14:37:57Z | 2021-07-20T16:27:15Z | 2021-07-20T16:27:15Z | MEMBER | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | Since #2659 I can see weird cache directory names with hashes in the config id, even though no additional config kwargs are passed. For example:
```python
from datasets import load_dataset_builder
c4_builder = load_dataset_builder("c4", "en")
print(c4_builder.cache_dir)
# /Users/quentinlhoest/.cache/huggingface/datasets/c4/en-174d3b7155eb68db/0.0.0/...
# instead of
# /Users/quentinlhoest/.cache/huggingface/datasets/c4/en/0.0.0/...
```
This issue could be annoying since it would simply ignore old cache directories for users, and regenerate datasets
cc @stas00 this is what you experienced a few days ago
| {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2683/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2683/timeline | null | completed | null | null | 1.821667 | 4,890 |
https://api.github.com/repos/huggingface/datasets/issues/2681 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2681/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2681/comments | https://api.github.com/repos/huggingface/datasets/issues/2681/events | https://github.com/huggingface/datasets/issues/2681 | 948,708,645 | MDU6SXNzdWU5NDg3MDg2NDU= | 2,681 | 5 duplicate datasets | {
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://api.github.com/users/severo/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/severo",
"id": 1676121,
"login": "severo",
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"organizations_url": "https://api.github.com/users/severo/orgs",
"received_events_url": "https://api.github.com/users/severo/received_events",
"repos_url": "https://api.github.com/users/severo/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/severo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/severo/subscriptions",
"type": "User",
"url": "https://api.github.com/users/severo",
"user_view_type": "public"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"Yes this was documented in the PR that added this hf->paperswithcode mapping (https://github.com/huggingface/datasets/pull/2404) and AFAICT those are slightly distinct datasets so I think it's a wontfix\r\n\r\nFor context on the paperswithcode mapping you can also refer to https://github.com/huggingface/huggingfac... | 2021-07-20T14:25:00Z | 2021-07-20T15:44:17Z | 2021-07-20T15:44:17Z | COLLABORATOR | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ## Describe the bug
In 5 cases, I could find a dataset on Paperswithcode which references two Hugging Face datasets as dataset loaders. They are:
- https://paperswithcode.com/dataset/multinli -> https://huggingface.co/datasets/multi_nli and https://huggingface.co/datasets/multi_nli_mismatch
<img width="838" alt="Capture d’écran 2021-07-20 à 16 33 58" src="https://user-images.githubusercontent.com/1676121/126342757-4625522a-f788-41a3-bd1f-2a8b9817bbf5.png">
- https://paperswithcode.com/dataset/squad -> https://huggingface.co/datasets/squad and https://huggingface.co/datasets/squad_v2
- https://paperswithcode.com/dataset/narrativeqa -> https://huggingface.co/datasets/narrativeqa and https://huggingface.co/datasets/narrativeqa_manual
- https://paperswithcode.com/dataset/hate-speech-and-offensive-language -> https://huggingface.co/datasets/hate_offensive and https://huggingface.co/datasets/hate_speech_offensive
- https://paperswithcode.com/dataset/newsph-nli -> https://huggingface.co/datasets/newsph and https://huggingface.co/datasets/newsph_nli
Possible solutions:
- don't fix (it works)
- for each pair of duplicate datasets, remove one, and create an alias to the other.
## Steps to reproduce the bug
Visit the Paperswithcode links, and look at the "Dataset Loaders" section
## Expected results
There should only be one reference to a Hugging Face dataset loader
## Actual results
Two Hugging Face dataset loaders
| {
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://api.github.com/users/severo/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/severo",
"id": 1676121,
"login": "severo",
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"organizations_url": "https://api.github.com/users/severo/orgs",
"received_events_url": "https://api.github.com/users/severo/received_events",
"repos_url": "https://api.github.com/users/severo/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/severo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/severo/subscriptions",
"type": "User",
"url": "https://api.github.com/users/severo",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2681/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2681/timeline | null | completed | null | null | 1.321389 | 4,892 |
https://api.github.com/repos/huggingface/datasets/issues/2679 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2679/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2679/comments | https://api.github.com/repos/huggingface/datasets/issues/2679/events | https://github.com/huggingface/datasets/issues/2679 | 948,506,638 | MDU6SXNzdWU5NDg1MDY2Mzg= | 2,679 | Cannot load the blog_authorship_corpus due to codec errors | {
"avatar_url": "https://avatars.githubusercontent.com/u/38069449?v=4",
"events_url": "https://api.github.com/users/izaskr/events{/privacy}",
"followers_url": "https://api.github.com/users/izaskr/followers",
"following_url": "https://api.github.com/users/izaskr/following{/other_user}",
"gists_url": "https://api.github.com/users/izaskr/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/izaskr",
"id": 38069449,
"login": "izaskr",
"node_id": "MDQ6VXNlcjM4MDY5NDQ5",
"organizations_url": "https://api.github.com/users/izaskr/orgs",
"received_events_url": "https://api.github.com/users/izaskr/received_events",
"repos_url": "https://api.github.com/users/izaskr/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/izaskr/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/izaskr/subscriptions",
"type": "User",
"url": "https://api.github.com/users/izaskr",
"user_view_type": "public"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [
"Hi @izaskr, thanks for reporting.\r\n\r\nHowever the traceback you joined does not correspond to the codec error message: it is about other error `NonMatchingSplitsSizesError`. Maybe you missed some important part of your traceback...\r\n\r\nI'm going to have a look at the dataset anyway...",
"Hi @izaskr, thanks... | 2021-07-20T10:13:20Z | 2021-07-21T17:02:21Z | 2021-07-21T13:11:58Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ## Describe the bug
A codec error is raised while loading the blog_authorship_corpus.
## Steps to reproduce the bug
```
from datasets import load_dataset
raw_datasets = load_dataset("blog_authorship_corpus")
```
## Expected results
Loading the dataset without errors.
## Actual results
An error similar to the one below was raised for (what seems like) every XML file.
