
🌾Oat-Zero: Understanding R1-Zero-Like Training
Collection
5 items • Updated • 7
This model is trained by the minimalist R1-Zero recipe introduced in our paper:
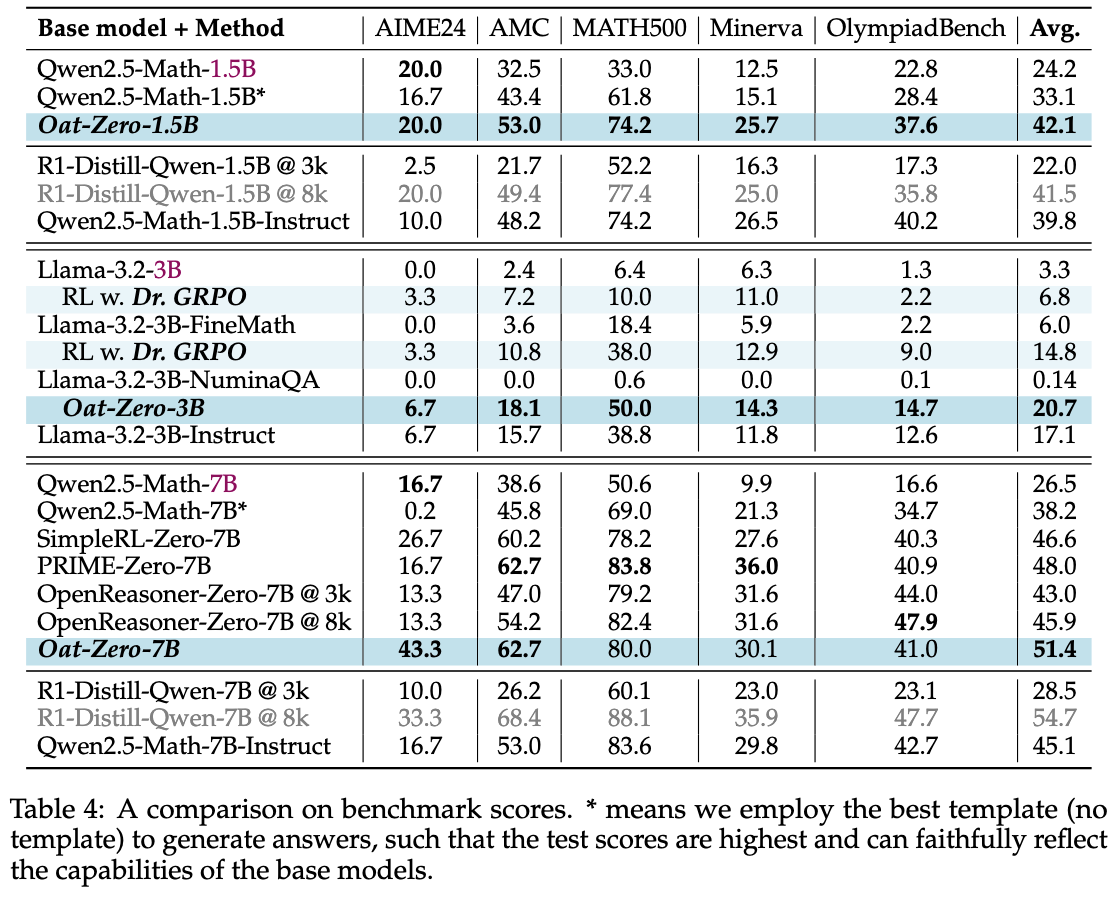
Evaluation results on widely used math benchmarks are shown below:
import vllm
def apply_qwen_math_template(question: str):
return (
"<|im_start|>system\nPlease reason step by step, and put your final answer within \\boxed{}.<|im_end|>\n<|im_start|>user\n"
+ question
+ "<|im_end|>\n<|im_start|>assistant\n"
)
def apply_r1_template(question: str):
return (
"A conversation between User and Assistant. The User asks a question, and the Assistant solves it. The Assistant first thinks about the reasoning process in the mind and then provides the User with the answer. "
"The reasoning process is enclosed within <think> </think> and answer is enclosed within <answer> </answer> tags, respectively, i.e., <think> reasoning process here </think> <answer> answer here </answer>.\nUser: "
+ question
+ "\nAssistant: <think>"
)
model_name = "sail/Qwen2.5-Math-7B-Oat-Zero"
sampling_params = vllm.SamplingParams(
n=1,
temperature=0,
top_p=1,
max_tokens=3000,
)
model = vllm.LLM(
model_name,
max_model_len=4096,
dtype="bfloat16",
enable_prefix_caching=True,
)
if "Llama-3.2-3B-Oat-Zero" in model_name:
apply_template = apply_r1_template
else:
apply_template = apply_qwen_math_template
prompts = [
"How many positive whole-number divisors does 196 have?"
]
prompts = list(map(apply_template, prompts))
outputs = model.generate(prompts, sampling_params)
print(outputs)
@article{liu2025understanding,
title={Understanding r1-zero-like training: A critical perspective},
author={Liu, Zichen and Chen, Changyu and Li, Wenjun and Qi, Penghui and Pang, Tianyu and Du, Chao and Lee, Wee Sun and Lin, Min},
journal={arXiv preprint arXiv:2503.20783},
year={2025}
}