
title stringlengths 1 290 | body stringlengths 0 228k ⌀ | html_url stringlengths 46 51 | comments list | pull_request dict | number int64 1 5.59k | is_pull_request bool 2
classes |
|---|---|---|---|---|---|---|
Allow 'to_json' to run in unordered fashion in order to lower memory footprint | I'm using `to_json(..., num_proc=num_proc, compressiong='gzip')` with `num_proc>1`. I'm having an issue where things seem to deadlock at some point. Eventually I see OOM. I'm guessing it's an issue where one process starts to take a long time for a specific batch, and so other process keep accumulating their results in... | https://github.com/huggingface/datasets/pull/3650 | [
"Hi @thomasw21, I remember suggesting `imap_unordered` to @lhoestq at that time to speed up `to_json` further but after trying `pool_imap` on multiple datasets (>9GB) , memory utilisation was almost constant and we decided to go ahead with that only. \r\n\r\n1. Did you try this without `gzip`? Because `gzip` featu... | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3650",
"html_url": "https://github.com/huggingface/datasets/pull/3650",
"diff_url": "https://github.com/huggingface/datasets/pull/3650.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3650.patch",
"merged_at": null
} | 3,650 | true |
Add IGLUE dataset | ## Adding a Dataset
- **Name:** IGLUE
- **Description:** IGLUE brings together 4 vision-and-language tasks across 20 languages (Twitter [thread](https://twitter.com/ebugliarello/status/1487045497583976455?s=20&t=SB4LZGDhhkUW83ugcX_m5w))
- **Paper:** https://arxiv.org/abs/2201.11732
- **Data:** https://github.com/e-... | https://github.com/huggingface/datasets/issues/3649 | [] | null | 3,649 | false |
Fix Windows CI: bump python to 3.7 | Python>=3.7 is needed to install `tokenizers` 0.11 | https://github.com/huggingface/datasets/pull/3648 | [] | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3648",
"html_url": "https://github.com/huggingface/datasets/pull/3648",
"diff_url": "https://github.com/huggingface/datasets/pull/3648.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3648.patch",
"merged_at": "2022-01-28T14:40... | 3,648 | true |
Fix `add_column` on datasets with indices mapping | My initial idea was to avoid the `flatten_indices` call and reorder a new column instead, but in the end I decided to follow `concatenate_datasets` and use `flatten_indices` to avoid padding when `dataset._indices.num_rows != dataset._data.num_rows`.
Fix #3599 | https://github.com/huggingface/datasets/pull/3647 | [
"Sure, let's include this in today's release.",
"Cool ! The windows CI should be fixed on master now, feel free to merge :)"
] | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3647",
"html_url": "https://github.com/huggingface/datasets/pull/3647",
"diff_url": "https://github.com/huggingface/datasets/pull/3647.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3647.patch",
"merged_at": "2022-01-28T15:35... | 3,647 | true |
Fix streaming datasets that are not reset correctly | Streaming datasets that use `StreamingDownloadManager.iter_archive` and `StreamingDownloadManager.iter_files` had some issues. Indeed if you try to iterate over such dataset twice, then the second time it will be empty.
This is because the two methods above are generator functions. I fixed this by making them return... | https://github.com/huggingface/datasets/pull/3646 | [
"Works smoothly with the `transformers.Trainer` class now, thank you!"
] | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3646",
"html_url": "https://github.com/huggingface/datasets/pull/3646",
"diff_url": "https://github.com/huggingface/datasets/pull/3646.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3646.patch",
"merged_at": "2022-01-28T16:34... | 3,646 | true |
Streaming dataset based on dl_manager.iter_archive/iter_files are not reset correctly | Hi ! When iterating over a streaming dataset once, it's not reset correctly because of some issues with `dl_manager.iter_archive` and `dl_manager.iter_files`. Indeed they are generator functions (so the iterator that is returned can be exhausted). They should be iterables instead, and be reset if we do a for loop again... | https://github.com/huggingface/datasets/issues/3645 | [] | null | 3,645 | false |
Add a GROUP BY operator | **Is your feature request related to a problem? Please describe.**
Using batch mapping, we can easily split examples. However, we lack an appropriate option for merging them back together by some key. Consider this example:
```python
# features:
# {
# "example_id": datasets.Value("int32"),
# "text": datas... | https://github.com/huggingface/datasets/issues/3644 | [
"Hi ! At the moment you can use `to_pandas()` to get a pandas DataFrame that supports `group_by` operations (make sure your dataset fits in memory though)\r\n\r\nWe use Arrow as a back-end for `datasets` and it doesn't have native group by (see https://github.com/apache/arrow/issues/2189) unfortunately.\r\n\r\nI ju... | null | 3,644 | false |
Fix sem_eval_2018_task_1 download location | As discussed with @lhoestq in https://github.com/huggingface/datasets/issues/3549#issuecomment-1020176931_ this is the new pull request to fix the download location. | https://github.com/huggingface/datasets/pull/3643 | [
"I fixed those two things, the two remaining failing checks seem to be due to some dependency missing in the tests."
] | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3643",
"html_url": "https://github.com/huggingface/datasets/pull/3643",
"diff_url": "https://github.com/huggingface/datasets/pull/3643.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3643.patch",
"merged_at": "2022-02-04T15:15... | 3,643 | true |
Fix dataset slicing with negative bounds when indices mapping is not `None` | Fix #3611 | https://github.com/huggingface/datasets/pull/3642 | [] | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3642",
"html_url": "https://github.com/huggingface/datasets/pull/3642",
"diff_url": "https://github.com/huggingface/datasets/pull/3642.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3642.patch",
"merged_at": "2022-01-27T18:16... | 3,642 | true |
Fix numpy rngs when seed is None | Fixes the NumPy RNG when `seed` is `None`.
The problem becomes obvious after reading the NumPy notes on RNG (returned by `np.random.get_state()`):
> The MT19937 state vector consists of a 624-element array of 32-bit unsigned integers plus a single integer value between 0 and 624 that indexes the current position wi... | https://github.com/huggingface/datasets/pull/3641 | [] | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3641",
"html_url": "https://github.com/huggingface/datasets/pull/3641",
"diff_url": "https://github.com/huggingface/datasets/pull/3641.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3641.patch",
"merged_at": "2022-01-27T18:16... | 3,641 | true |
Issues with custom dataset in Wav2Vec2 | We are training Vav2Vec using the run_speech_recognition_ctc_bnb.py-script.
This is working fine with Common Voice, however using our custom dataset and data loader at [NbAiLab/NPSC]( https://huggingface.co/datasets/NbAiLab/NPSC) it crashes after roughly 1 epoch with the following stack trace:
:\r\n```\r\n- ... | null | 3,638 | false |
[TypeError: Couldn't cast array of type] Cannot load dataset in v1.18 | ## Describe the bug
I am trying to load the [`GEM/RiSAWOZ` dataset](https://huggingface.co/datasets/GEM/RiSAWOZ) in `datasets` v1.18.1 and am running into a type error when casting the features. The strange thing is that I can load the dataset with v1.17.0. Note that the error is also present if I install from `master... | https://github.com/huggingface/datasets/issues/3637 | [
"Hi @lewtun!\r\n \r\nThis one was tricky to debug. Initially, I tought there is a bug in the recently-added (by @lhoestq ) `cast_array_to_feature` function because `git bisect` points to the https://github.com/huggingface/datasets/commit/6ca96c707502e0689f9b58d94f46d871fa5a3c9c commit. Then, I noticed that the feat... | null | 3,637 | false |
Update index.rst | null | https://github.com/huggingface/datasets/pull/3636 | [] | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3636",
"html_url": "https://github.com/huggingface/datasets/pull/3636",
"diff_url": "https://github.com/huggingface/datasets/pull/3636.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3636.patch",
"merged_at": "2022-01-26T18:44... | 3,636 | true |
Make `ted_talks_iwslt` dataset streamable | null | https://github.com/huggingface/datasets/pull/3635 | [
"Thanks for adding this @mariosasko! It worked for me when running it with a local data file, however, when using the file on Google Drive I get the following error:\r\n```Python\r\nds = load_dataset(\"./ted_talks_iwslt\",\"eu_ca_2014\", streaming=True, split=\"train\", use_auth_token=True)\r\nnext(iter(ds))\r\n```... | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3635",
"html_url": "https://github.com/huggingface/datasets/pull/3635",
"diff_url": "https://github.com/huggingface/datasets/pull/3635.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3635.patch",
"merged_at": null
} | 3,635 | true |
Dataset.shuffle(seed=None) gives fixed row permutation | ## Describe the bug
Repeated attempts to `shuffle` a dataset without specifying a seed give the same results.
