
ChartVerse
Collection
8 items • Updated • 9
ChartVerse-Coder is a complexity-aware chart code generator that can autonomously synthesize diverse, high-complexity chart codes from scratch, developed as part of the opendatalab/ChartVerse project. For more details about our method, datasets, and full model series, please visit our Project Page.
Unlike prior template-based or seed-conditioned approaches, ChartVerse-Coder generates chart code via high-temperature sampling, enabling broad exploration of the long-tail chart distribution and producing diverse, realistic charts with high structural complexity.
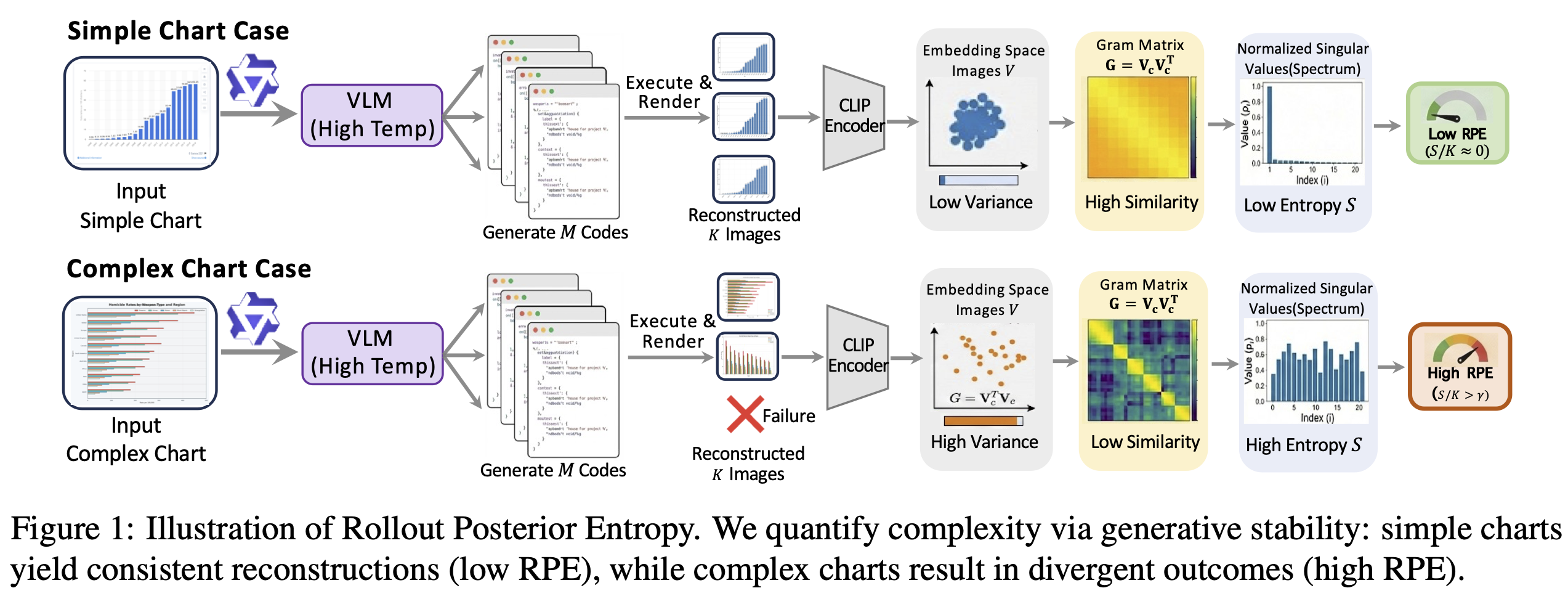
We propose Rollout Posterior Entropy (RPE) to quantify intrinsic chart complexity via generative stability:
Key Insight: Simple charts yield consistent reconstructions (low RPE), while complex charts result in divergent outcomes (high RPE). We retain only samples with RPE ≥ 0.4.