/home/izaskr/.cache/huggingface/datasets/downloads/extracted/7cf52524f6517e168604b41c6719292e8f97abbe8f731e638b13423f4212359a/blogs/788358.male.24.Arts.Libra.xml cannot be loaded. Error message: 'utf-8' codec can't decode byte 0xe7 in position 7551: invalid continuation byte
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/izaskr/anaconda3/envs/local_vae_older/lib/python3.8/site-packages/datasets/load.py", line 856, in load_dataset
builder_instance.download_and_prepare(
File "/home/izaskr/anaconda3/envs/local_vae_older/lib/python3.8/site-packages/datasets/builder.py", line 583, in download_and_prepare
self._download_and_prepare(
File "/home/izaskr/anaconda3/envs/local_vae_older/lib/python3.8/site-packages/datasets/builder.py", line 671, in _download_and_prepare
verify_splits(self.info.splits, split_dict)
File "/home/izaskr/anaconda3/envs/local_vae_older/lib/python3.8/site-packages/datasets/utils/info_utils.py", line 74, in verify_splits
raise NonMatchingSplitsSizesError(str(bad_splits))
datasets.utils.info_utils.NonMatchingSplitsSizesError: [{'expected': SplitInfo(name='train', num_bytes=610252351, num_examples=532812, dataset_name='blog_authorship_corpus'), 'recorded': SplitInfo(name='train', num_bytes=614706451, num_examples=535568, dataset_name='blog_authorship_corpus')}, {'expected': SplitInfo(name='validation', num_bytes=37500394, num_examples=31277, dataset_name='blog_authorship_corpus'), 'recorded': SplitInfo(name='validation', num_bytes=32553710, num_examples=28521, dataset_name='blog_authorship_corpus')}]
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.9.0
- Platform: Linux-4.15.0-132-generic-x86_64-with-glibc2.10
- Python version: 3.8.8
- PyArrow version: 4.0.1
| {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2679/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2679/timeline | null | completed | null | null | 26.977222 | 4,894 |
https://api.github.com/repos/huggingface/datasets/issues/2678 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2678/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2678/comments | https://api.github.com/repos/huggingface/datasets/issues/2678/events | https://github.com/huggingface/datasets/issues/2678 | 948,471,222 | MDU6SXNzdWU5NDg0NzEyMjI= | 2,678 | Import Error in Kaggle notebook | {
"avatar_url": "https://avatars.githubusercontent.com/u/47216475?v=4",
"events_url": "https://api.github.com/users/prikmm/events{/privacy}",
"followers_url": "https://api.github.com/users/prikmm/followers",
"following_url": "https://api.github.com/users/prikmm/following{/other_user}",
"gists_url": "https://api.github.com/users/prikmm/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/prikmm",
"id": 47216475,
"login": "prikmm",
"node_id": "MDQ6VXNlcjQ3MjE2NDc1",
"organizations_url": "https://api.github.com/users/prikmm/orgs",
"received_events_url": "https://api.github.com/users/prikmm/received_events",
"repos_url": "https://api.github.com/users/prikmm/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/prikmm/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/prikmm/subscriptions",
"type": "User",
"url": "https://api.github.com/users/prikmm",
"user_view_type": "public"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"This looks like an issue with PyArrow. Did you try reinstalling it ?",
"@lhoestq I did, and then let pip handle the installation in `pip import datasets`. I also tried using conda but it gives the same error.\r\n\r\nEdit: pyarrow version on kaggle is 4.0.0, it gets replaced with 4.0.1. So, I don't think uninstal... | 2021-07-20T09:28:38Z | 2021-07-21T13:59:26Z | 2021-07-21T13:03:02Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ## Describe the bug
Not able to import datasets library in kaggle notebooks
## Steps to reproduce the bug
```python
!pip install datasets
import datasets
```
## Expected results
No such error
## Actual results
```
ImportError Traceback (most recent call last)
<ipython-input-9-652e886d387f> in <module>
----> 1 import datasets
/opt/conda/lib/python3.7/site-packages/datasets/__init__.py in <module>
31 )
32
---> 33 from .arrow_dataset import Dataset, concatenate_datasets
34 from .arrow_reader import ArrowReader, ReadInstruction
35 from .arrow_writer import ArrowWriter
/opt/conda/lib/python3.7/site-packages/datasets/arrow_dataset.py in <module>
36 import pandas as pd
37 import pyarrow as pa
---> 38 import pyarrow.compute as pc
39 from multiprocess import Pool, RLock
40 from tqdm.auto import tqdm
/opt/conda/lib/python3.7/site-packages/pyarrow/compute.py in <module>
16 # under the License.
17
---> 18 from pyarrow._compute import ( # noqa
19 Function,
20 FunctionOptions,
ImportError: /opt/conda/lib/python3.7/site-packages/pyarrow/_compute.cpython-37m-x86_64-linux-gnu.so: undefined symbol: _ZNK5arrow7compute15KernelSignature8ToStringEv
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.9.0
- Platform: Kaggle
- Python version: 3.7.10
- PyArrow version: 4.0.1
| {
"avatar_url": "https://avatars.githubusercontent.com/u/47216475?v=4",
"events_url": "https://api.github.com/users/prikmm/events{/privacy}",
"followers_url": "https://api.github.com/users/prikmm/followers",
"following_url": "https://api.github.com/users/prikmm/following{/other_user}",
"gists_url": "https://api.github.com/users/prikmm/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/prikmm",
"id": 47216475,
"login": "prikmm",
"node_id": "MDQ6VXNlcjQ3MjE2NDc1",
"organizations_url": "https://api.github.com/users/prikmm/orgs",
"received_events_url": "https://api.github.com/users/prikmm/received_events",
"repos_url": "https://api.github.com/users/prikmm/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/prikmm/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/prikmm/subscriptions",
"type": "User",
"url": "https://api.github.com/users/prikmm",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2678/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2678/timeline | null | completed | null | null | 27.573333 | 4,895 |
https://api.github.com/repos/huggingface/datasets/issues/2677 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2677/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2677/comments | https://api.github.com/repos/huggingface/datasets/issues/2677/events | https://github.com/huggingface/datasets/issues/2677 | 948,429,788 | MDU6SXNzdWU5NDg0Mjk3ODg= | 2,677 | Error when downloading C4 | {
"avatar_url": "https://avatars.githubusercontent.com/u/36672861?v=4",
"events_url": "https://api.github.com/users/Aktsvigun/events{/privacy}",
"followers_url": "https://api.github.com/users/Aktsvigun/followers",
"following_url": "https://api.github.com/users/Aktsvigun/following{/other_user}",
"gists_url": "https://api.github.com/users/Aktsvigun/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Aktsvigun",
"id": 36672861,
"login": "Aktsvigun",
"node_id": "MDQ6VXNlcjM2NjcyODYx",
"organizations_url": "https://api.github.com/users/Aktsvigun/orgs",
"received_events_url": "https://api.github.com/users/Aktsvigun/received_events",
"repos_url": "https://api.github.com/users/Aktsvigun/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Aktsvigun/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Aktsvigun/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Aktsvigun",
"user_view_type": "public"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists... | null | [
"Hi Thanks for reporting !\r\nIt looks like these files are not correctly reported in the list of expected files to download, let me fix that ;)",
"Alright this is fixed now. We'll do a new release soon to make the fix available.\r\n\r\nIn the meantime feel free to simply pass `ignore_verifications=True` to `load... | 2021-07-20T08:37:30Z | 2021-07-20T14:41:31Z | 2021-07-20T14:38:10Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | Hi,
I am trying to download `en` corpus from C4 dataset. However, I get an error caused by validation files download (see image). My code is very primitive:
`datasets.load_dataset('c4', 'en')`
Is this a bug or do I have some configurations missing on my server?