## Steps to reproduce the bug
```python
import datasets
# Some toy example
data = datasets.Dataset.from_dict(
{"feature": [1, 2, 3, 4, 5], "label": ["a", "b", "c", "d", "e"]}
)
# Doesn't work... | https://github.com/huggingface/datasets/issues/3634 | [
"I'm not sure if this is expected behavior.\r\n\r\nAm I supposed to work with a copy of the dataset, i.e. `shuffled_dataset = data.shuffle(seed=None)`?\r\n\r\n```diff\r\nimport datasets\r\n\r\n# Some toy example\r\ndata = datasets.Dataset.from_dict(\r\n {\"feature\": [1, 2, 3, 4, 5], \"label\": [\"a\", \"b\", \"... | null | 3,634 | false |
Mirror canonical datasets in prod | Push the datasets changes to the Hub in production by setting `HF_USE_PROD=1`
I also added a fix that makes the script ignore the json, csv, text, parquet and pandas dataset builders.
cc @SBrandeis | https://github.com/huggingface/datasets/pull/3633 | [] | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3633",
"html_url": "https://github.com/huggingface/datasets/pull/3633",
"diff_url": "https://github.com/huggingface/datasets/pull/3633.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3633.patch",
"merged_at": "2022-01-26T13:56... | 3,633 | true |
Adding CC-100: Monolingual Datasets from Web Crawl Data (Datasets links are invalid) | ## Describe the bug
The dataset links are no longer valid for CC-100. It seems that the website which was keeping these files are no longer accessible and therefore this dataset became unusable.
Check out the dataset [homepage](http://data.statmt.org/cc-100/) which isn't accessible.
Also the URLs for dataset file ... | https://github.com/huggingface/datasets/issues/3632 | [
"Hi @AnzorGozalishvili,\r\n\r\nMaybe their site was temporarily down, but it seems to work fine now.\r\n\r\nCould you please try again and confirm if the problem persists? ",
"Hi @albertvillanova \r\nI checked and it works. \r\nIt seems that it was really temporarily down.\r\nThanks!"
] | null | 3,632 | false |
Labels conflict when loading a local CSV file. | ## Describe the bug
I am trying to load a local CSV file with a separate file containing label names. It is successfully loaded for the first time, but when I try to load it again, there is a conflict between provided labels and the cached dataset info. Disabling caching globally and/or using `download_mode="force_red... | https://github.com/huggingface/datasets/issues/3631 | [
"Hi @pichljan, thanks for reporting.\r\n\r\nThis should be fixed. I'm looking at it. "
] | null | 3,631 | false |
DuplicatedKeysError of NewsQA dataset | After processing the dataset following official [NewsQA](https://github.com/Maluuba/newsqa), I used datasets to load it:
```
a = load_dataset('newsqa', data_dir='news')
```
and the following error occurred:
```
Using custom data configuration default-data_dir=news
Downloading and preparing dataset newsqa/defaul... | https://github.com/huggingface/datasets/issues/3630 | [
"Thanks for reporting, @StevenTang1998.\r\n\r\nI'm fixing it. "
] | null | 3,630 | false |
Fix Hub repos update when there's a new release | It was not listing the full list of datasets correctly
cc @SBrandeis this is why it failed for 1.18.0
We should be good now ! | https://github.com/huggingface/datasets/pull/3629 | [] | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3629",
"html_url": "https://github.com/huggingface/datasets/pull/3629",
"diff_url": "https://github.com/huggingface/datasets/pull/3629.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3629.patch",
"merged_at": "2022-01-25T14:55... | 3,629 | true |
Dataset Card Creator drops information for "Additional Information" Section | First of all, the card creator is a great addition and really helpful for streamlining dataset cards!
## Describe the bug
I encountered an inconvenient bug when entering "Additional Information" in the react app, which drops already entered text when switching to a previous section, and then back again to "Addition... | https://github.com/huggingface/datasets/issues/3628 | [] | null | 3,628 | false |
Fix host URL in The Pile datasets | This PR fixes the host URL in The Pile datasets, once they have mirrored their data in another server.
Fix #3626. | https://github.com/huggingface/datasets/pull/3627 | [
"We should also update the `bookcorpusopen` download url (see #3561) , no? ",
"For `the_pile_openwebtext2` and `the_pile_stack_exchange` I did not regenerate the JSON files, but instead I just changed the download_checksums URL. ",
"Seems like the mystic URL is now broken and the original should be used. ",
"... | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3627",
"html_url": "https://github.com/huggingface/datasets/pull/3627",
"diff_url": "https://github.com/huggingface/datasets/pull/3627.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3627.patch",
"merged_at": "2022-02-14T08:40... | 3,627 | true |
The Pile cannot connect to host | ## Describe the bug
The Pile had issues with their previous host server and have mirrored its content to another server.
The new URL server should be updated.
| https://github.com/huggingface/datasets/issues/3626 | [] | null | 3,626 | false |
Add a metadata field for when source data was produced | **Is your feature request related to a problem? Please describe.**
The current problem is that information about when source data was produced is not easily visible. Though there are a variety of metadata fields available in the dataset viewer, time period information is not included. This feature request suggests mak... | https://github.com/huggingface/datasets/issues/3625 | [
"A question to the datasets maintainers: is there a policy about how the set of allowed metadata fields is maintained and expanded?\r\n\r\nMetadata are very important, but defining the standard is always a struggle between allowing exhaustivity without being too complex. Archivists have Dublin Core, open data has h... | null | 3,625 | false |
Extend support for streaming datasets that use os.path.relpath | This PR extends the support in streaming mode for datasets that use `os.path.relpath`, by patching that function.
This feature will also be useful to yield the relative path of audio or image files, within an archive or parent dir.
Close #3622. | https://github.com/huggingface/datasets/pull/3623 | [] | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3623",
"html_url": "https://github.com/huggingface/datasets/pull/3623",
"diff_url": "https://github.com/huggingface/datasets/pull/3623.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3623.patch",
"merged_at": "2022-02-04T14:03... | 3,623 | true |
Extend support for streaming datasets that use os.path.relpath | Extend support for streaming datasets that use `os.path.relpath`.
This feature will also be useful to yield the relative path of audio or image files.
| https://github.com/huggingface/datasets/issues/3622 | [] | null | 3,622 | false |
Consider adding `ipywidgets` as a dependency. | When I install `datasets` in a fresh virtualenv with jupyterlab I always see this error.