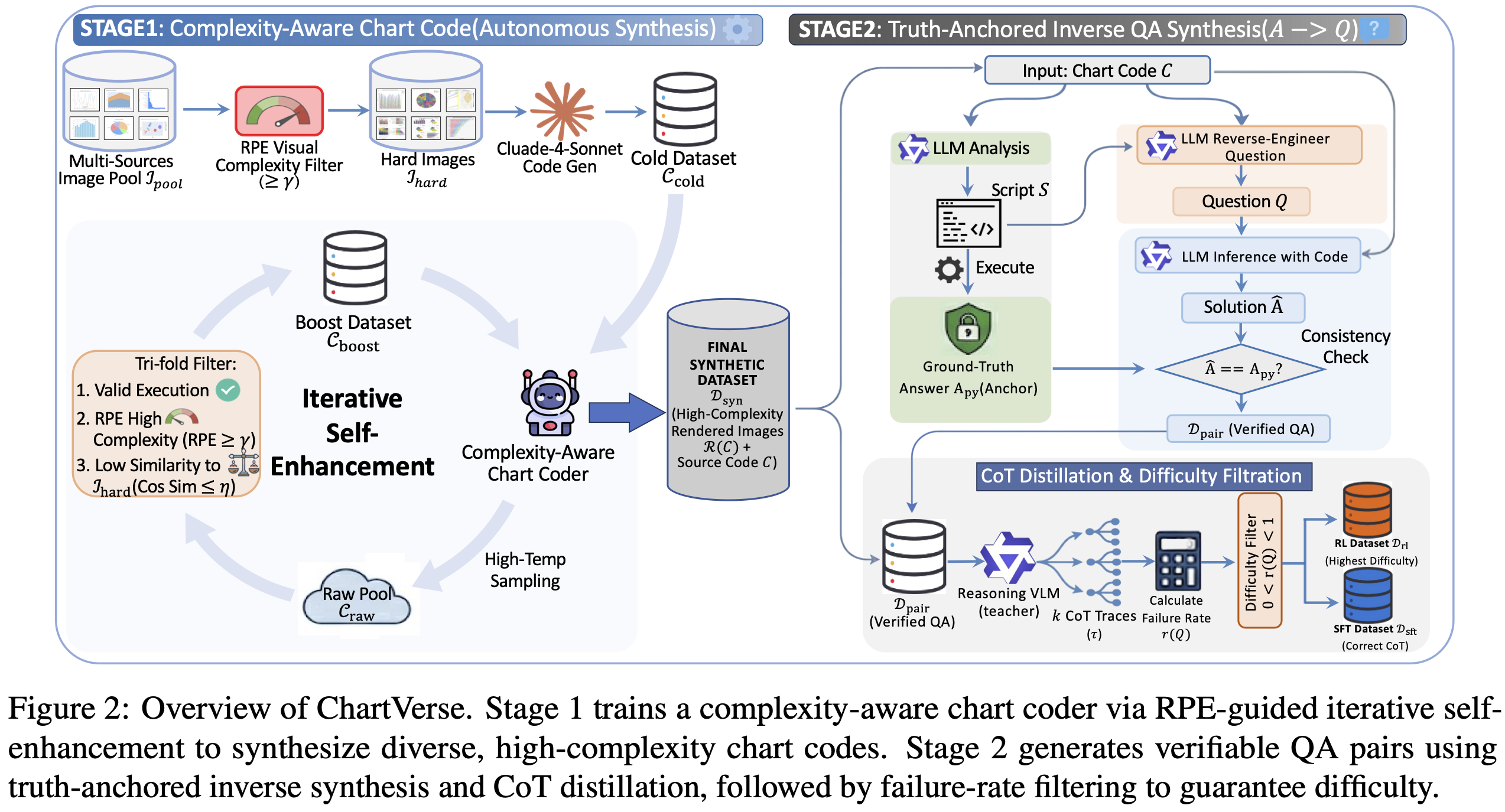
Stage 1: Difficulty-Filtered Cold Start
Stage 2: Iterative Self-Enhancement
Final Output: Generate 1M high-complexity chart code samples for downstream QA synthesis.