Thanks!
<img width="1014" alt="Снимок экрана 2021-07-20 в 11 37 17" src="https://user-images.githubusercontent.com/36672861/126289448-6e0db402-5f3f-485a-bf74-eb6e0271fc25.png"> | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2677/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2677/timeline | null | completed | null | null | 6.011111 | 4,896 |
https://api.github.com/repos/huggingface/datasets/issues/2669 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2669/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2669/comments | https://api.github.com/repos/huggingface/datasets/issues/2669/events | https://github.com/huggingface/datasets/issues/2669 | 946,982,998 | MDU6SXNzdWU5NDY5ODI5OTg= | 2,669 | Metric kwargs are not passed to underlying external metric f1_score | {
"avatar_url": "https://avatars.githubusercontent.com/u/2779410?v=4",
"events_url": "https://api.github.com/users/BramVanroy/events{/privacy}",
"followers_url": "https://api.github.com/users/BramVanroy/followers",
"following_url": "https://api.github.com/users/BramVanroy/following{/other_user}",
"gists_url": "https://api.github.com/users/BramVanroy/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/BramVanroy",
"id": 2779410,
"login": "BramVanroy",
"node_id": "MDQ6VXNlcjI3Nzk0MTA=",
"organizations_url": "https://api.github.com/users/BramVanroy/orgs",
"received_events_url": "https://api.github.com/users/BramVanroy/received_events",
"repos_url": "https://api.github.com/users/BramVanroy/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/BramVanroy/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/BramVanroy/subscriptions",
"type": "User",
"url": "https://api.github.com/users/BramVanroy",
"user_view_type": "public"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [
"Hi @BramVanroy, thanks for reporting.\r\n\r\nFirst, note that `\"min\"` is not an allowed value for `average`. According to scikit-learn [documentation](https://scikit-learn.org/stable/modules/generated/sklearn.metrics.f1_score.html), `average` can only take the values: `{\"micro\", \"macro\", \"samples\", \"weigh... | 2021-07-18T08:32:31Z | 2021-07-18T18:36:05Z | 2021-07-18T11:19:04Z | CONTRIBUTOR | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ## Describe the bug
When I want to use F1 score with average="min", this keyword argument does not seem to be passed through to the underlying sklearn metric. This is evident because [sklearn](https://scikit-learn.org/stable/modules/generated/sklearn.metrics.f1_score.html) throws an error telling me so.
## Steps to reproduce the bug
```python
import datasets
f1 = datasets.load_metric("f1", keep_in_memory=True, average="min")
f1.add_batch(predictions=[0,2,3], references=[1, 2, 3])
f1.compute()
```
## Expected results
No error, because `average="min"` should be passed correctly to f1_score in sklearn.
## Actual results
```
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "C:\Users\bramv\.virtualenvs\pipeline-TpEsXVex\lib\site-packages\datasets\metric.py", line 402, in compute
output = self._compute(predictions=predictions, references=references, **kwargs)
File "C:\Users\bramv\.cache\huggingface\modules\datasets_modules\metrics\f1\82177930a325d4c28342bba0f116d73f6d92fb0c44cd67be32a07c1262b61cfe\f1.py", line 97, in _compute
"f1": f1_score(
File "C:\Users\bramv\.virtualenvs\pipeline-TpEsXVex\lib\site-packages\sklearn\utils\validation.py", line 63, in inner_f
return f(*args, **kwargs)
File "C:\Users\bramv\.virtualenvs\pipeline-TpEsXVex\lib\site-packages\sklearn\metrics\_classification.py", line 1071, in f1_score
return fbeta_score(y_true, y_pred, beta=1, labels=labels,
File "C:\Users\bramv\.virtualenvs\pipeline-TpEsXVex\lib\site-packages\sklearn\utils\validation.py", line 63, in inner_f
return f(*args, **kwargs)
File "C:\Users\bramv\.virtualenvs\pipeline-TpEsXVex\lib\site-packages\sklearn\metrics\_classification.py", line 1195, in fbeta_score
_, _, f, _ = precision_recall_fscore_support(y_true, y_pred,
File "C:\Users\bramv\.virtualenvs\pipeline-TpEsXVex\lib\site-packages\sklearn\utils\validation.py", line 63, in inner_f
return f(*args, **kwargs)
File "C:\Users\bramv\.virtualenvs\pipeline-TpEsXVex\lib\site-packages\sklearn\metrics\_classification.py", line 1464, in precision_recall_fscore_support
labels = _check_set_wise_labels(y_true, y_pred, average, labels,
File "C:\Users\bramv\.virtualenvs\pipeline-TpEsXVex\lib\site-packages\sklearn\metrics\_classification.py", line 1294, in _check_set_wise_labels
raise ValueError("Target is %s but average='binary'. Please "
ValueError: Target is multiclass but average='binary'. Please choose another average setting, one of [None, 'micro', 'macro', 'weighted'].