```
ImportError: IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html
```
It's a bit of a nuisance, because I need to run shut down the jupyterlab ser... | https://github.com/huggingface/datasets/issues/3621 | [
"Hi! We use `tqdm` to display progress bars, so I suggest you open this issue in their repo.",
"It depends on how you use `tqdm`, no? \r\n\r\nDoesn't this library import via; \r\n\r\n```\r\nfrom tqdm.notebook import tqdm\r\n```",
"Hi! Sorry for the late reply. We import `tqdm` as `from tqdm.auto import tqdm`, w... | null | 3,621 | false |
Add Fon language tag | Add Fon language tag to resources. | https://github.com/huggingface/datasets/pull/3620 | [] | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3620",
"html_url": "https://github.com/huggingface/datasets/pull/3620",
"diff_url": "https://github.com/huggingface/datasets/pull/3620.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3620.patch",
"merged_at": "2022-02-04T14:04... | 3,620 | true |
fix meta in mls | `monolingual` value of `m ultilinguality` param in yaml meta was changed to `multilingual` :) | https://github.com/huggingface/datasets/pull/3619 | [
"Feel free to merge @polinaeterna as soon as you got an approval from either @lhoestq , @albertvillanova or @mariosasko"
] | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3619",
"html_url": "https://github.com/huggingface/datasets/pull/3619",
"diff_url": "https://github.com/huggingface/datasets/pull/3619.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3619.patch",
"merged_at": "2022-01-24T20:53... | 3,619 | true |
TIMIT Dataset not working with GPU | ## Describe the bug
I am working trying to use the TIMIT dataset in order to fine-tune Wav2Vec2 model and I am unable to load the "audio" column from the dataset when working with a GPU.
I am working on Amazon Sagemaker Studio, on the Python 3 (PyTorch 1.8 Python 3.6 GPU Optimized) environment, with a single ml.g4... | https://github.com/huggingface/datasets/issues/3618 | [
"Hi ! I think you should avoid calling `timit_train['audio']`. Indeed by doing so you're **loading all the audio column in memory**. This is problematic in your case because the TIMIT dataset is huge.\r\n\r\nIf you want to access the audio data of some samples, you should do this instead `timit_train[:10][\"train\"... | null | 3,618 | false |
PR for the CFPB Consumer Complaints dataset | Think I followed all the steps but please let me know if anything needs changing or any improvements I can make to the code quality | https://github.com/huggingface/datasets/pull/3617 | [
"> Nice ! Thanks for adding this dataset :)\n> \n> \n> \n> I left a few comments:\n\nThanks!\n\nI'd be interested in contributing to the core codebase - I had to go down the custom loading approach because I couldn't pull this dataset in using the load_dataset() method. Using either the json or csv files available ... | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3617",
"html_url": "https://github.com/huggingface/datasets/pull/3617",
"diff_url": "https://github.com/huggingface/datasets/pull/3617.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3617.patch",
"merged_at": "2022-02-07T21:08... | 3,617 | true |
Make streamable the BnL Historical Newspapers dataset | I've refactored the code in order to make the dataset streamable and to avoid it takes too long:
- I've used `iter_files`
Close #3615 | https://github.com/huggingface/datasets/pull/3616 | [] | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3616",
"html_url": "https://github.com/huggingface/datasets/pull/3616",
"diff_url": "https://github.com/huggingface/datasets/pull/3616.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3616.patch",
"merged_at": "2022-02-04T14:05... | 3,616 | true |
Dataset BnL Historical Newspapers does not work in streaming mode | ## Describe the bug
When trying to load in streaming mode, it "hangs"...
## Steps to reproduce the bug
```python
ds = load_dataset("bnl_newspapers", split="train", streaming=True)
```
## Expected results
The code should be optimized, so that it works fast in streaming mode.
CC: @davanstrien
| https://github.com/huggingface/datasets/issues/3615 | [
"@albertvillanova let me know if there is anything I can do to help with this. I had a quick look at the code again and though I could try the following changes:\r\n- use `download` instead of `download_and_extract`\r\nhttps://github.com/huggingface/datasets/blob/d3d339fb86d378f4cb3c5d1de423315c07a466c6/datasets/bn... | null | 3,615 | false |
Minor fixes | This PR:
* adds "desc" to the `ignore_kwargs` list in `Dataset.filter`
* fixes the default value of `id` in `DatasetDict.prepare_for_task` | https://github.com/huggingface/datasets/pull/3614 | [] | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3614",
"html_url": "https://github.com/huggingface/datasets/pull/3614",
"diff_url": "https://github.com/huggingface/datasets/pull/3614.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3614.patch",
"merged_at": "2022-01-24T12:45... | 3,614 | true |
Files not updating in dataset viewer | ## Dataset viewer issue for '*name of the dataset*'
**Link:**
Some examples:
* https://huggingface.co/datasets/abidlabs/crowdsourced-speech4
* https://huggingface.co/datasets/abidlabs/test-audio-13
*short description of the issue*
It seems that the dataset viewer is reading a cached version of the dataset and... | https://github.com/huggingface/datasets/issues/3613 | [
"Yes. The jobs queue is full right now, following an upgrade... Back to normality in the next hours hopefully. I'll look at your datasets to be sure the dataset viewer works as expected on them.",
"Should have been fixed now."
] | null | 3,613 | false |
wikifix | This should get the wikipedia dataloading script back up and running - at least I hope so (tested with language ff and ii) | https://github.com/huggingface/datasets/pull/3612 | [
"tests fail because of dataset_infos.json isn't updated. Unfortunately, I cannot get the datasets-cli locally to execute without error. Would need to troubleshoot, what's missing. Maybe someone else can pick up the stick. ",
"Hi ! If we change the default date to the latest one, users won't be able to load the \"... | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3612",
"html_url": "https://github.com/huggingface/datasets/pull/3612",
"diff_url": "https://github.com/huggingface/datasets/pull/3612.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3612.patch",
"merged_at": null
} | 3,612 | true |
Indexing bug after dataset.select() | ## Describe the bug
A clear and concise description of what the bug is.
Dataset indexing is not working as expected after `dataset.select(range(100))`
## Steps to reproduce the bug
```python
# Sample code to reproduce the bug
import datasets
task_to_keys = {
"cola": ("sentence", None),
"mnli":... | https://github.com/huggingface/datasets/issues/3611 | [
"Hi! Thanks for reporting! I've opened a PR with the fix."
] | null | 3,611 | false |
Checksum error when trying to load amazon_review dataset | ## Describe the bug
A clear and concise description of what the bug is.
## Steps to reproduce the bug
I am getting the issue when trying to load dataset using
```
dataset = load_dataset("amazon_polarity")
```
## Expected results
dataset loaded
## Actual results
```
-------------------------------------... | https://github.com/huggingface/datasets/issues/3610 | [
"It is solved now"
] | null | 3,610 | false |
Fixes to pubmed dataset download function | Pubmed has updated its settings for 2022 and thus existing download script does not work. | https://github.com/huggingface/datasets/pull/3609 | [
"Hi ! I think we can simply add a new configuration for the 2022 data instead of replacing them.\r\nYou can add the new configuration here:\r\n```python\r\n BUILDER_CONFIGS = [\r\n datasets.BuilderConfig(name=\"2021\", description=\"The 2021 annual record\", version=datasets.Version(\"1.0.0\")),\r\n ... | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3609",
"html_url": "https://github.com/huggingface/datasets/pull/3609",
"diff_url": "https://github.com/huggingface/datasets/pull/3609.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3609.patch",
"merged_at": null
} | 3,609 | true |
Add support for continuous metrics (RMSE, MAE) | **Is your feature request related to a problem? Please describe.**
I am uploading our dataset and models for the "Constructing interval measures" method we've developed, which uses item response theory to convert multiple discrete labels into a continuous spectrum for hate speech. Once we have this outcome our NLP m... | https://github.com/huggingface/datasets/issues/3608 | [
"Hey @ck37 \r\n\r\nYou can always use a custom metric as explained [in this guide from HF](https://huggingface.co/docs/datasets/master/loading_metrics.html#using-a-custom-metric-script).\r\n\r\nIf this issue needs to be contributed to (for enhancing the metric API) I think [this link](https://scikit-learn.org/stabl... | null | 3,608 | false |
Add MIT Scene Parsing Benchmark | Add MIT Scene Parsing Benchmark (a subset of ADE20k).