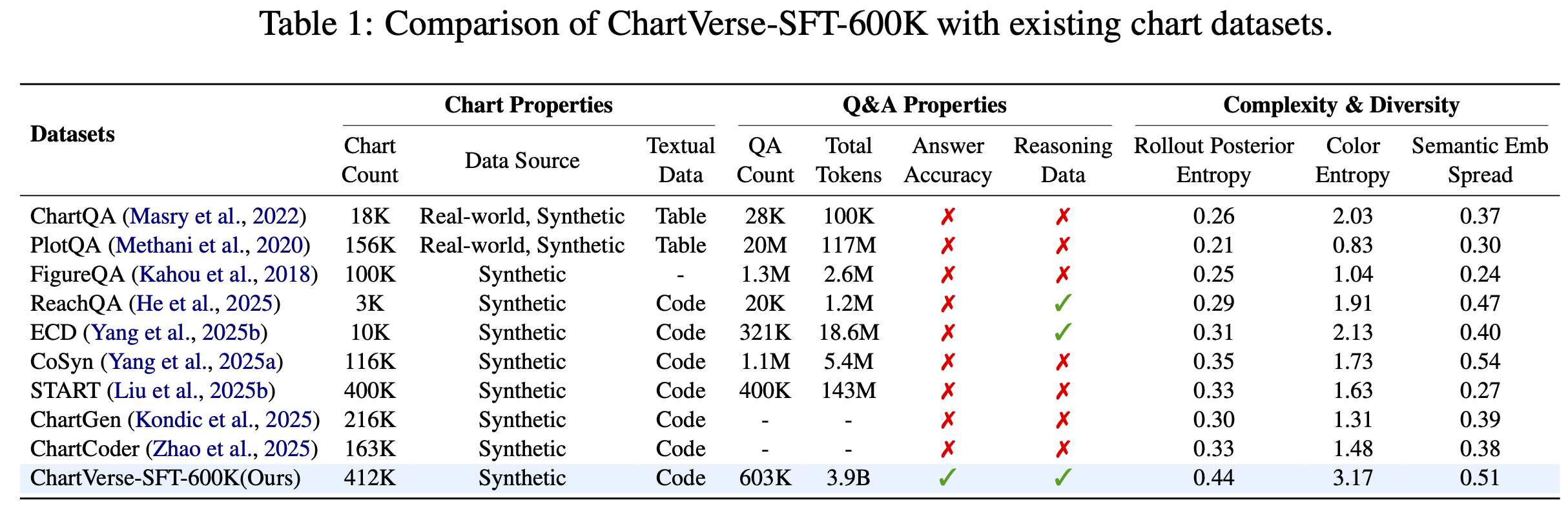
ChartVerse-Coder synthesizes charts with significantly higher complexity and diversity than all existing datasets.
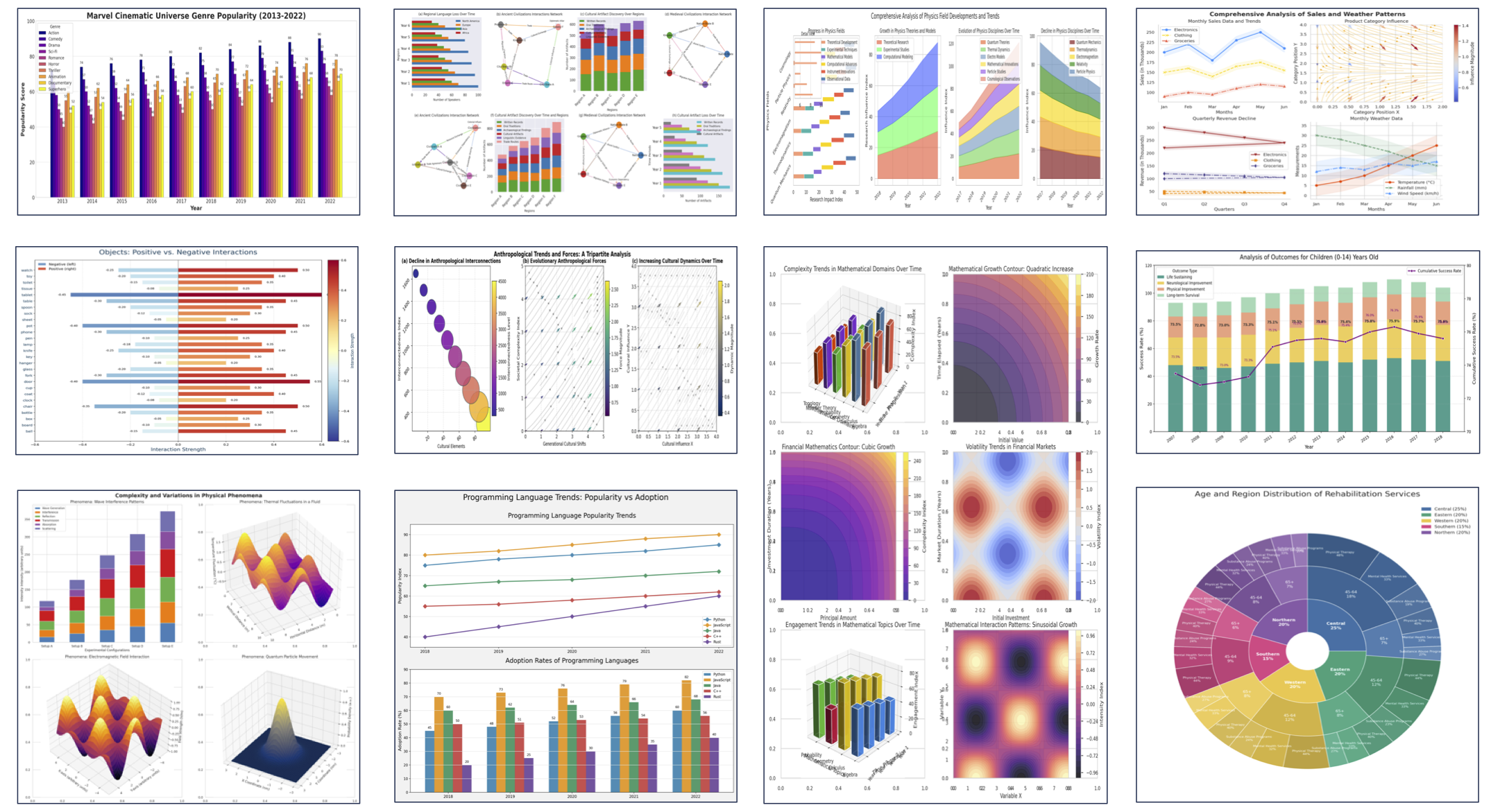
Our synthesized charts demonstrate exceptional diversity:
from transformers import AutoModelForCausalLM, AutoTokenizer
# Load Model
model_path = "opendatalab/ChartVerse-Coder"
model = AutoModelForCausalLM.from_pretrained(
model_path, torch_dtype="auto", device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_path)
# System Prompt
prompt = """You are a Python visualization expert. Generate a random Python visualization code focusing on charts, tables, or diagrams.
Requirements:
- Choose any visualization type (chart, table, flowchart, diagram, etc.)
- Create sample data
- Use Python visualization library (matplotlib, graphviz, etc.)
- Make it visually appealing with proper labels, titles, and colors
- Include sufficient visual elements
- Carefully design the layout to avoid any overlapping text or elements
- Adjust figure size, margins, and spacing for optimal clarity
- Make it visually appealing with proper labels, titles, and colors
Output format: Only output the Python visualization code wrapped in ```python```
"""
# Generate Chart Code
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
inputs = tokenizer(text, return_tensors="pt").to("cuda")
# High-temperature sampling for diversity
outputs = model.generate(
**inputs,
max_new_tokens=4096,
temperature=1.0,
top_p=0.95,
top_k=20,
do_sample=True
)
generated_code = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(generated_code)
import re
import matplotlib.pyplot as plt
# Extract code from response
code_match = re.search(r'```python\n(.*?)```', generated_code, re.DOTALL)
if code_match:
code = code_match.group(1)
exec(code) # This will save the figure as 'image.png'
@misc{liu2026chartversescalingchartreasoning,
title={ChartVerse: Scaling Chart Reasoning via Reliable Programmatic Synthesis from Scratch},
author={Zheng Liu and Honglin Lin and Chonghan Qin and Xiaoyang Wang and Xin Gao and Yu Li and Mengzhang Cai and Yun Zhu and Zhanping Zhong and Qizhi Pei and Zhuoshi Pan and Xiaoran Shang and Bin Cui and Conghui He and Wentao Zhang and Lijun Wu},
year={2026},
eprint={2601.13606},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2601.13606},
}
This model is released under the Apache 2.0 License.