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.9.0
- Platform: Windows-10-10.0.19041-SP0
- Python version: 3.9.2
- PyArrow version: 4.0.1 | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2669/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2669/timeline | null | completed | null | null | 2.775833 | 4,904 |
https://api.github.com/repos/huggingface/datasets/issues/2663 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2663/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2663/comments | https://api.github.com/repos/huggingface/datasets/issues/2663/events | https://github.com/huggingface/datasets/issues/2663 | 946,552,273 | MDU6SXNzdWU5NDY1NTIyNzM= | 2,663 | [`to_json`] add multi-proc sharding support | {
"avatar_url": "https://avatars.githubusercontent.com/u/10676103?v=4",
"events_url": "https://api.github.com/users/stas00/events{/privacy}",
"followers_url": "https://api.github.com/users/stas00/followers",
"following_url": "https://api.github.com/users/stas00/following{/other_user}",
"gists_url": "https://api.github.com/users/stas00/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/stas00",
"id": 10676103,
"login": "stas00",
"node_id": "MDQ6VXNlcjEwNjc2MTAz",
"organizations_url": "https://api.github.com/users/stas00/orgs",
"received_events_url": "https://api.github.com/users/stas00/received_events",
"repos_url": "https://api.github.com/users/stas00/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/stas00/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stas00/subscriptions",
"type": "User",
"url": "https://api.github.com/users/stas00",
"user_view_type": "public"
} | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | null | [] | null | [
"Hi @stas00, \r\nI want to work on this issue and I was thinking why don't we use `imap` [in this loop](https://github.com/huggingface/datasets/blob/440b14d0dd428ae1b25881aa72ba7bbb8ad9ff84/src/datasets/io/json.py#L99)? This way, using offset (which is being used to slice the pyarrow table) we can convert pyarrow ... | 2021-07-16T19:41:50Z | 2021-09-13T13:56:37Z | 2021-09-13T13:56:37Z | CONTRIBUTOR | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | As discussed on slack it appears that `to_json` is quite slow on huge datasets like OSCAR.
I implemented sharded saving, which is much much faster - but the tqdm bars all overwrite each other, so it's hard to make sense of the progress, so if possible ideally this multi-proc support could be implemented internally in `to_json` via `num_proc` argument. I guess `num_proc` will be the number of shards?
I think the user will need to use this feature wisely, since too many processes writing to say normal style HD is likely to be slower than one process.
I'm not sure whether the user should be responsible to concatenate the shards at the end or `datasets`, either way works for my needs.
The code I was using:
```
from multiprocessing import cpu_count, Process, Queue
[...]
filtered_dataset = concat_dataset.map(filter_short_documents, batched=True, batch_size=256, num_proc=cpu_count())
DATASET_NAME = "oscar"
SHARDS = 10
def process_shard(idx):
print(f"Sharding {idx}")
ds_shard = filtered_dataset.shard(SHARDS, idx, contiguous=True)
# ds_shard = ds_shard.shuffle() # remove contiguous=True above if shuffling
print(f"Saving {DATASET_NAME}-{idx}.jsonl")
ds_shard.to_json(f"{DATASET_NAME}-{idx}.jsonl", orient="records", lines=True, force_ascii=False)
queue = Queue()
processes = [Process(target=process_shard, args=(idx,)) for idx in range(SHARDS)]
for p in processes:
p.start()
for p in processes:
p.join()
```
Thank you!
@lhoestq | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2663/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2663/timeline | null | completed | null | null | 1,410.246389 | 4,909 |
https://api.github.com/repos/huggingface/datasets/issues/2658 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2658/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2658/comments | https://api.github.com/repos/huggingface/datasets/issues/2658/events | https://github.com/huggingface/datasets/issues/2658 | 946,139,532 | MDU6SXNzdWU5NDYxMzk1MzI= | 2,658 | Can't pass `sep=None` to load_dataset("csv", ...) to infer the separator via pandas.read_csv | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
} | [] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists... | null | [] | 2021-07-16T10:05:44Z | 2021-07-16T12:46:06Z | 2021-07-16T12:46:06Z | MEMBER | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | When doing `load_dataset("csv", sep=None)`, the `sep` passed to `pd.read_csv` is still the default `sep=","` instead, which makes it impossible to make the csv loader infer the separator.
Related to https://github.com/huggingface/datasets/pull/2656
cc @SBrandeis | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq",
"user_view_type": "public"
} | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2658/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2658/timeline | null | completed | null | null | 2.672778 | 4,914 |
https://api.github.com/repos/huggingface/datasets/issues/2655 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2655/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2655/comments | https://api.github.com/repos/huggingface/datasets/issues/2655/events | https://github.com/huggingface/datasets/issues/2655 | 945,382,723 | MDU6SXNzdWU5NDUzODI3MjM= | 2,655 | Allow the selection of multiple columns at once | {
"avatar_url": "https://avatars.githubusercontent.com/u/8976546?v=4",
"events_url": "https://api.github.com/users/Dref360/events{/privacy}",
"followers_url": "https://api.github.com/users/Dref360/followers",
"following_url": "https://api.github.com/users/Dref360/following{/other_user}",
"gists_url": "https://api.github.com/users/Dref360/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Dref360",
"id": 8976546,
"login": "Dref360",
"node_id": "MDQ6VXNlcjg5NzY1NDY=",
"organizations_url": "https://api.github.com/users/Dref360/orgs",
"received_events_url": "https://api.github.com/users/Dref360/received_events",
"repos_url": "https://api.github.com/users/Dref360/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Dref360/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Dref360/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Dref360",
"user_view_type": "public"
} | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | null | [] | null | [
"Hi! I was looking into this and hope you can clarify a point. Your my_dataset variable would be of type DatasetDict which means the alternative you've described (dict comprehension) is what makes sense. \r\nIs there a reason why you wouldn't want to convert my_dataset to a pandas df if you'd like to use it like on... | 2021-07-15T13:30:45Z | 2024-01-09T15:11:27Z | 2024-01-09T07:46:28Z | CONTRIBUTOR | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | **Is your feature request related to a problem? Please describe.**
Similar to pandas, it would be great if we could select multiple columns at once.