TODOs:
* [x] add dummy data
* [x] add dataset card
* [x] generate `dataset_info.json`
| https://github.com/huggingface/datasets/pull/3607 | [] | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3607",
"html_url": "https://github.com/huggingface/datasets/pull/3607",
"diff_url": "https://github.com/huggingface/datasets/pull/3607.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3607.patch",
"merged_at": "2022-02-18T12:51... | 3,607 | true |
audio column not saved correctly after resampling | ## Describe the bug
After resampling the audio column, saving with save_to_disk doesn't seem to save with the correct type.
## Steps to reproduce the bug
- load a subset of common voice dataset (48Khz)
- resample audio column to 16Khz
- save with save_to_disk()
- load with load_from_disk()
## Expected resul... | https://github.com/huggingface/datasets/issues/3606 | [
"Hi ! We just released a new version of `datasets` that should fix this.\r\n\r\nI tested resampling and using save/load_from_disk afterwards and it seems to be fixed now",
"Hi @lhoestq, \r\n\r\nJust tested the latest datasets version, and confirming that this is fixed for me. \r\n\r\nThanks!",
"Also, just an FY... | null | 3,606 | false |
Adding Turkic X-WMT evaluation set for machine translation | This dataset is a human-translated evaluation set for MT crowdsourced and provided by the [Turkic Interlingua ](turkic-interlingua.org) community. It contains eval sets for 8 Turkic languages covering 88 language directions. Languages being covered are:
Azerbaijani (az)
Bashkir (ba)
English (en)
Karakalpak (kaa)
... | https://github.com/huggingface/datasets/pull/3605 | [
"hi! Thank you for all the comments! I believe I addressed them all. Let me know if there is anything else",
"Hi there! I was wondering if there is anything else to change before this can be merged",
"@lhoestq Hi! Just a gentle reminder about the steps to merge this one! ",
"Thanks for the heads up ! I think ... | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3605",
"html_url": "https://github.com/huggingface/datasets/pull/3605",
"diff_url": "https://github.com/huggingface/datasets/pull/3605.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3605.patch",
"merged_at": "2022-01-31T09:50... | 3,605 | true |
Dataset Viewer not showing Previews for Private Datasets | ## Dataset viewer issue for 'abidlabs/test-audio-13'
It seems that the dataset viewer does not show previews for `private` datasets, even for the user who's private dataset it is. See [1] for example. If I change the visibility to public, then it does show, but it would be useful to have the viewer even for private ... | https://github.com/huggingface/datasets/issues/3604 | [
"Sure, it's on the roadmap.",
"Closing in favor of https://github.com/huggingface/datasets-server/issues/39."
] | null | 3,604 | false |
Add British Library books dataset | This pull request adds a dataset of text from digitised (primarily 19th Century) books from the British Library. This collection has previously been used for training language models, e.g. https://github.com/dbmdz/clef-hipe/blob/main/hlms.md. It would be nice to make this dataset more accessible for others to use throu... | https://github.com/huggingface/datasets/pull/3603 | [
"Thanks for all the help and suggestions\r\n\r\n> Since the dataset has a very specific structure it might not be that easy so feel free to ping me if you have questions or if I can help !\r\n\r\nI did get a little stuck here! So far I have created directories for each config i.e:\r\n\r\n`datasets/datasets/blbooks/... | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3603",
"html_url": "https://github.com/huggingface/datasets/pull/3603",
"diff_url": "https://github.com/huggingface/datasets/pull/3603.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3603.patch",
"merged_at": "2022-01-31T17:01... | 3,603 | true |
Update url for conll2003 | Following https://github.com/huggingface/datasets/issues/3582 I'm changing the download URL of the conll2003 data files, since the previous host doesn't have the authorization to redistribute the data | https://github.com/huggingface/datasets/pull/3602 | [
"Hi. lhoestq \r\n\r\n\r\nWhat is the solution for it?\r\nyou can see it is still doesn't work here.\r\nhttps://colab.research.google.com/drive/1l52FGWuSaOaGYchit4CbmtUSuzNDx_Ok?usp=sharing\r\nThank you.\r\... | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3602",
"html_url": "https://github.com/huggingface/datasets/pull/3602",
"diff_url": "https://github.com/huggingface/datasets/pull/3602.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3602.patch",
"merged_at": "2022-01-19T15:43... | 3,602 | true |
Add conll2003 licensing | Following https://github.com/huggingface/datasets/issues/3582, this PR updates the licensing section of the CoNLL2003 dataset. | https://github.com/huggingface/datasets/pull/3601 | [] | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3601",
"html_url": "https://github.com/huggingface/datasets/pull/3601",
"diff_url": "https://github.com/huggingface/datasets/pull/3601.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3601.patch",
"merged_at": "2022-01-19T17:17... | 3,601 | true |
Use old url for conll2003 | As reported in https://github.com/huggingface/datasets/issues/3582 the CoNLL2003 data files are not available in the master branch of the repo that used to host them.
For now we can use the URL from an older commit to access the data files | https://github.com/huggingface/datasets/pull/3600 | [] | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3600",
"html_url": "https://github.com/huggingface/datasets/pull/3600",
"diff_url": "https://github.com/huggingface/datasets/pull/3600.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3600.patch",
"merged_at": "2022-01-19T14:16... | 3,600 | true |
The `add_column()` method does not work if used on dataset sliced with `select()` | Hello, I posted this as a question on the forums ([here](https://discuss.huggingface.co/t/add-column-does-not-work-if-used-on-dataset-sliced-with-select/13893)):
I have a dataset with 2000 entries
> dataset = Dataset.from_dict({'colA': list(range(2000))})
and from which I want to extract the first one thousan... | https://github.com/huggingface/datasets/issues/3599 | [
"similar #3611 "
] | null | 3,599 | false |
Readme info not being parsed to show on Dataset card page | ## Describe the bug
The info contained in the README.md file is not being shown in the dataset main page. Basic info and table of contents are properly formatted in the README.
## Steps to reproduce the bug
# Sample code to reproduce the bug
The README file is this one: https://huggingface.co/datasets/softcatal... | https://github.com/huggingface/datasets/issues/3598 | [
"i suspect a markdown parsing error, @severo do you want to take a quick look at it when you have some time?",
"# Problem\r\nThe issue seems to coming from the front matter of the README\r\n```---\r\nannotations_creators:\r\n- no-annotation\r\nlanguage_creators:\r\n- machine-generated\r\nlanguages:\r\n- 'ca'\r\n-... | null | 3,598 | false |
ERROR: File "setup.py" or "setup.cfg" not found. Directory cannot be installed in editable mode: /content | ## Bug
The install of streaming dataset is giving following error.
## Steps to reproduce the bug
```python
! git clone https://github.com/huggingface/datasets.git
! cd datasets
! pip install -e ".[streaming]"
```
## Actual results
Cloning into 'datasets'...
remote: Enumerating objects: 50816, done.
remot... | https://github.com/huggingface/datasets/issues/3597 | [
"Hi! The `cd` command in Jupyer/Colab needs to start with `%`, so this should work:\r\n```\r\n!git clone https://github.com/huggingface/datasets.git\r\n%cd datasets\r\n!pip install -e \".[streaming]\"\r\n```",
"thanks @mariosasko i had the same mistake and your solution is what was needed"
] | null | 3,597 | false |
Loss of cast `Image` feature on certain dataset method | ## Describe the bug
When an a column is cast to an `Image` feature, the cast type appears to be lost during certain operations. I first noticed this when using the `push_to_hub` method on a dataset that contained urls pointing to images which had been cast to an `image`. This also happens when using select on a data... | https://github.com/huggingface/datasets/issues/3596 | [
"Hi! Thanks for reporting! The issue with `cast_column` should be fixed by #3575 and after we merge that PR I'll start working on the `push_to_hub` support for the `Image`/`Audio` feature.",
"> Hi! Thanks for reporting! The issue with `cast_column` should be fixed by #3575 and after we merge that PR I'll start wo... | null | 3,596 | false |
Add ImageNet toy datasets from fastai | Adds the ImageNet toy datasets from FastAI: Imagenette, Imagewoof and Imagewang.
TODOs:
* [ ] add dummy data
* [ ] add dataset card
* [ ] generate `dataset_info.json` | https://github.com/huggingface/datasets/pull/3595 | [
"Thanks for your contribution, @mariosasko. Are you still interested in adding this dataset?\r\n\r\nWe are removing the dataset scripts from this GitHub repo and moving them to the Hugging Face Hub: https://huggingface.co/datasets\r\n\r\nWe would suggest you create this dataset there. Please, feel free to tell us i... | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3595",
"html_url": "https://github.com/huggingface/datasets/pull/3595",
"diff_url": "https://github.com/huggingface/datasets/pull/3595.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3595.patch",
"merged_at": null
} | 3,595 | true |
fix multiple language downloading in mC4 | If we try to access multiple languages of the [mC4 dataset](https://github.com/huggingface/datasets/tree/master/datasets/mc4), it will throw an error. For example, if we do
```python
mc4_subset_two_langs = load_dataset("mc4", languages=["st", "su"])
```
we got
```
FileNotFoundError: Couldn't find file at https:/... | https://github.com/huggingface/datasets/pull/3594 | [
"The CI failure is unrelated to your PR and fixed on master, merging :)"
] | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3594",
"html_url": "https://github.com/huggingface/datasets/pull/3594",
"diff_url": "https://github.com/huggingface/datasets/pull/3594.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3594.patch",
"merged_at": "2022-01-18T19:10... | 3,594 | true |
Update README.md | Towards license of Tweet Eval parts | https://github.com/huggingface/datasets/pull/3593 | [] | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3593",
"html_url": "https://github.com/huggingface/datasets/pull/3593",
"diff_url": "https://github.com/huggingface/datasets/pull/3593.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3593.patch",
"merged_at": "2022-01-20T17:14... | 3,593 | true |
Add QuickDraw dataset | Add the QuickDraw dataset.
TODOs:
* [x] add dummy data
* [x] add dataset card
* [x] generate `dataset_info.json` | https://github.com/huggingface/datasets/pull/3592 | [
"_The documentation is not available anymore as the PR was closed or merged._"
] | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3592",
"html_url": "https://github.com/huggingface/datasets/pull/3592",
"diff_url": "https://github.com/huggingface/datasets/pull/3592.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3592.patch",
"merged_at": "2022-06-09T09:56... | 3,592 | true |
Add support for time, date, duration, and decimal dtypes | Add support for the pyarrow time (maps to `datetime.time` in python), date (maps to `datetime.time` in python), duration (maps to `datetime.timedelta` in python), and decimal (maps to `decimal.decimal` in python) dtypes. This should be helpful when writing scripts for time-series datasets. | https://github.com/huggingface/datasets/pull/3591 | [
"Is there a dataset which uses these four datatypes for tests purposes?\r\n",
"@severo Not yet. I'll let you know if that changes."
] | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3591",
"html_url": "https://github.com/huggingface/datasets/pull/3591",
"diff_url": "https://github.com/huggingface/datasets/pull/3591.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3591.patch",
"merged_at": "2022-01-20T17:37... | 3,591 | true |
Update ANLI README.md | Update license and little things concerning ANLI | https://github.com/huggingface/datasets/pull/3590 | [] | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3590",
"html_url": "https://github.com/huggingface/datasets/pull/3590",
"diff_url": "https://github.com/huggingface/datasets/pull/3590.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3590.patch",
"merged_at": "2022-01-20T16:58... | 3,590 | true |
Pin torchmetrics to fix the COMET test | Torchmetrics 0.7.0 got released and has issues with `transformers` (see https://github.com/PyTorchLightning/metrics/issues/770)
I'm pinning it to 0.6.0 in the CI, since 0.7.0 makes the COMET metric test fail. COMET requires torchmetrics==0.6.0 anyway. | https://github.com/huggingface/datasets/pull/3589 | [] | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3589",
"html_url": "https://github.com/huggingface/datasets/pull/3589",
"diff_url": "https://github.com/huggingface/datasets/pull/3589.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3589.patch",
"merged_at": "2022-01-18T11:04... | 3,589 | true |
Update HellaSwag README.md | Adding information from the git repo and paper that were missing | https://github.com/huggingface/datasets/pull/3588 | [] | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3588",
"html_url": "https://github.com/huggingface/datasets/pull/3588",
"diff_url": "https://github.com/huggingface/datasets/pull/3588.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3588.patch",
"merged_at": "2022-01-20T16:57... | 3,588 | true |
No module named 'fsspec.archive' | ## Describe the bug
Cannot import datasets after installation.
## Steps to reproduce the bug
```shell
$ python
Python 3.9.7 (default, Sep 16 2021, 13:09:58)
[GCC 7.5.0] :: Anaconda, Inc. on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import datasets
Traceback (most recent... | https://github.com/huggingface/datasets/issues/3587 | [] | null | 3,587 | false |
Revisit `enable/disable_` toggle function prefix | As discussed in https://github.com/huggingface/transformers/pull/15167, we should revisit the `enable/disable_` toggle function prefix, potentially in favor of `set_enabled_`. Concretely, this translates to
- De-deprecating `disable_progress_bar()`
- Adding `enable_progress_bar()`
- On the caching side, adding `en... | https://github.com/huggingface/datasets/issues/3586 | [] | null | 3,586 | false |
Datasets streaming + map doesn't work for `Audio` | ## Describe the bug
When using audio datasets in streaming mode, applying a `map(...)` before iterating leads to an error as the key `array` does not exist anymore.
## Steps to reproduce the bug
```python
from datasets import load_dataset
ds = load_dataset("common_voice", "en", streaming=True, split="train")... | https://github.com/huggingface/datasets/issues/3585 | [
"This seems related to https://github.com/huggingface/datasets/issues/3505."
] | null | 3,585 | false |
https://huggingface.co/datasets/huggingface/transformers-metadata | ## Dataset viewer issue for '*name of the dataset*'
**Link:** *link to the dataset viewer page*
*short description of the issue*
Am I the one who added this dataset ? Yes-No
| https://github.com/huggingface/datasets/issues/3584 | [] | null | 3,584 | false |
Add The Medical Segmentation Decathlon Dataset | ## Adding a Dataset
- **Name:** *The Medical Segmentation Decathlon Dataset*
- **Description:** The underlying data set was designed to explore the axis of difficulties typically encountered when dealing with medical images, such as small data sets, unbalanced labels, multi-site data, and small objects.
- **Paper:*... | https://github.com/huggingface/datasets/issues/3583 | [
"Hello! I have recently been involved with a medical image segmentation project myself and was going through the `The Medical Segmentation Decathlon Dataset` as well. \r\nI haven't yet had experience adding datasets to this repository yet but would love to get started. Should I take this issue?\r\nIf yes, I've got ... | null | 3,583 | false |
conll 2003 dataset source url is no longer valid | ## Describe the bug
Loading `conll2003` dataset fails because it was removed (just yesterday 1/14/2022) from the location it is looking for.
## Steps to reproduce the bug
```python
from datasets import load_dataset
load_dataset("conll2003")
```
## Expected results
The dataset should load.