**Describe the solution you'd like**
```python
my_dataset = ... # Has columns ['idx', 'sentence', 'label']
idx, label = my_dataset[['idx', 'label']]
```
**Describe alternatives you've considered**
we can do `[dataset[col] for col in ('idx', 'label')]`
**Additional context**
This is of course very minor.
| {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | {
"+1": 8,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 8,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2655/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2655/timeline | null | completed | null | null | 21,786.261944 | 4,917 |
https://api.github.com/repos/huggingface/datasets/issues/2653 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2653/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2653/comments | https://api.github.com/repos/huggingface/datasets/issues/2653/events | https://github.com/huggingface/datasets/issues/2653 | 945,102,321 | MDU6SXNzdWU5NDUxMDIzMjE= | 2,653 | Add SD task for SUPERB | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | {
"closed_at": "2021-09-02T05:34:03Z",
"closed_issues": 2,
"created_at": "2021-07-09T05:49:00Z",
"creator": {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
},
"description": "Next minor release",
"due_on": "2021-07-30T07:00:00Z",
"html_url": "https://github.com/huggingface/datasets/milestone/7",
"id": 6931350,
"labels_url": "https://api.github.com/repos/huggingface/datasets/milestones/7/labels",
"node_id": "MDk6TWlsZXN0b25lNjkzMTM1MA==",
"number": 7,
"open_issues": 0,
"state": "closed",
"title": "1.11",
"updated_at": "2021-09-02T05:34:03Z",
"url": "https://api.github.com/repos/huggingface/datasets/milestones/7"
} | [
"Note that this subset requires us to:\r\n\r\n* generate the LibriMix corpus from LibriSpeech\r\n* prepare the corpus for diarization\r\n\r\nAs suggested by @lhoestq we should perform these steps locally and add the prepared data to this public repo on the Hub: https://huggingface.co/datasets/superb/superb-data\r\n... | 2021-07-15T07:51:40Z | 2021-08-04T17:03:52Z | 2021-08-04T17:03:52Z | MEMBER | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | Include the SD (Speaker Diarization) task as described in the [SUPERB paper](https://arxiv.org/abs/2105.01051) and `s3prl` [instructions](https://github.com/s3prl/s3prl/tree/master/s3prl/downstream#sd-speaker-diarization).
Steps:
- [x] Generate the LibriMix corpus
- [x] Prepare the corpus for diarization
- [x] Upload these files to the superb-data repo
- [x] Transcribe the corresponding s3prl processing of these files into our superb loading script
- [ ] README: tags + description sections
Related to #2619.
cc: @lewtun
| {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2653/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2653/timeline | null | completed | null | null | 489.203333 | 4,919 |
https://api.github.com/repos/huggingface/datasets/issues/2651 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2651/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2651/comments | https://api.github.com/repos/huggingface/datasets/issues/2651/events | https://github.com/huggingface/datasets/issues/2651 | 944,796,961 | MDU6SXNzdWU5NDQ3OTY5NjE= | 2,651 | Setting log level higher than warning does not suppress progress bar | {
"avatar_url": "https://avatars.githubusercontent.com/u/1147443?v=4",
"events_url": "https://api.github.com/users/Isa-rentacs/events{/privacy}",
"followers_url": "https://api.github.com/users/Isa-rentacs/followers",
"following_url": "https://api.github.com/users/Isa-rentacs/following{/other_user}",
"gists_url": "https://api.github.com/users/Isa-rentacs/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Isa-rentacs",
"id": 1147443,
"login": "Isa-rentacs",
"node_id": "MDQ6VXNlcjExNDc0NDM=",
"organizations_url": "https://api.github.com/users/Isa-rentacs/orgs",
"received_events_url": "https://api.github.com/users/Isa-rentacs/received_events",
"repos_url": "https://api.github.com/users/Isa-rentacs/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Isa-rentacs/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Isa-rentacs/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Isa-rentacs",
"user_view_type": "public"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"Hi,\r\n\r\nyou can suppress progress bars by patching logging as follows:\r\n```python\r\nimport datasets\r\nimport logging\r\ndatasets.logging.get_verbosity = lambda: logging.NOTSET\r\n# map call ...\r\n```\r\nEDIT: now you have to use `disable_progress_bar `",
"Thank you, it worked :)",
"See https://github.c... | 2021-07-14T21:06:51Z | 2022-07-08T14:51:57Z | 2021-07-15T03:41:35Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ## Describe the bug
I would like to disable progress bars for `.map` method (and other methods like `.filter` and `load_dataset` as well).
According to #1627 one can suppress it by setting log level higher than `warning`, however doing so doesn't suppress it with version 1.9.0.
I also tried to set `DATASETS_VERBOSITY` environment variable to `error` or `critical` but it also didn't work.
## Steps to reproduce the bug
```python
import datasets
from datasets.utils.logging import set_verbosity_error
set_verbosity_error()
def dummy_map(batch):
return batch
common_voice_train = datasets.load_dataset("common_voice", "de", split="train")
common_voice_test = datasets.load_dataset("common_voice", "de", split="test")
common_voice_train.map(dummy_map)
```
## Expected results
- The progress bar for `.map` call won't be shown
## Actual results
- The progress bar for `.map` is still shown
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.9.0
- Platform: Linux-5.4.0-1045-aws-x86_64-with-Ubuntu-18.04-bionic
- Python version: 3.7.5
- PyArrow version: 4.0.1
| {
"avatar_url": "https://avatars.githubusercontent.com/u/1147443?v=4",
"events_url": "https://api.github.com/users/Isa-rentacs/events{/privacy}",
"followers_url": "https://api.github.com/users/Isa-rentacs/followers",
"following_url": "https://api.github.com/users/Isa-rentacs/following{/other_user}",
"gists_url": "https://api.github.com/users/Isa-rentacs/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/Isa-rentacs",
"id": 1147443,
"login": "Isa-rentacs",
"node_id": "MDQ6VXNlcjExNDc0NDM=",
"organizations_url": "https://api.github.com/users/Isa-rentacs/orgs",
"received_events_url": "https://api.github.com/users/Isa-rentacs/received_events",
"repos_url": "https://api.github.com/users/Isa-rentacs/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/Isa-rentacs/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Isa-rentacs/subscriptions",
"type": "User",
"url": "https://api.github.com/users/Isa-rentacs",
"user_view_type": "public"
} | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2651/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2651/timeline | null | completed | null | null | 6.578889 | 4,921 |
https://api.github.com/repos/huggingface/datasets/issues/2650 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2650/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2650/comments | https://api.github.com/repos/huggingface/datasets/issues/2650/events | https://github.com/huggingface/datasets/issues/2650 | 944,672,565 | MDU6SXNzdWU5NDQ2NzI1NjU= | 2,650 | [load_dataset] shard and parallelize the process | {
"avatar_url": "https://avatars.githubusercontent.com/u/10676103?v=4",
"events_url": "https://api.github.com/users/stas00/events{/privacy}",
"followers_url": "https://api.github.com/users/stas00/followers",
"following_url": "https://api.github.com/users/stas00/following{/other_user}",