## Actual r... | https://github.com/huggingface/datasets/issues/3582 | [
"I came to open the same issue.",
"Thanks for reporting !\r\n\r\nI pushed a temporary fix on `master` that uses an URL from a previous commit to access the dataset for now, until we have a better solution",
"I changed the URL again to use another host, the fix is available on `master` and we'll probably do a ne... | null | 3,582 | false |
Unable to create a dataset from a parquet file in S3 | ## Describe the bug
Trying to create a dataset from a parquet file in S3.
## Steps to reproduce the bug
```python
import s3fs
from datasets import Dataset
s3 = s3fs.S3FileSystem(anon=False)
with s3.open(PATH_LTR_TOY_CLEAN_DATASET, 'rb') as s3file:
dataset = Dataset.from_parquet(s3file)
```
## Expe... | https://github.com/huggingface/datasets/issues/3581 | [
"Hi ! Currently it only works with local paths, file-like objects are not supported yet"
] | null | 3,581 | false |
Bug in wiki bio load |
wiki_bio is failing to load because of a failing drive link . Can someone fix this ?
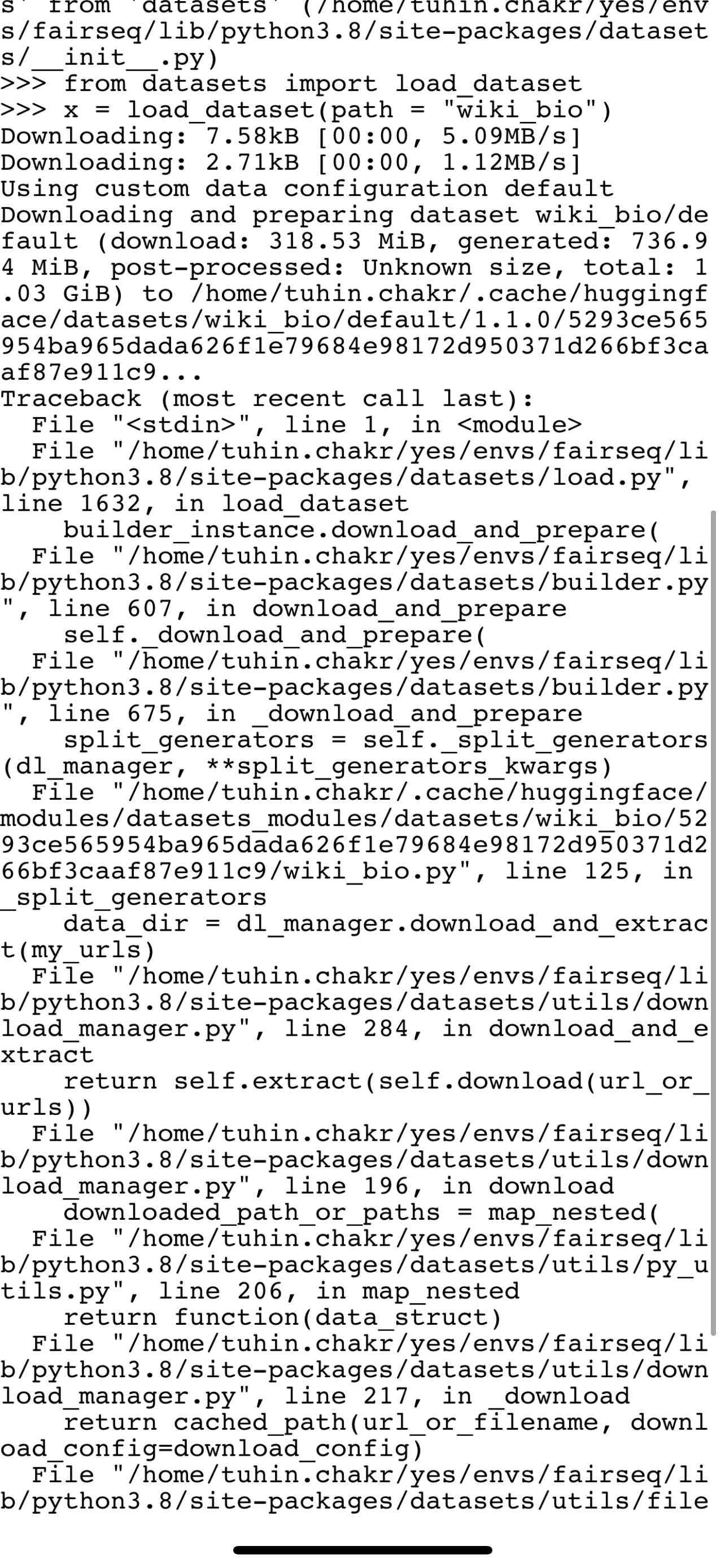
\r\nDownloading: 7.58kB [00:00, 4.42MB/s]\r\nDownloading: 2.71kB [00:00, 1.30MB/s]\r\nUsing custom data configuration default\r\nDownloading and preparing dataset wiki_bio/default (download: 318... | null | 3,580 | false |
Add Text2log Dataset | Adding the text2log dataset used for training FOL sentence translating models | https://github.com/huggingface/datasets/pull/3579 | [
"The CI fails are unrelated to your PR and fixed on master, I think we can merge now !"
] | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3579",
"html_url": "https://github.com/huggingface/datasets/pull/3579",
"diff_url": "https://github.com/huggingface/datasets/pull/3579.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3579.patch",
"merged_at": "2022-01-20T17:09... | 3,579 | true |
label information get lost after parquet serialization | ## Describe the bug
In *dataset_info.json* file, information about the label get lost after the dataset serialization.
## Steps to reproduce the bug
```python
from datasets import load_dataset
# normal save
dataset = load_dataset('glue', 'sst2', split='train')
dataset.save_to_disk("normal_save")
# save ... | https://github.com/huggingface/datasets/issues/3578 | [
"Hi ! We did a release of `datasets` today that may fix this issue. Can you try updating `datasets` and trying again ?\r\n\r\nEDIT: the issue is still there actually\r\n\r\nI think we can fix that by storing the Features in the parquet schema metadata, and then reload them when loading the parquet file"
] | null | 3,578 | false |
Add The Mexican Emotional Speech Database (MESD) | ## Adding a Dataset
- **Name:** *The Mexican Emotional Speech Database (MESD)*
- **Description:** *Contains 864 voice recordings with six different prosodies: anger, disgust, fear, happiness, neutral, and sadness. Furthermore, three voice categories are included: female adult, male adult, and child. *
- **Paper:** *... | https://github.com/huggingface/datasets/issues/3577 | [] | null | 3,577 | false |
Add PASS dataset | This PR adds the PASS dataset.
Closes #3043 | https://github.com/huggingface/datasets/pull/3576 | [] | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3576",
"html_url": "https://github.com/huggingface/datasets/pull/3576",
"diff_url": "https://github.com/huggingface/datasets/pull/3576.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3576.patch",
"merged_at": "2022-01-20T16:50... | 3,576 | true |
Add Arrow type casting to struct for Image and Audio + Support nested casting | ## Intro
1. Currently, it's not possible to have nested features containing Audio or Image.
2. Moreover one can keep an Arrow array as a StringArray to store paths to images, but such arrays can't be directly concatenated to another image array if it's stored an another Arrow type (typically, a StructType).
3... | https://github.com/huggingface/datasets/pull/3575 | [
"Regarding the tests I'm just missing the FixedSizeListType type casting for ListArray objects, will to it tomorrow as well as adding new tests + docstrings\r\n\r\nand also adding soundfile in the CI",
"While writing some tests I noticed that the ExtensionArray can't be directly concatenated - maybe we can get ri... | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3575",
"html_url": "https://github.com/huggingface/datasets/pull/3575",
"diff_url": "https://github.com/huggingface/datasets/pull/3575.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3575.patch",
"merged_at": "2022-01-21T13:22... | 3,575 | true |
Fix qa4mre tags | The YAML tags were invalid. I also fixed the dataset mirroring logging that failed because of this issue [here](https://github.com/huggingface/datasets/actions/runs/1690109581) | https://github.com/huggingface/datasets/pull/3574 | [] | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3574",
"html_url": "https://github.com/huggingface/datasets/pull/3574",
"diff_url": "https://github.com/huggingface/datasets/pull/3574.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3574.patch",
"merged_at": "2022-01-13T14:03... | 3,574 | true |
Add Mauve metric | Add support for the [Mauve](https://github.com/krishnap25/mauve) metric introduced in this [paper](https://arxiv.org/pdf/2102.01454.pdf) (Neurips, 2021). | https://github.com/huggingface/datasets/pull/3573 | [
"Hi ! The CI was failing because `mauve-text` wasn't installed. I added it to the CI setup :)\r\n\r\nI also did some minor changes to the script itself, especially to remove `**kwargs` and explicitly mentioned all the supported arguments (this way if someone does a typo with some parameters they get an error)"
] | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3573",
"html_url": "https://github.com/huggingface/datasets/pull/3573",
"diff_url": "https://github.com/huggingface/datasets/pull/3573.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3573.patch",
"merged_at": "2022-01-20T15:00... | 3,573 | true |
ConnectionError in IndicGLUE dataset | While I am trying to load IndicGLUE dataset (https://huggingface.co/datasets/indic_glue) it is giving me with the error:
```
ConnectionError: Couldn't reach https://storage.googleapis.com/ai4bharat-public-indic-nlp-corpora/evaluations/wikiann-ner.tar.gz (error 403) | https://github.com/huggingface/datasets/issues/3572 | [
"@sahoodib, thanks for reporting.\r\n\r\nIndeed, none of the data links appearing in the IndicGLUE website are working, e.g.: https://storage.googleapis.com/ai4bharat-public-indic-nlp-corpora/evaluations/soham-articles.tar.gz\r\n```\r\n<Error>\r\n<Code>UserProjectAccountProblem</Code>\r\n<Message>User project billi... | null | 3,572 | false |
Add missing tasks to MuchoCine dataset | Addresses the 2nd bullet point in #2520.
I'm also removing the licensing information, because I couldn't verify that it is correct. | https://github.com/huggingface/datasets/pull/3571 | [] | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3571",
"html_url": "https://github.com/huggingface/datasets/pull/3571",
"diff_url": "https://github.com/huggingface/datasets/pull/3571.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3571.patch",
"merged_at": "2022-01-20T16:51... | 3,571 | true |
Add the KMWP dataset (extension of #3564) | New pull request of #3564 (Add the KMWP dataset) | https://github.com/huggingface/datasets/pull/3570 | [
"Sorry, I'm late to check! I'll send it to you soon!",
"Thanks for your contribution, @sooftware. Are you still interested in adding this dataset?\r\n\r\nWe are removing the dataset scripts from this GitHub repo and moving them to the Hugging Face Hub: https://huggingface.co/datasets\r\n\r\nWe would suggest you c... | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3570",
"html_url": "https://github.com/huggingface/datasets/pull/3570",
"diff_url": "https://github.com/huggingface/datasets/pull/3570.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3570.patch",
"merged_at": null
} | 3,570 | true |
Add the DKTC dataset (Extension of #3564) | New pull request of #3564. (for DKTC)
| https://github.com/huggingface/datasets/pull/3569 | [
"I reflect your comment! @lhoestq ",
"Wait, the format of the data just changed, so I'll take it into consideration and commit it.",
"I update the code according to the dataset structure change.",
"Thanks ! I think the dummy data are not valid yet - the dummy train.csv file only contains a partial example (th... | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3569",
"html_url": "https://github.com/huggingface/datasets/pull/3569",
"diff_url": "https://github.com/huggingface/datasets/pull/3569.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3569.patch",
"merged_at": null
} | 3,569 | true |
Downloading Hugging Face Medical Dialog Dataset NonMatchingSplitsSizesError | I wanted to download the Nedical Dialog Dataset from huggingface, using this github link:
https://github.com/huggingface/datasets/tree/master/datasets/medical_dialog
After downloading the raw datasets from google drive, i unpacked everything and put it in the same folder as the medical_dialog.py which is:
```
... | https://github.com/huggingface/datasets/issues/3568 | [
"Hi @fabianslife, thanks for reporting.\r\n\r\nI think you were using an old version of `datasets` because this bug was already fixed in version `1.13.0` (13 Oct 2021):\r\n- Fix: 55fd140a63b8f03a0e72985647e498f1fc799d3f\r\n- PR: #3046\r\n- Issue: #2969 \r\n\r\nPlease, feel free to update the library: `pip install -... | null | 3,568 | false |
Fix push to hub to allow individual split push | # Description of the issue
If one decides to push a split on a datasets repo, he uploads the dataset and overrides the config. However previous config splits end up being lost despite still having the dataset necessary.
The new flow is the following:
- query the old config from the repo
- update into a new co... | https://github.com/huggingface/datasets/pull/3567 | [
"This has been addressed in https://github.com/huggingface/datasets/pull/4415. Closing."
] | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3567",
"html_url": "https://github.com/huggingface/datasets/pull/3567",
"diff_url": "https://github.com/huggingface/datasets/pull/3567.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3567.patch",
"merged_at": null
} | 3,567 | true |
Add initial electricity time series dataset | Here is an initial prototype time series dataset | https://github.com/huggingface/datasets/pull/3566 | [
"@kashif Some commits on the PR branch are not authored by you, so could you please open a new PR and not use rebase this time :)? You can copy and paste the dataset dir to the new branch. \r\n\r\n",
"making a new PR"
] | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3566",
"html_url": "https://github.com/huggingface/datasets/pull/3566",
"diff_url": "https://github.com/huggingface/datasets/pull/3566.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3566.patch",
"merged_at": null
} | 3,566 | true |
Add parameter `preserve_index` to `from_pandas` | Added optional parameter, so that user can get rid of useless index preserving. [Issue](https://github.com/huggingface/datasets/issues/3563) | https://github.com/huggingface/datasets/pull/3565 | [
"> \r\n\r\nI did `make style` and it affected over 500 files\r\n\r\n```\r\nAll done! ✨ 🍰 ✨\r\n575 files reformatted, 372 files left unchanged.\r\nisort tests src benchmarks datasets/**/*.py metri\r\n```\r\n\r\n(result)\r\n
# Some DataFrame preprocessing code...
dataset = Dataset.from_pandas(df)
`... | https://github.com/huggingface/datasets/issues/3563 | [
"Hi! That makes sense. Sure, feel free to open a PR! Just a small suggestion: let's make `preserve_index` a parameter of `Dataset.from_pandas` (which we then pass to `InMemoryTable.from_pandas`) with `None` as a default value to not have this as a breaking change. "
] | null | 3,563 | false |
Allow multiple task templates of the same type | Add support for multiple task templates of the same type. Fixes (partially) #2520.
CC: @lewtun | https://github.com/huggingface/datasets/pull/3562 | [] | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3562",
"html_url": "https://github.com/huggingface/datasets/pull/3562",
"diff_url": "https://github.com/huggingface/datasets/pull/3562.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3562.patch",
"merged_at": "2022-01-11T14:16... | 3,562 | true |
Cannot load ‘bookcorpusopen’ | ## Describe the bug
Cannot load 'bookcorpusopen'
## Steps to reproduce the bug
```python
dataset = load_dataset('bookcorpusopen')
```
or
```python
dataset = load_dataset('bookcorpusopen',script_version='master')
```
## Actual results
ConnectionError: Couldn't reach https://the-eye.eu/public/AI/pile_pre... | https://github.com/huggingface/datasets/issues/3561 | [
"The host of this copy of the dataset (https://the-eye.eu) is down and has been down for a good amount of time ([potentially months](https://www.reddit.com/r/Roms/comments/q82s15/theeye_downdied/))\r\n\r\nFinding this dataset is a little esoteric, as the original authors took down the official BookCorpus dataset so... | null | 3,561 | false |
Run pyupgrade for Python 3.6+ | Run the command:
```bash
pyupgrade $(find . -name "*.py" -type f) --py36-plus
```
Which mainly avoids unnecessary lists creations and also removes unnecessary code for Python 3.6+.