"gists_url": "https://api.github.com/users/stas00/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/stas00",
"id": 10676103,
"login": "stas00",
"node_id": "MDQ6VXNlcjEwNjc2MTAz",
"organizations_url": "https://api.github.com/users/stas00/orgs",
"received_events_url": "https://api.github.com/users/stas00/received_events",
"repos_url": "https://api.github.com/users/stas00/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/stas00/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stas00/subscriptions",
"type": "User",
"url": "https://api.github.com/users/stas00",
"user_view_type": "public"
} | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/26709476?v=4",
"events_url": "https://api.github.com/users/TevenLeScao/events{/privacy}",
"followers_url": "https://api.github.com/users/TevenLeScao/followers",
"following_url": "https://api.github.com/users/TevenLeScao/following{/other_user}",
"gists_url": "https://api.github.com/users/TevenLeScao/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/TevenLeScao",
"id": 26709476,
"login": "TevenLeScao",
"node_id": "MDQ6VXNlcjI2NzA5NDc2",
"organizations_url": "https://api.github.com/users/TevenLeScao/orgs",
"received_events_url": "https://api.github.com/users/TevenLeScao/received_events",
"repos_url": "https://api.github.com/users/TevenLeScao/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/TevenLeScao/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/TevenLeScao/subscriptions",
"type": "User",
"url": "https://api.github.com/users/TevenLeScao",
"user_view_type": "public"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/26709476?v=4",
"events_url": "https://api.github.com/users/TevenLeScao/events{/privacy}",
"followers_url": "https://api.github.com/users/TevenLeScao/followers",
"following_url": "https://api.github.com/users/TevenLeScao/following{/other_user}"... | null | [
"I need the same feature for distributed training",
"I think @TevenLeScao is exploring adding multiprocessing in `GeneratorBasedBuilder._prepare_split` - feel free to post updates here :)",
"Posted a PR to address the building side, still needs something to load sharded arrow files + tests",
"Closing as this ... | 2021-07-14T18:04:58Z | 2023-11-28T19:11:41Z | 2023-11-28T19:11:40Z | CONTRIBUTOR | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | - Some huge datasets take forever to build the first time. (e.g. oscar/en) as it's done in a single cpu core.
- If the build crashes, everything done up to that point gets lost
Request: Shard the build over multiple arrow files, which would enable:
- much faster build by parallelizing the build process
- if the process crashed, the completed arrow files don't need to be re-built again
Thank you!
@lhoestq | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
} | {
"+1": 5,
"-1": 0,
"confused": 0,
"eyes": 3,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 2,
"total_count": 10,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2650/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2650/timeline | null | completed | null | null | 20,809.111667 | 4,922 |
https://api.github.com/repos/huggingface/datasets/issues/2646 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2646/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2646/comments | https://api.github.com/repos/huggingface/datasets/issues/2646/events | https://github.com/huggingface/datasets/issues/2646 | 944,379,954 | MDU6SXNzdWU5NDQzNzk5NTQ= | 2,646 | downloading of yahoo_answers_topics dataset failed | {
"avatar_url": "https://avatars.githubusercontent.com/u/66781249?v=4",
"events_url": "https://api.github.com/users/vikrant7k/events{/privacy}",
"followers_url": "https://api.github.com/users/vikrant7k/followers",
"following_url": "https://api.github.com/users/vikrant7k/following{/other_user}",
"gists_url": "https://api.github.com/users/vikrant7k/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/vikrant7k",
"id": 66781249,
"login": "vikrant7k",
"node_id": "MDQ6VXNlcjY2NzgxMjQ5",
"organizations_url": "https://api.github.com/users/vikrant7k/orgs",
"received_events_url": "https://api.github.com/users/vikrant7k/received_events",
"repos_url": "https://api.github.com/users/vikrant7k/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/vikrant7k/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/vikrant7k/subscriptions",
"type": "User",
"url": "https://api.github.com/users/vikrant7k",
"user_view_type": "public"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"Hi ! I just tested and it worked fine today for me.\r\n\r\nI think this is because the dataset is stored on Google Drive which has a quota limit for the number of downloads per day, see this similar issue https://github.com/huggingface/datasets/issues/996 \r\n\r\nFeel free to try again today, now that the quota wa... | 2021-07-14T12:31:05Z | 2022-08-04T08:28:24Z | 2022-08-04T08:28:24Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ## Describe the bug
I get an error datasets.utils.info_utils.NonMatchingChecksumError: Checksums didn't match for dataset source files when I try to download the yahoo_answers_topics dataset
## Steps to reproduce the bug
self.dataset = load_dataset(
'yahoo_answers_topics', cache_dir=self.config['yahoo_cache_dir'], split='train[:90%]')
# Sample code to reproduce the bug
self.dataset = load_dataset(
'yahoo_answers_topics', cache_dir=self.config['yahoo_cache_dir'], split='train[:90%]')
## Expected results
A clear and concise description of the expected results.
## Actual results
Specify the actual results or traceback.
datasets.utils.info_utils.NonMatchingChecksumError: Checksums didn't match for dataset source files
| {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2646/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2646/timeline | null | completed | null | null | 9,259.955278 | 4,926 |
https://api.github.com/repos/huggingface/datasets/issues/2645 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2645/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2645/comments | https://api.github.com/repos/huggingface/datasets/issues/2645/events | https://github.com/huggingface/datasets/issues/2645 | 944,374,284 | MDU6SXNzdWU5NDQzNzQyODQ= | 2,645 | load_dataset processing failed with OS error after downloading a dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/40395156?v=4",
"events_url": "https://api.github.com/users/fake-warrior8/events{/privacy}",
"followers_url": "https://api.github.com/users/fake-warrior8/followers",
"following_url": "https://api.github.com/users/fake-warrior8/following{/other_user}",
"gists_url": "https://api.github.com/users/fake-warrior8/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/fake-warrior8",
"id": 40395156,
"login": "fake-warrior8",
"node_id": "MDQ6VXNlcjQwMzk1MTU2",
"organizations_url": "https://api.github.com/users/fake-warrior8/orgs",
"received_events_url": "https://api.github.com/users/fake-warrior8/received_events",
"repos_url": "https://api.github.com/users/fake-warrior8/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/fake-warrior8/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/fake-warrior8/subscriptions",
"type": "User",
"url": "https://api.github.com/users/fake-warrior8",
"user_view_type": "public"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"Hi ! It looks like an issue with pytorch.\r\n\r\nCould you try to run `import torch` and see if it raises an error ?",
"> Hi ! It looks like an issue with pytorch.\r\n> \r\n> Could you try to run `import torch` and see if it raises an error ?\r\n\r\nIt works. Thank you!"