It was originally part of #3489.
Tip for reviewing faster: use the CLI (`git diff`) and scroll. | https://github.com/huggingface/datasets/pull/3560 | [
"Hi ! Thanks for the change :)\r\nCould it be possible to only run it for the code in `src/` ? We try to not change the code in the `datasets/` directory too often since it refreshes the users cache when they upgrade `datasets`.",
"> Hi ! Thanks for the change :)\r\n> Could it be possible to only run it for the c... | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3560",
"html_url": "https://github.com/huggingface/datasets/pull/3560",
"diff_url": "https://github.com/huggingface/datasets/pull/3560.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3560.patch",
"merged_at": "2022-01-31T09:37... | 3,560 | true |
Fix `DuplicatedKeysError` and improve card in `tweet_qa` | Fix #3555 | https://github.com/huggingface/datasets/pull/3559 | [] | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3559",
"html_url": "https://github.com/huggingface/datasets/pull/3559",
"diff_url": "https://github.com/huggingface/datasets/pull/3559.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3559.patch",
"merged_at": "2022-01-12T15:13... | 3,559 | true |
Integrate Milvus (pymilvus) library | Milvus is a popular open-source vector database. We should add a new vector index to support this project. | https://github.com/huggingface/datasets/issues/3558 | [
"Hi @mariosasko,Just search randomly and I found this issue~ I'm the tech lead of Milvus and we are looking forward to integrate milvus together with huggingface datasets.\r\n\r\nAny suggestion on how we could start?\r\n",
"Feel free to assign to me and we probably need some guide on it",
"@mariosasko any updat... | null | 3,558 | false |
Fix bug in `ImageClassifcation` task template | Fixes a bug in the `ImageClassification` task template which requires specifying class labels twice in dataset scripts. Additionally, this PR refactors the API around the classification task templates for cleaner `labels` handling.
CC: @lewtun @nateraw | https://github.com/huggingface/datasets/pull/3557 | [
"The CI failures are unrelated to the changes in this PR.",
"> The CI failures are unrelated to the changes in this PR.\r\n\r\nIt seems that some of the failures are due to the tests on the dataset cards (e.g. CIFAR, MNIST, FASHION_MNIST). Perhaps it's worth addressing those in this PR to avoid confusing downstre... | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3557",
"html_url": "https://github.com/huggingface/datasets/pull/3557",
"diff_url": "https://github.com/huggingface/datasets/pull/3557.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3557.patch",
"merged_at": "2022-01-11T15:47... | 3,557 | true |
Preserve encoding/decoding with features in `Iterable.map` call | As described in https://github.com/huggingface/datasets/issues/3505#issuecomment-1004755657, this PR uses a generator expression to encode/decode examples with `features` (which are set to None in `map`) before applying a map transform.
Fix #3505 | https://github.com/huggingface/datasets/pull/3556 | [] | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3556",
"html_url": "https://github.com/huggingface/datasets/pull/3556",
"diff_url": "https://github.com/huggingface/datasets/pull/3556.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3556.patch",
"merged_at": "2022-01-18T19:54... | 3,556 | true |
DuplicatedKeysError when loading tweet_qa dataset | When loading the tweet_qa dataset with `load_dataset('tweet_qa')`, the following error occurs:
`DuplicatedKeysError: FAILURE TO GENERATE DATASET !
Found duplicate Key: 2a167f9e016ba338e1813fed275a6a1e
Keys should be unique and deterministic in nature
`
Might be related to issues #2433 and #2333
- `datasets` ... | https://github.com/huggingface/datasets/issues/3555 | [
"Hi, we've just merged the PR with the fix. The fixed version of the dataset can be downloaded as follows:\r\n```python\r\nimport datasets\r\ndset = datasets.load_dataset(\"tweet_qa\", revision=\"master\")\r\n```"
] | null | 3,555 | false |
ImportError: cannot import name 'is_valid_waiter_error' | Based on [SO post](https://stackoverflow.com/q/70606147/17840900).
I'm following along to this [Notebook][1], cell "**Loading the dataset**".
Kernel: `conda_pytorch_p36`.
I run:
```
! pip install datasets transformers optimum[intel]
```
Output:
```
Requirement already satisfied: datasets in /home/ec2-u... | https://github.com/huggingface/datasets/issues/3554 | [
"Hi! I can't reproduce this error in Colab, but I'm assuming you are using Amazon SageMaker Studio Notebooks (you mention the `conda_pytorch_p36` kernel), so maybe @philschmid knows more about what might be causing this issue? ",
"Hey @mariosasko. Yes, I am using **Amazon SageMaker Studio Jupyter Labs**. However,... | null | 3,554 | false |
set_format("np") no longer works for Image data | ## Describe the bug
`dataset.set_format("np")` no longer works for image data, previously you could load the MNIST like this:
```python
dataset = load_dataset("mnist")
dataset.set_format("np")
X_train = dataset["train"]["image"][..., None] # <== No longer a numpy array
```
but now it doesn't work, `set_format(... | https://github.com/huggingface/datasets/issues/3553 | [
"A quick fix for now is doing this:\r\n\r\n```python\r\nX_train = np.stack(dataset[\"train\"][\"image\"])[..., None]",
"This error also propagates to jax and is even trickier to fix, since `.with_format(type='jax')` will use numpy conversion internally (and fail). For a three line failure:\r\n\r\n```python\r\ndat... | null | 3,553 | false |
Add the KMWP & DKTC dataset. | Add the KMWP & DKTC dataset.
Additional notes:
- Both datasets will be released on January 10 through the GitHub link below.
- https://github.com/tunib-ai/DKTC
- https://github.com/tunib-ai/KMWP
- So it doesn't work as a link at the moment, but the code will work soon (after it is released on January 10). | https://github.com/huggingface/datasets/pull/3552 | [] | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3552",
"html_url": "https://github.com/huggingface/datasets/pull/3552",
"diff_url": "https://github.com/huggingface/datasets/pull/3552.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3552.patch",
"merged_at": null
} | 3,552 | true |
Add more compression types for `to_json` | This PR adds `bz2`, `xz`, and `zip` (WIP) for `to_json`. I also plan to add `infer` like how `pandas` does it | https://github.com/huggingface/datasets/pull/3551 | [
"@lhoestq, I looked into how to compress with `zipfile` for which few methods exist, let me know which one looks good:\r\n1. create the file in normal `wb` mode and then zip it separately\r\n2. use `ZipFile.write_str` to write file into the archive. For this we'll need to change how we're writing files from `_write... | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3551",
"html_url": "https://github.com/huggingface/datasets/pull/3551",
"diff_url": "https://github.com/huggingface/datasets/pull/3551.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3551.patch",
"merged_at": "2022-02-21T15:58... | 3,551 | true |
Bug in `openbookqa` dataset | ## Describe the bug
Dataset entries contains a typo.
## Steps to reproduce the bug
```python
>>> from datasets import load_dataset
>>> obqa = load_dataset('openbookqa', 'main')
>>> obqa['train'][0]
```
## Expected results
```python
{'id': '7-980', 'question_stem': 'The sun is responsible for', 'choices'... | https://github.com/huggingface/datasets/issues/3550 | [
"Closed by:\r\n- #4259"
] | null | 3,550 | false |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.