] | 2021-07-14T12:23:53Z | 2021-07-15T09:34:02Z | 2021-07-15T09:34:02Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ## Describe the bug
After downloading a dataset like opus100, there is a bug that
OSError: Cannot find data file.
Original error:
dlopen: cannot load any more object with static TLS
## Steps to reproduce the bug
```python
from datasets import load_dataset
this_dataset = load_dataset('opus100', 'af-en')
```
## Expected results
there is no error when running load_dataset.
## Actual results
Specify the actual results or traceback.
Traceback (most recent call last):
File "/home/anaconda3/lib/python3.6/site-packages/datasets/builder.py", line 652, in _download_and_prep
self._prepare_split(split_generator, **prepare_split_kwargs)
File "/home/anaconda3/lib/python3.6/site-packages/datasets/builder.py", line 989, in _prepare_split
example = self.info.features.encode_example(record)
File "/home/anaconda3/lib/python3.6/site-packages/datasets/features.py", line 952, in encode_example
example = cast_to_python_objects(example)
File "/home/anaconda3/lib/python3.6/site-packages/datasets/features.py", line 219, in cast_to_python_ob
return _cast_to_python_objects(obj)[0]
File "/home/anaconda3/lib/python3.6/site-packages/datasets/features.py", line 165, in _cast_to_python_o
import torch
File "/home/anaconda3/lib/python3.6/site-packages/torch/__init__.py", line 188, in <module>
_load_global_deps()
File "/home/anaconda3/lib/python3.6/site-packages/torch/__init__.py", line 141, in _load_global_deps
ctypes.CDLL(lib_path, mode=ctypes.RTLD_GLOBAL)
File "/home/anaconda3/lib/python3.6/ctypes/__init__.py", line 348, in __init__
self._handle = _dlopen(self._name, mode)
OSError: dlopen: cannot load any more object with static TLS
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "download_hub_opus100.py", line 9, in <module>
this_dataset = load_dataset('opus100', language_pair)
File "/home/anaconda3/lib/python3.6/site-packages/datasets/load.py", line 748, in load_dataset
use_auth_token=use_auth_token,
File "/home/anaconda3/lib/python3.6/site-packages/datasets/builder.py", line 575, in download_and_prepa
dl_manager=dl_manager, verify_infos=verify_infos, **download_and_prepare_kwargs
File "/home/anaconda3/lib/python3.6/site-packages/datasets/builder.py", line 658, in _download_and_prep
+ str(e)
OSError: Cannot find data file.
Original error:
dlopen: cannot load any more object with static TLS
## Environment info
- `datasets` version: 1.8.0
- Platform: Linux-3.13.0-32-generic-x86_64-with-debian-jessie-sid
- Python version: 3.6.6
- PyArrow version: 3.0.0
| {
"avatar_url": "https://avatars.githubusercontent.com/u/40395156?v=4",
"events_url": "https://api.github.com/users/fake-warrior8/events{/privacy}",
"followers_url": "https://api.github.com/users/fake-warrior8/followers",
"following_url": "https://api.github.com/users/fake-warrior8/following{/other_user}",
"gists_url": "https://api.github.com/users/fake-warrior8/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/fake-warrior8",
"id": 40395156,
"login": "fake-warrior8",
"node_id": "MDQ6VXNlcjQwMzk1MTU2",
"organizations_url": "https://api.github.com/users/fake-warrior8/orgs",
"received_events_url": "https://api.github.com/users/fake-warrior8/received_events",
"repos_url": "https://api.github.com/users/fake-warrior8/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/fake-warrior8/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/fake-warrior8/subscriptions",
"type": "User",
"url": "https://api.github.com/users/fake-warrior8",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2645/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2645/timeline | null | completed | null | null | 21.169167 | 4,927 |
https://api.github.com/repos/huggingface/datasets/issues/2644 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2644/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2644/comments | https://api.github.com/repos/huggingface/datasets/issues/2644/events | https://github.com/huggingface/datasets/issues/2644 | 944,254,748 | MDU6SXNzdWU5NDQyNTQ3NDg= | 2,644 | Batched `map` not allowed to return 0 items | {
"avatar_url": "https://avatars.githubusercontent.com/u/1177582?v=4",
"events_url": "https://api.github.com/users/pcuenca/events{/privacy}",
"followers_url": "https://api.github.com/users/pcuenca/followers",
"following_url": "https://api.github.com/users/pcuenca/following{/other_user}",
"gists_url": "https://api.github.com/users/pcuenca/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/pcuenca",
"id": 1177582,
"login": "pcuenca",
"node_id": "MDQ6VXNlcjExNzc1ODI=",
"organizations_url": "https://api.github.com/users/pcuenca/orgs",
"received_events_url": "https://api.github.com/users/pcuenca/received_events",
"repos_url": "https://api.github.com/users/pcuenca/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/pcuenca/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/pcuenca/subscriptions",
"type": "User",
"url": "https://api.github.com/users/pcuenca",
"user_view_type": "public"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"Hi ! Thanks for reporting. Indeed it looks like type inference makes it fail. We should probably just ignore this step until a non-empty batch is passed.",
"Sounds good! Do you want me to propose a PR? I'm quite busy right now, but if it's not too urgent I could take a look next week.",
"Sure if you're interes... | 2021-07-14T09:58:19Z | 2021-07-26T14:55:15Z | 2021-07-26T14:55:15Z | MEMBER | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ## Describe the bug
I'm trying to use `map` to filter a large dataset by selecting rows that match an expensive condition (files referenced by one of the columns need to exist in the filesystem, so we have to `stat` them). According to [the documentation](https://huggingface.co/docs/datasets/processing.html#augmenting-the-dataset), `a batch mapped function can take as input a batch of size N and return a batch of size M where M can be greater or less than N and can even be zero`.
However, when the returned batch has a size of zero (neither item in the batch fulfilled the condition), we get an `index out of bounds` error. I think that `arrow_writer.py` is [trying to infer the returned types using the first element returned](https://github.com/huggingface/datasets/blob/master/src/datasets/arrow_writer.py#L100), but no elements were returned in this case.
For this error to happen, I'm returning a dictionary that contains empty lists for the keys I want to keep, see below. If I return an empty dictionary instead (no keys), then a different error eventually occurs.
## Steps to reproduce the bug
```python
def select_rows(examples):
# `key` is a column name that exists in the original dataset
# The following line simulates no matches found, so we return an empty batch
result = {'key': []}
return result
filtered_dataset = dataset.map(
select_rows,
remove_columns = dataset.column_names,
batched = True,
num_proc = 1,
desc = "Selecting rows with images that exist"
)
```
The code above immediately triggers the exception. If we use the following instead:
```python
def select_rows(examples):
# `key` is a column name that exists in the original dataset
result = {'key': []} # or defaultdict or whatever
# code to check for condition and append elements to result
# some_items_found will be set to True if there were any matching elements in the batch
return result if some_items_found else {}
```
Then it _seems_ to work, but it eventually fails with some sort of schema error. I believe it may happen when an empty batch is followed by a non-empty one, but haven't set up a test to verify it.
In my opinion, returning a dictionary with empty lists and valid column names should be accepted as a valid result with zero items.
## Expected results
The dataset would be filtered and only the matching fields would be returned.
## Actual results
An exception is encountered, as described. Using a workaround makes it fail further along the line.
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.9.1.dev0
- Platform: Linux-5.4.0-53-generic-x86_64-with-glibc2.17
- Python version: 3.8.10
- PyArrow version: 4.0.1
| {
"avatar_url": "https://avatars.githubusercontent.com/u/1177582?v=4",
"events_url": "https://api.github.com/users/pcuenca/events{/privacy}",
"followers_url": "https://api.github.com/users/pcuenca/followers",
"following_url": "https://api.github.com/users/pcuenca/following{/other_user}",
"gists_url": "https://api.github.com/users/pcuenca/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/pcuenca",
"id": 1177582,
"login": "pcuenca",
"node_id": "MDQ6VXNlcjExNzc1ODI=",
"organizations_url": "https://api.github.com/users/pcuenca/orgs",
"received_events_url": "https://api.github.com/users/pcuenca/received_events",
"repos_url": "https://api.github.com/users/pcuenca/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/pcuenca/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/pcuenca/subscriptions",
"type": "User",
"url": "https://api.github.com/users/pcuenca",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2644/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2644/timeline | null | completed | null | null | 292.948889 | 4,928 |
https://api.github.com/repos/huggingface/datasets/issues/2641 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2641/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2641/comments | https://api.github.com/repos/huggingface/datasets/issues/2641/events | https://github.com/huggingface/datasets/issues/2641 | 943,838,085 | MDU6SXNzdWU5NDM4MzgwODU= | 2,641 | load_dataset("financial_phrasebank") NonMatchingChecksumError | {
"avatar_url": "https://avatars.githubusercontent.com/u/13956255?v=4",
"events_url": "https://api.github.com/users/courtmckay/events{/privacy}",
"followers_url": "https://api.github.com/users/courtmckay/followers",
"following_url": "https://api.github.com/users/courtmckay/following{/other_user}",
"gists_url": "https://api.github.com/users/courtmckay/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/courtmckay",
"id": 13956255,
"login": "courtmckay",
"node_id": "MDQ6VXNlcjEzOTU2MjU1",
"organizations_url": "https://api.github.com/users/courtmckay/orgs",
"received_events_url": "https://api.github.com/users/courtmckay/received_events",
"repos_url": "https://api.github.com/users/courtmckay/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/courtmckay/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/courtmckay/subscriptions",
"type": "User",
"url": "https://api.github.com/users/courtmckay",
"user_view_type": "public"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"Hi! It's probably because this dataset is stored on google drive and it has a per day quota limit. It should work if you retry, I was able to initiate the download.\r\n\r\nSimilar issue [here](https://github.com/huggingface/datasets/issues/2646)",
"Hi ! Loading the dataset works on my side as well.\r\nFeel free ... | 2021-07-13T21:21:49Z | 2022-08-04T08:30:08Z | 2022-08-04T08:30:08Z | NONE | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ## Describe the bug
Attempting to download the financial_phrasebank dataset results in a NonMatchingChecksumError
## Steps to reproduce the bug
```python
from datasets import load_dataset
dataset = load_dataset("financial_phrasebank", 'sentences_allagree')
```
## Expected results
I expect to see the financial_phrasebank dataset downloaded successfully
## Actual results
NonMatchingChecksumError: Checksums didn't match for dataset source files:
['https://www.researchgate.net/profile/Pekka_Malo/publication/251231364_FinancialPhraseBank-v10/data/0c96051eee4fb1d56e000000/FinancialPhraseBank-v10.zip']
## Environment info
- `datasets` version: 1.9.0
- Platform: Linux-4.14.232-177.418.amzn2.x86_64-x86_64-with-debian-10.6
- Python version: 3.7.10
- PyArrow version: 4.0.1
| {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2641/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2641/timeline | null | completed | null | null | 9,275.138611 | 4,931 |
https://api.github.com/repos/huggingface/datasets/issues/2630 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2630/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2630/comments | https://api.github.com/repos/huggingface/datasets/issues/2630/events | https://github.com/huggingface/datasets/issues/2630 | 942,102,956 | MDU6SXNzdWU5NDIxMDI5NTY= | 2,630 | Progress bars are not properly rendered in Jupyter notebook | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova",
"user_view_type": "public"
} | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"To add my experience when trying to debug this issue:\r\n\r\nSeems like previously the workaround given [here](https://github.com/tqdm/tqdm/issues/485#issuecomment-473338308) worked around this issue. But with the latest version of jupyter/tqdm I still get terminal warnings that IPython tried to send a message fro... | 2021-07-12T14:07:13Z | 2022-02-03T15:55:33Z | 2022-02-03T15:55:33Z | MEMBER | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | ## Describe the bug
The progress bars are not Jupyter widgets; regular progress bars appear (like in a terminal).
## Steps to reproduce the bug
```python
ds.map(tokenize, num_proc=10)
```
## Expected results
Jupyter widgets displaying the progress bars.
## Actual results
Simple plane progress bars.
cc: Reported by @thomwolf | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariosasko",
"id": 47462742,
"login": "mariosasko",
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariosasko",
"user_view_type": "public"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2630/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2630/timeline | null | completed | null | null | 4,945.805556 | 4,941 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.